LSI/LSA算法原理与实践Demo
- 目录:
- 1、使用场景
- 2、优缺点
- 3、算法原理
- 3.1、传统向量空间模型的缺陷
- 3.2、Latent Semantic Analysis (Latent Semantic Indexing)
- 3.3、算法实例
- 4、文档相似度的计算
- 5、对应的实践Demo
目录:
1、使用场景
文本挖掘中,主题模型。聚类算法关注于从样本特征的相似度方面将数据聚类。比如通过数据样本之间的欧式距离,曼哈顿距离的大小聚类等。而主题模型,顾名思义,就是对文字中隐含主题的一种建模方法。比如从“人民的名义”和“达康书记”这两个词我们很容易发现对应的文本有很大的主题相关度,但是如果通过词特征来聚类的话则很难找出,因为聚类方法不能考虑到到隐含的主题这一块。
那么如何找到隐含的主题呢?这个一个大问题。常用的方法一般都是基于统计学的生成方法。即假设以一定的概率选择了一个主题,然后以一定的概率选择当前主题的词。最后这些词组成了我们当前的文本。所有词的统计概率分布可以从语料库获得,具体如何以“一定的概率选择”,这就是各种具体的主题模型算法的任务了。当然还有一些不是基于统计的方法,比如我们下面讲到的LSI。
潜在语义索引(LSI),又称为潜在语义分析(LSA),主要是在解决两类问题,一类是一词多义,如“bank”一词,可以指银行,也可以指河岸;另一类是一义多词,即同义词问题,如“car”和“automobile”具有相同的含义,如果在检索的过程中,在计算这两类问题的相似性时,依靠余弦相似性的方法将不能很好的处理这样的问题。所以提出了潜在语义索引的方法,利用SVD降维的方法将词项和文本映射到一个新的空间。
2、优缺点
LSI是最早出现的主题模型了,它的算法原理很简单,一次奇异值分解就可以得到主题模型,同时解决词义的问题,非常漂亮。但是LSI有很多不足,导致它在当前实际的主题模型中已基本不再使用。
主要的问题有:
- SVD计算非常的耗时,尤其是我们的文本处理,词和文本数都是非常大的,对于这样的高维度矩阵做奇异值分解是非常难的。
- 主题值的选取对结果的影响非常大,很难选择合适的k值。
- LSI得到的不是一个概率模型,缺乏统计基础,结果难以直观的解释。
对于问题1,主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。对于问题2,这是老大难了,大部分主题模型的主题的个数选取一般都是凭经验的,较新的层次狄利克雷过程(HDP)可以自动选择主题个数。对于问题3,牛人们整出了pLSI(也叫pLSA)和隐含狄利克雷分布(LDA)这类基于概率分布的主题模型来替代基于矩阵分解的主题模型。
回到LSI本身,对于一些规模较小的问题,如果想快速粗粒度的找出一些主题分布的关系,则LSI是比较好的一个选择,其他时候,如果你需要使用主题模型,推荐使用LDA和HDP。
3、算法原理
3.1、传统向量空间模型的缺陷
向量空间模型是信息检索中最常用的检索方法,其检索过程是,将文档集D中的所有文档和查询都表示成以单词为特征的向量,特征值为每个单词的TF-IDF值,然后使用向量空间模型(亦即计算查询q的向量和每个文档di的向量之间的相似度)来衡量文档和查询之间的相似度,从而得到和给定查询最相关的文档。
向量空间模型简单的基于单词的出现与否以及TF-IDF等信息来进行检索,但是“说了或者写了哪些单词”和“真正想表达的意思”之间有很大的区别,其中两个重要的阻碍是单词的多义性(polysems)和同义性(synonymys)。多义性指的是一个单词可能有多个意思,比如Apple,既可以指水果苹果,也可以指苹果公司;而同义性指的是多个不同的词可能表示同样的意思,比如search和find。
同义词和多义词的存在使得单纯基于单词的检索方法(比如向量空间模型等)的检索精度受到很大影响。下面举例说明:
假设用户的查询为Q=”IDF in computer-based information look-up”
存在三篇文档Doc 1,Doc 2,Doc 3,其向量表示如下:

