Go语言自学笔记(八)
HTTP编程:
Web工作方式:通过HTTP协议
对于普通的上网过程,系统采用的操作流程:浏览器本身是一个客户端,当你输入URL的时候,首先浏览器回去请求DNS服务器,通过DNS获取相应的域名及对应的IP,然后通过IP地址找到IP对应的服务器后,要求建立TCP连接,等待浏览器发送完HTTP Request(请求)包后,服务器接收到请求包开始处理请求包,服务器调用自身服务,返回HTTP Response(响应)包;客户端收到来自服务器的响应后开始渲染这个Response包里的主体(body),等收到全部的内容随后断开与该服务器之间的TCP连接。
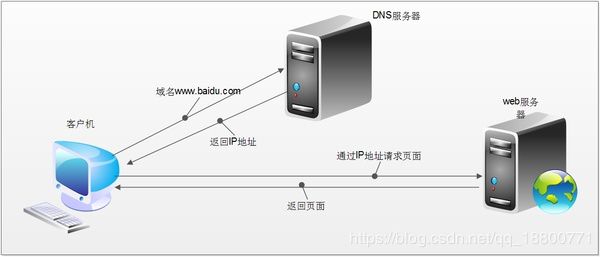
一个Web服务器也被称为HTTP服务器,它通过HTTP协议与客户端通信。这个客户端通常指的是Web浏览器(手机客户端内部也是浏览器实现的)。
Web服务器的工作原理可以简单地归纳为:
1.客户机通过TCP/IP协议建立到服务器的TCP连接
2.客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档
3.服务器向客户机发送HTTP协议应答包,如果求情的资源包包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理“动态内容”,并将处理得到的数据返回给客户端
4.客户机与服务器断开。由客户端解释HTML文档,在客户端屏幕上渲染图形结果
HTTP协议:
超文本传输协议(HTTP, HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议,它详细的规定了浏览器和玩味服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
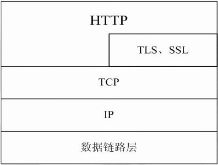
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层上,这个时候,就成了我们常说的HTTPS(加密)。
地址(URL,Uniform Resource Locator):用来表示网络资源,可以理解为网络文件路径。
URL格式如下:
http://host[":"port][abs_path]
http://192.168.31.1/html/index 协议:// 主机:端口 / 路径URL的长度有限制,不同的服务器的限制值不太相同,但是不能无限长。
请求包和响应包:
客户端向服务器发送的请求其实就是请求包,服务器回复给客户端的就是响应包。(HTTP)
HTTP服务器请求报文格式分析:需要导入包net
package main
import (
"fmt"
"net"
)
func main() {
//监听
listener, err := net.Listen("tcp", ":8000")
if err != nil {
fmt.Println("net.Listen err = ", err)
return
}
defer listener.Close()
//阻塞等待用户链接
conn, err1 := listener.Accept()
if err1 != nil {
fmt.Println("listener.Accept err = ", err1)
return
}
defer conn.Close()
//接受用户的请求
buf := make([]byte, 1024*4)
n, err2 := conn.Read(buf)
if n == 0 {
fmt.Println("conn.Read err = ", err2)
return
}
fmt.Printf("#%v#", string(buf[:n]))
}用户访问127.0.0.1:8000,服务器即可获取并打印请求包:

请求报文的格式:HTTP请求报文由请求行、请求头部、空行、请求包体4部分组成

#GET / HTTP/1.1 //此行为请求行,GET请求方式
Host: 127.0.0.1:8000 //此处一直到末尾空行之前为请求头
Connection: keep-alive //带有:的都属于键值对。每行末尾都是\r\n
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
//空行
# //包体(暂无)1.请求行:
请求行由方法字段、URL字段和HTTP协议版本字段3个部分组成,他们之间使用空格隔开。常用的HTTP请求方法有GET、POST。
请求方法有以下几种:
GET:从服务器获取一份文档
HEAD:只从服务器获取文档的首部
POST:向服务器发送需要处理的数据,常用于表单提交
PUT:将请求的主体部分存储在服务器上,从服务器上向客户发送文档
TRACE:对可能经过代理服务器传送到服务器上去的报文进行追踪
OPTIONS:决定可以在服务器上执行哪些方法
DELETE:从服务器上删除一份文档
GET:
1).当客户端要从服务器中读取某个资源时,使用GET方法。GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回给客户端,即向服务器请求某个资源。
2).使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制,因此GEY方法不适合用于上传数据。
3).通过GET方法来获取网页时,参数会显示在浏览器地址栏上,一次保密性很差。
POST:
1).当客户端给服务器提供信息较多时可以使用POST方法,POST方法向服务器提交数据,比如完成表单数据的提交,将数据提交给服务器处理。
2).GET一般用于获取/查询资源信息,POST会附带用户数据,一般用于更新资源信息。POST方法将请求参数封装在HTTP请求数据中,而且长度没有限制,因为POST携带的数据,在HTTP请求正文中,以名称/值的形式出现,可以传输大量数据。
2.请求头部:
请求头部为请求包未添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
请求头部通知服务器有关于客户端的信息,经典的请求头有:

3.空行:
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器一下不再有请求头。
4.请求包体:
请求包体不再GET方法中使用,而是在POST方法中使用。