其中Table(i,j)=1表示文档i包含词语j。Table(i,j)=x表示该词语在查询Q中出现。Relevance如果为R表示该文档实际上和查询Q相关,Match为M表示根据基于单词的检索方法判断的文档和查询的相关性。
通过观察查询,我们知道用户实际上需要的是和“信息检索”相关的文档,文档1是和信息检索相关的,但是因为不包含查询Q中的词语,所以没有被检索到。实际上该文档包含的词语“retrieval”和查询Q中的“look-up”是同义词,基于单词的检索方法无法识别同义词,降低了检索的性能。而文档2虽然包含了查询中的”information”和”computer”两个词语,但是实际上该篇文档讲的是“信息论”(Information Theory),但是基于单词的检索方法无法识别多义词,所以把这篇实际不相关的文档标记为Match。
总而言之,在基于单词的检索方法中,同义词会降低检索算法的召回率(Recall),而多义词的存在会降低检索系统的准确率(Precision)。
3.2、Latent Semantic Analysis (Latent Semantic Indexing)
我们希望找到一种模型,能够捕获到单词之间的相关性。如果两个单词之间有很强的相关性,那么当一个单词出现时,往往意味着另一个单词也应该出现(同义词);反之,如果查询语句或者文档中的某个单词和其他单词的相关性都不大,那么这个词很可能表示的是另外一个意思(比如在讨论互联网的文章中,Apple更可能指的是Apple公司,而不是水果) 。
LSA(LSI)使用SVD来对单词-文档矩阵进行分解。SVD可以看作是从单词-文档矩阵中发现不相关的索引变量(因子),将原来的数据映射到语义空间内。在单词-文档矩阵中不相似的两个文档,可能在语义空间内比较相似。
SVD,亦即奇异值分解,是对矩阵进行分解的一种方法,一个t*d维的矩阵(单词-文档矩阵)X,可以分解为T*S*DT,其中T为t*m维矩阵,T中的每一列称为左奇异向量(left singular bector),S为m*m维对角矩阵,每个值称为奇异值(singular value),D为d*m维矩阵,D中的每一列称为右奇异向量。在对单词文档矩阵X做SVD分解之后,我们只保存S中最大的K个奇异值,以及T和D中对应的K个奇异向量,K个奇异值构成新的对角矩阵S’,K个左奇异向量和右奇异向量构成新的矩阵T’和D’:X’=T’*S’*D’T形成了一个新的t*d矩阵。
3.3、算法实例
这里举一个简单的LSI实例,假设我们有下面这个有11个词三个文本的词频TF对应矩阵如下:

这里我们没有使用预处理,也没有使用TF-IDF,在实际应用中最好使用预处理后的TF-IDF值矩阵作为输入。
我们假定对应的主题数为2,则通过SVD降维后得到的三矩阵为:

从矩阵Uk我们可以看到词和词义之间的相关性。而从Vk可以看到3个文本和两个主题的相关性。大家可以看到里面有负数,所以这样得到的相关度比较难解释。
4、文档相似度的计算
在上面我们通过LSI得到的文本主题矩阵即Vk可以用于文本相似度计算。而计算方法一般是通过余弦相似度。比如对于上面的三文档两主题的例子。我们可以计算第一个文本和第二个文本的余弦相似度如下 :

到这里也许你对整个过程也许还有点懵逼,为什么要用SVD分解,分解后得到的矩阵是什么含义呢?别着急下面将为你解答。
潜在语义索引(Latent Semantic Indexing)与PCA不太一样,至少不是实现了SVD就可以直接用的,不过LSI也是一个严重依赖于SVD的算法,之前吴军老师在矩阵计算与文本处理中的分类问题中谈到:
“三个矩阵有非常清楚的物理含义。第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。”
上面这段话可能不太容易理解,不过这就是LSI的精髓内容,我下面举一个例子来说明一下,下面的例子来自LSA tutorial,具体的网址我将在最后的引用中给出:
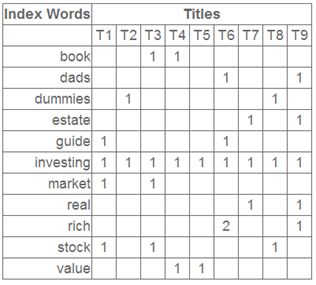
这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title(文档)中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:

左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到(如果对左奇异向量和右奇异向量单独投影的话也就代表相似的文档和相似的词):