POST方法适用于需要客户填写表单的场合。与请求包体相关的最常用的是包体类型Content-Type和包体长度Content-Length。
通过网址访问资源,如:127.0.0.1:8000/mike.html,服务器会接收到被请求的资源(#GET /mike.html HTTP/1.1)
客户端响应报文格式分析(组串发请求包):需要导入包net
测试服务器:打印hello world
package main
import(
"fmt"
"net/http"
)
//服务端编写的业务逻辑处理程序
func myHandler (w http.ResponseWriter, r *http.Request){
fmt.Fprintln(w, "hello world")
}
func main(){
http.HandleFunc("/go", myHandler)
//在指定的地址进行监听,开启一个HTTP
http.ListenAndServe("127.0.0.1:8000", nil)
}网址访问:127.0.0.1:8000/go
客户端代码:
package main
import (
"fmt"
"net"
)
func main() {
//主动连接服务器
conn, err := net.Dial("tcp", ":8000")
if err != nil {
fmt.Println("net.Dial err = ", err)
return
}
defer conn.Close()
requestBuf := "GET /go HTTP/1.1\r\nAccept: image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, application/x-ms-xbap, */*\r\nAccept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3\r\nUser-Agent: Mozilla/4.0 (compatoble; MSIE 7.0; Windows NT 10.0; Wow64;Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729)\r\nAccept-Encoding: gzip, deflate\r\nHost: 127.0.0.1:8000\r\nConnection: Keep-Alive\r\n\r\n"
//先发请求包,服务器才会回应包
conn.Write([]byte(requestBuf))
//接收服务器回复的响应包
buf := make([]byte, 1024*4)
n, err1 := conn.Read(buf)
if n == 0 {
fmt.Println("conn.Read err = ", err1)
return
}
//打印响应报文
fmt.Printf("#%v#", string(buf[:n]))
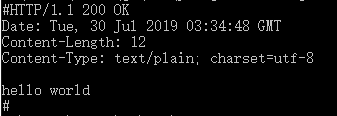
}服务器成功响应:
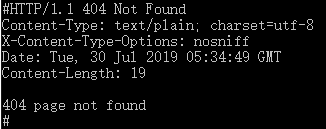
服务器响应失败:
响应报文格式:HTTP响应报文由状态行、响应头部、空行、响应包体四个部分组成

#HTTP/1.1 200 OK //状态行
Date: Tue, 30 Jul 2019 03:34:48 GMT //响应头部
Content-Length: 12
Content-Type: text/plain; charset=utf-8
//空行
hello world //响应包体
#1.状态行:
状态行由HTTP协议版本字段、状态码和状态吗的描述文本3各部分组成,他们之间使用空格隔开。
状态码:
状态码由三位数字组成,第一位数字表示响应的类型,常用的状态码有五大类:

常见的状态码举例:
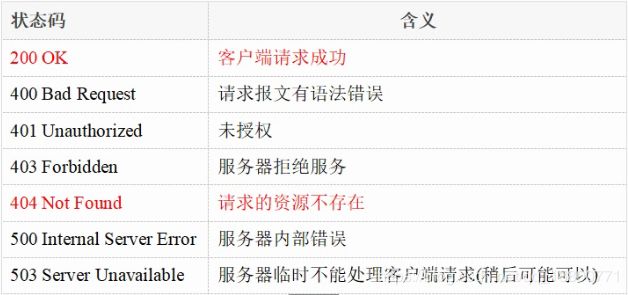
2.响应头部:
响应头部可能包括:


3.空行:
最后一个响应头部之后是一个空行,发送回车符和换行符,通知服务器以下不再有响应头部。
4.响应包体:
服务器返回给客户端的文本信息。
HTTP get和post区别:
1.提交:
GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头<request-line>中),以?分割URL和传输数据,多个参数用&连接;例如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体<request-body>中。上文示例中红色字体标明的就是实际的传输数据。因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
2.传输数据的大小:
首先声明,HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。 而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
3.安全性:
POST的安全性要比GET的安全性高。
注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存, (2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了。
HTTP编程:
Go语言标准库内建提供了net/http包,涵盖了HTTP客户端和服务端的具体表现。使用net/http包,我们可以很方便地编写HTTP客户端或服务端的程序。
HTTP服务器:
package main
import (
"net/http"
)
//w, 给客户端恢复数据
//req, 读取客户端发送的数据
func HandConn(w http.ResponseWriter, req *http.Request) {
w.Write([]byte("hello go")) //给客户端回复数据
}
func main() {
//注册处理函数,用户连接,自动调用指定的处理函数
http.HandleFunc("/", HandConn) //此时通过127.0.0.1:8000访问,引号内若是/mike.html 则需要通过127.0.0.1:8000/mike.html访问,
//监听绑定
http.ListenAndServe(":8000", nil)
}
HTTP服务器获取客户端信息:
package main
import (
"net/http"
"fmt"
)
//w, 给客户端恢复数据
//r, 读取客户端发送的数据
func HandConn(w http.ResponseWriter, req *http.Request) {
fmt.Println(r.Method) //获取客户端请求方法
fmt.Println(r.URL) //获取地址
fmt.Println(r.Herder) //获取头部信息
fmt.Println(r.Body) //body为空
w.Write([]byte("hello go")) //给客户端回复数据
}
func main() {
//注册处理函数,用户连接,自动调用指定的处理函数
http.HandleFunc("/", HandConn) //引号内若是/mike.html 则需要通过127.0.0.1:8000/mike.html访问
//监听绑定
http.ListenAndServe(":8000", nil)
}HTTP客户端:
package main
import (
"fmt"
"net/http"
)
func main() {
resp, err := http.Get("http://www.baidu.com") //返回的resp是一个结构体,可以在studygolang.com/pkgdoc查看详细内容.百度内容过多可测http://127.0.0.1:8000
if err != nil {
fmt.Println("http.Get err = ", err)
return
}
defer resp.Body.Close()
fmt.Println("Status = ", resp.Status) //打印状态
fmt.Println("StatusCode = ", resp.StatusCode) //打印状态码
fmt.Println("Header = ", resp.Header) //打印头部信息
fmt.Println("Body = ", resp.Body) //打印Body(io流)
//读取ioBody
buf := make([]byte, 4*1024)
var tmp string
for {
n, err := resp.Body.Read(buf)
if n == 0 {
fmt.Println("Read err = ", err)
break
}
tmp += string(buf[:n])
}
fmt.Println("tmp = ", tmp)
}HTTP爬虫:
爬虫的四个主要步骤:
1.明确目标:要知道在哪个范围或网站搜索内容
2.爬:将所有的网站内容全部爬下来
3.取:过滤掉没有用的数据
4.处理数据:以想要的方式储存和使用
爬虫案例:百度贴吧
以GO语言吧为例:
1.明确目标
第一页:http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=0
第二页:http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=50
第三页:http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=100
可知每向下翻一页末尾的数字就会+50(第一页从0开始)
(先不做数据过滤)
单任务爬虫:
package main
import (
"fmt"
"net/http"
"os"
"strconv" //转换
)
//爬取网页内容
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url)
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页body内容
buf := make([]byte, 1024*4)
for {
n, err := resp.Body.Read(buf)
if n == 0 {
fmt.Println("resp.Body.Read err = ", err)
break
}
result += string(buf[:n])
}
return
}
func DoWork(start, end int) {
fmt.Printf("正在爬取 %d 到 %d 页面数据\n", start, end)
//明确目标(要知道在哪个范围或网站搜索内容)
//http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=0 下一页+50
for i := start; i <= end; i++ {
url := "http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=" + strconv.Itoa((i-1)*50)
fmt.Println("url = ", url)
//爬(将所有的网站内容全部爬下来)
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
continue
}
//把内容写入到文件
fileName := strconv.Itoa(i) + ".html"
f, err1 := os.Create(fileName)
if err1 != nil {
fmt.Println("os.Create err = ", err1)
continue
}
f.WriteString(result) //写入内容
f.Close() //关闭文件
}
}
func main() {
var start, end int
fmt.Println("请输入起始页(>=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end)
}并发任务爬虫:并发时间优势强烈体现
package main
import (
"fmt"
"net/http"
"os"
"strconv" //转换
)
//爬取网页内容
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url)