在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
5、对应的实践Demo
import jieba
from gensim import corpora, models
from gensim.similarities import Similarity
jieba.load_userdict("userdict.txt")
stopwords = set(open('stopwords.txt',encoding='utf8').read().strip('\n').split('\n')) #读入停用词
raw_documents = [
'0无偿居间介绍买卖毒品的行为应如何定性',
'1吸毒男动态持有大量毒品的行为该如何认定',
'2如何区分是非法种植毒品原植物罪还是非法制造毒品罪',
'3为毒贩贩卖毒品提供帮助构成贩卖毒品罪',
'4将自己吸食的毒品原价转让给朋友吸食的行为该如何认定',
'5为获报酬帮人购买毒品的行为该如何认定',
'6毒贩出狱后再次够买毒品途中被抓的行为认定',
'7虚夸毒品功效劝人吸食毒品的行为该如何认定',
'8妻子下落不明丈夫又与他人登记结婚是否为无效婚姻',
'9一方未签字办理的结婚登记是否有效',
'10夫妻双方1990年按农村习俗举办婚礼没有结婚证 一方可否起诉离婚',
'11结婚前对方父母出资购买的住房写我们二人的名字有效吗',
'12身份证被别人冒用无法登记结婚怎么办?',
'13同居后又与他人登记结婚是否构成重婚罪',
'14未办登记只举办结婚仪式可起诉离婚吗',
'15同居多年未办理结婚登记,是否可以向法院起诉要求离婚'
]
corpora_documents = []
for item_text in raw_documents:
item_str = jieba.lcut(item_text)
print(item_str)
corpora_documents.append(item_str)
# print(corpora_documents)
# 生成字典和向量语料
dictionary = corpora.Dictionary(corpora_documents)
print("dictionary"+str(dictionary))
# dictionary.save('dict.txt') #保存生成的词典
# dictionary=Dictionary.load('dict.txt')#加载
# 通过下面一句得到语料中每一篇文档对应的稀疏向量(这里是bow向量)
corpus = [dictionary.doc2bow(text) for text in corpora_documents]
# 向量的每一个元素代表了一个word在这篇文档中出现的次数
print("corpus:"+str(corpus))
# corpora.MmCorpus.serialize('corpuse.mm',corpus)#保存生成的语料
# corpus=corpora.MmCorpus('corpuse.mm')#加载
# 测试数据
test_data_1 = '你好,我想问一下我想离婚他不想离,孩子他说不要,是六个月就自动生效离婚'
test_cut_raw_1 = jieba.lcut(test_data_1)
print(test_cut_raw_1)
#转化成tf-idf向量
# corpus是一个返回bow向量的迭代器。下面代码将完成对corpus中出现的每一个特征的IDF值的统计工作
tfidf_model=models.TfidfModel(corpus)
corpus_tfidf = [tfidf_model[doc] for doc in corpus]
print(corpus_tfidf)
'''''
#查看model中的内容
for item in corpus_tfidf:
print(item)
# tfidf.save("data.tfidf")
# tfidf = models.TfidfModel.load("data.tfidf")
# print(tfidf_model.dfs)
'''
#转化成lsi向量
# lsi= models.LsiModel(corpus_tfidf,id2word=dictionary,num_topics=50)
lsi= models.LsiModel(corpus_tfidf,id2word=dictionary,num_topics=50)
corpus_lsi = [lsi[doc] for doc in corpus]
print("corpus_lsi:"+str(corpus_lsi))
similarity_lsi=Similarity('Similarity-Lsi-index', corpus_lsi, num_features=400,num_best=5)
# 2.转换成bow向量 # [(51, 1), (59, 1)],即在字典的52和60的地方出现重复的字段,这个值可能会变化
test_corpus_3 = dictionary.doc2bow(test_cut_raw_1)
print(test_corpus_3)
# 3.计算tfidf值 # 根据之前训练生成的model,生成query的IFIDF值,然后进行相似度计算
test_corpus_tfidf_3 = tfidf_model[test_corpus_3]
print(test_corpus_tfidf_3) # [(51, 0.7071067811865475), (59, 0.7071067811865475)]
# 4.计算lsi值
test_corpus_lsi_3 = lsi[test_corpus_tfidf_3]
print(test_corpus_lsi_3)
# lsi.add_documents(test_corpus_lsi_3) #更新LSI的值
print('——————————————lsi———————————————')
# 返回最相似的样本材料,(index_of_document, similarity) tuples
print(similarity_lsi[test_corpus_lsi_3])
实验结果:

可以看到返回的相似语句ID为15,14,2等还是和原输入比较类似的。
参考:
https://www.cnblogs.com/kemaswill/archive/2013/04/17/3022100.html
https://www.cnblogs.com/pinard/p/6805861.html