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页body内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n])
}
return
}
//爬取网页
func SpiderPape(i int, page chan<- int) {
url := "http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=" + strconv.Itoa((i-1)*50)
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//爬(将所有的网站内容全部爬下来)
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//把内容写入到文件
fileName := strconv.Itoa(i) + ".html"
f, err1 := os.Create(fileName)
if err1 != nil {
fmt.Println("os.Create err = ", err1)
return
}
f.WriteString(result) //写入内容
f.Close() //关闭文件
page <- i
}
func DoWork(start, end int) {
fmt.Printf("正在爬取 %d 到 %d 页面数据\n", start, end)
page := make(chan int)
//明确目标(要知道在哪个范围或网站搜索内容)
//http://tieba.baidu.com/f?kw=go%E8%AF%AD%E8%A8%80&ie=utf-8&pn=0 下一页+50
for i := start; i <= end; i++ {
go SpiderPape(i, page)
}
for i := start; i <= end; i++ {
fmt.Printf("页面%d爬取完成\n", <-page)
}
}
func main() {
var start, end int
fmt.Println("请输入起始页(>=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end)
}
爬虫案例:段子
以捧腹网为例:
1.明确目标:
第一页:https://www.pengfu.com/xiaohua_1.html
第二页:https://www.pengfu.com/xiaohua_2.html
第三页:https://www.pengfu.com/xiaohua_3.html
可知每向下翻一页,末尾数字+1
主页规律:
通过查看网页源代码我们可以发现每一个段子的标题格式:
系统维护的时候
标题格式中包含的网址则是每一个段子单独的详细的链接。
包含十个类似的标题格式以
段子URL规律:
进入此链接通过查看网页源代码可以发现网页源代码总共包含两个
:
通过观察我们发现第一个
后面包含我们想要的信息:段子的标题和段子的内容。
段子的标题以
开头,以
结尾,可以过滤内容。只取第一个开头到结尾。
段子的内容以
开头,以package main
import (
"fmt"
"net/http"
"regexp"
"strconv"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
func SpiderPape(i int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
第二部代码:取出并输出标题和内容
package main
import (
"fmt"
"net/http"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
//开始爬取每一个段子
func SpiderOneJoy(url string) (title, content string, err error) {
//开始爬取段子信息
result, err1 := HttpGet(url)
if err1 != nil {
//fmt.Println("HttpGet err = ", err1)
err = err1
return
}
//取关键信息
//取标题,标题以开头,以
结尾,
re1 := regexp.MustCompile(`(?s:(.*?))
`)
if re1 == nil {
//fmt.Println("regexp.MustCompile err ")
err = fmt.Errorf("%s", "regexp.MustCompile err")
return
}
//取内容
tmpTitle := re1.FindAllStringSubmatch(result, 1) //只过滤第一个
for _, data := range tmpTitle {
title = data[1]
//title = strings.Replace(title, "\r", "", -1)
//title = strings.Replace(title, "\n", "", -1)
//title = strings.Replace(title, " ", "", -1)
title = strings.Replace(title, "\t ", "", -1) //剔除干扰字符换成空字符
break
}
//取内容,内容以开头,以(?s:(.*?))", "", -1)
break
}
return
}
func SpiderPape(i int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
第三步代码:输出到文件
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
//开始爬取每一个段子
func SpiderOneJoy(url string) (title, content string, err error) {
//开始爬取段子信息
result, err1 := HttpGet(url)
if err1 != nil {
//fmt.Println("HttpGet err = ", err1)
err = err1
return
}
//取关键信息
//取标题,标题以开头,以
结尾,
re1 := regexp.MustCompile(`(?s:(.*?))
`)
if re1 == nil {
//fmt.Println("regexp.MustCompile err ")
err = fmt.Errorf("%s", "regexp.MustCompile err")
return
}
//取内容
tmpTitle := re1.FindAllStringSubmatch(result, 1) //只过滤第一个
for _, data := range tmpTitle {
title = data[1]
//title = strings.Replace(title, "\r", "", -1)
//title = strings.Replace(title, "\n", "", -1)
//title = strings.Replace(title, " ", "", -1)
title = strings.Replace(title, "\t ", "", -1) //剔除干扰字符换成空字符
break
}
//取内容,内容以开头,以(?s:(.*?))", "", -1)
break
}
return
}
//把内容写入到文件
func StoreJoyToFile(i int, fileTitle []string, fileContent []string) {
//新建文件
f, err := os.Create(strconv.Itoa(i) + ".txt")
if err != nil {
fmt.Println("os.Create err = ", err)
return
}
defer f.Close()
//写内容
n := len(fileTitle)
for i := 0; i < n; i++ {
//写标题
f.WriteString(fileTitle[i] + "\n")
//写内容
f.WriteString(fileContent[i] + "\n")
f.WriteString("\n-----------------------------------\n")
}
}
func SpiderPape(i int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
并发爬虫:速度优势
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
//开始爬取每一个段子
func SpiderOneJoy(url string) (title, content string, err error) {
//开始爬取段子信息
result, err1 := HttpGet(url)
if err1 != nil {
//fmt.Println("HttpGet err = ", err1)
err = err1
return
}
//取关键信息
//取标题,标题以开头,以
结尾,
re1 := regexp.MustCompile(`(?s:(.*?))
`)
if re1 == nil {
//fmt.Println("regexp.MustCompile err ")
err = fmt.Errorf("%s", "regexp.MustCompile err")
return
}
//取内容
tmpTitle := re1.FindAllStringSubmatch(result, 1) //只过滤第一个
for _, data := range tmpTitle {
title = data[1]
//title = strings.Replace(title, "\r", "", -1)
//title = strings.Replace(title, "\n", "", -1)
//title = strings.Replace(title, " ", "", -1)
title = strings.Replace(title, "\t ", "", -1) //剔除干扰字符换成空字符
break
}
//取内容,内容以开头,以(?s:(.*?))", "", -1)
break
}
return
}
//把内容写入到文件
func StoreJoyToFile(i int, fileTitle []string, fileContent []string) {
//新建文件
f, err := os.Create(strconv.Itoa(i) + ".txt")
if err != nil {
fmt.Println("os.Create err = ", err)
return
}
defer f.Close()
//写内容
n := len(fileTitle)
for i := 0; i < n; i++ {
//写标题
f.WriteString(fileTitle[i] + "\n")
//写内容
f.WriteString(fileContent[i] + "\n")
f.WriteString("\n-----------------------------------\n")
}
}
func SpiderPape(i int, page chan int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
捧腹网可能存在服务器不稳定的情况,若出现panic: runtime error: invalid memory address or nil pointer dereference错误,则很有可能是由于网络或服务器原因。
Go语言基础学习部分就到此为止了,可视化程序部分(含两篇笔记)暂不做学习。
package main
import (
"fmt"
"net/http"
"regexp"
"strconv"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
func SpiderPape(i int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
第二部代码:取出并输出标题和内容
package main
import (
"fmt"
"net/http"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
//开始爬取每一个段子
func SpiderOneJoy(url string) (title, content string, err error) {
//开始爬取段子信息
result, err1 := HttpGet(url)
if err1 != nil {
//fmt.Println("HttpGet err = ", err1)
err = err1
return
}
//取关键信息
//取标题,标题以开头,以
结尾,
re1 := regexp.MustCompile(`(?s:(.*?))
`)
if re1 == nil {
//fmt.Println("regexp.MustCompile err ")
err = fmt.Errorf("%s", "regexp.MustCompile err")
return
}
//取内容
tmpTitle := re1.FindAllStringSubmatch(result, 1) //只过滤第一个
for _, data := range tmpTitle {
title = data[1]
//title = strings.Replace(title, "\r", "", -1)
//title = strings.Replace(title, "\n", "", -1)
//title = strings.Replace(title, " ", "", -1)
title = strings.Replace(title, "\t ", "", -1) //剔除干扰字符换成空字符
break
}
//取内容,内容以开头,以(?s:(.*?))", "", -1)
break
}
return
}
func SpiderPape(i int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
第三步代码:输出到文件
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
//开始爬取每一个段子
func SpiderOneJoy(url string) (title, content string, err error) {
//开始爬取段子信息
result, err1 := HttpGet(url)
if err1 != nil {
//fmt.Println("HttpGet err = ", err1)
err = err1
return
}
//取关键信息
//取标题,标题以开头,以
结尾,
re1 := regexp.MustCompile(`(?s:(.*?))
`)
if re1 == nil {
//fmt.Println("regexp.MustCompile err ")
err = fmt.Errorf("%s", "regexp.MustCompile err")
return
}
//取内容
tmpTitle := re1.FindAllStringSubmatch(result, 1) //只过滤第一个
for _, data := range tmpTitle {
title = data[1]
//title = strings.Replace(title, "\r", "", -1)
//title = strings.Replace(title, "\n", "", -1)
//title = strings.Replace(title, " ", "", -1)
title = strings.Replace(title, "\t ", "", -1) //剔除干扰字符换成空字符
break
}
//取内容,内容以开头,以(?s:(.*?))", "", -1)
break
}
return
}
//把内容写入到文件
func StoreJoyToFile(i int, fileTitle []string, fileContent []string) {
//新建文件
f, err := os.Create(strconv.Itoa(i) + ".txt")
if err != nil {
fmt.Println("os.Create err = ", err)
return
}
defer f.Close()
//写内容
n := len(fileTitle)
for i := 0; i < n; i++ {
//写标题
f.WriteString(fileTitle[i] + "\n")
//写内容
f.WriteString(fileContent[i] + "\n")
f.WriteString("\n-----------------------------------\n")
}
}
func SpiderPape(i int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
并发爬虫:速度优势
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url) //发送get请求
if err != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n]) //累加读取内容
}
return
}
//开始爬取每一个段子
func SpiderOneJoy(url string) (title, content string, err error) {
//开始爬取段子信息
result, err1 := HttpGet(url)
if err1 != nil {
//fmt.Println("HttpGet err = ", err1)
err = err1
return
}
//取关键信息
//取标题,标题以开头,以
结尾,
re1 := regexp.MustCompile(`(?s:(.*?))
`)
if re1 == nil {
//fmt.Println("regexp.MustCompile err ")
err = fmt.Errorf("%s", "regexp.MustCompile err")
return
}
//取内容
tmpTitle := re1.FindAllStringSubmatch(result, 1) //只过滤第一个
for _, data := range tmpTitle {
title = data[1]
//title = strings.Replace(title, "\r", "", -1)
//title = strings.Replace(title, "\n", "", -1)
//title = strings.Replace(title, " ", "", -1)
title = strings.Replace(title, "\t ", "", -1) //剔除干扰字符换成空字符
break
}
//取内容,内容以开头,以(?s:(.*?))", "", -1)
break
}
return
}
//把内容写入到文件
func StoreJoyToFile(i int, fileTitle []string, fileContent []string) {
//新建文件
f, err := os.Create(strconv.Itoa(i) + ".txt")
if err != nil {
fmt.Println("os.Create err = ", err)
return
}
defer f.Close()
//写内容
n := len(fileTitle)
for i := 0; i < n; i++ {
//写标题
f.WriteString(fileTitle[i] + "\n")
//写内容
f.WriteString(fileContent[i] + "\n")
f.WriteString("\n-----------------------------------\n")
}
}
func SpiderPape(i int, page chan int) {
//明确需要爬取的url
//https://www.pengfu.com/xiaohua_1.html
url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(i) + ".html"
fmt.Printf("正在爬取网页%d:%s\n", i, url)
//开始爬取主页的链接
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet err = ", err)
return
}
//fmt.Println(result)
//取url链接-正则表达式,以=1)")
fmt.Scan(&start)
fmt.Println("请输入起始页(>=起始页)")
fmt.Scan(&end)
DoWork(start, end) //工作函数
}
捧腹网可能存在服务器不稳定的情况,若出现panic: runtime error: invalid memory address or nil pointer dereference错误,则很有可能是由于网络或服务器原因。
Go语言基础学习部分就到此为止了,可视化程序部分(含两篇笔记)暂不做学习。