Golang学习手册
Golang 基础
- 第一章:Golang的安装和开发工具配置
-
- 1.1 安装
- 1.2 vscode插件安装失败解决方法
- 1.3 新建项目,编译文件
- 1.4 Go语言开发工具Vscode配置
- 第二章:GoLang 定义变量、 fmt包、Println、Printf、Go语言注释
-
- 2.1. 变量声明和定义
-
- 变量声明
- 变量定义
- 变量初始化
- 2.2. fmt包打印输出
-
- Print、Println、Printf
- 2.3. Go语言中的注释
-
- 单行注释
- 多行注释
- 2.4. 变量的来历
- 2.5. 变量的类型
- 2.7. Go语言中的常量
- 2.8. Go语言变量、常量命名规则
- 2.9. Go语言代码风格
- 第三章:基本数据类型和复合类型
-
- 3.1. 整数类型(int)
- 3.2. 浮点数(float)
- 3.3. 布尔类型(bool)
- 3.4. 字符串和字符串里面的方法(string)
- 3.5. byte 和 rune类型
- 3.6. 基本数据类型之间的转换
-
- 3.6.1 关于golang中的数据类型转换
- 3.6.2 数值类型之间的相互转换
- 3.6.3 其他类型转换成String类型
- 3.6.4 String类型转换成数值类型
- 3.6.5 数值类型没法和bool类型进行转换(尽量不使用)
- 3.7 数组
- 3.8 切片
-
- 切片的声明
- 切片的循环遍历
- 基于数组来定义切片
- 切片的长度和容量
- 使用make()函数构造切片
- 使用append()添加元素,合并多个切片
- 切片的扩容策略
- 切片为引用数据类型
- copy()函数复制切片
- 从切片中删除元素
- 切片的常用算法:选择排序,冒泡排序
-
- 1. 选择排序
- 2. 冒泡排序
- 3. 内置Sort包对切片进行排序
- 3.9 map
-
- map的定义
- 循环遍历map数据
- map数据类型的curd(增删改查)
- 基于map的切片
- map类型的值定义为切片
- 对map的key进行升序排序输出
- 3.10 结构体
-
- 自定义类型
- 类型别名
- 结构体的定义
- 结构体初始化多种方法
- 结构体为值类型
- 结构体方法
- 结构体切片
- 结构体的匿名字段
- 结构体嵌套或继承
- 结构体和Json相互转换 序列化 反序列化
-
- 关于JSON 数据
- 序列化:把结构体转成JSON字符串
- 反序列化:把JSON数据转换为结构体数据
- 结构体标签Tag
- 复杂的结构体转json,在项目中经常使用
- 3.11 通道(channel)
- 3.12 接口
- 第四章:运算符
-
-
- 4.1 算术运算符( +, -, *, /, % )
- 4.2 关系运算符( >, < ,=>, <=)
- 4.3 逻辑运算符( &&, || , ! )
- 4.4 赋值运算符 ( = , +=, -=, *=, /=, %= )
- 4.5 运算符的几个练习 位运算符
-
- 第五章:流程控制和循环语句
-
- 5.1 流程控制 if else for的基本使用
- 5.2 流程控制 for range swirch case
- 5.3 流程控制 continue break goto
- 5.4 数组的循环遍历
- 5.5 多维数组 值类型 引用类型
- 第六章:函数详解
-
- 6.1 函数定义、函数参数、函数返回值
-
- 函数定义
- 函数参数
- 函数返回值
- 6.2 map当做函数参数
-
- 函数变量作用域
- 6.3 函数类型
-
- 函数类型定义
- 函数作为参数
- 函数作为返回值
- 匿名函数
- 函数递归
- 闭包
- 6.5 defer panic recover
-
- 6.5.1 defer 语句
- 区分defer和return语句的先后顺序
- panic抛出异常 recover接收异常
- panic, recover案例
- 第七章:指针详解 、make new方法分配内存
-
- 关于指针
- 看图理解普通变量和指针的关系
- 指针地址和指针类型
-
- 取变量指针语法:
- 取指针的值(和C,C++ 一样的语法)
- 引用类型必须要分配空间
-
- 切片和map中的分配空间
- 指针也是引用数据类型
- new函数分配内存
- make函数分配内存
- 第八章:Golang 中的 go mod 以及 Golang 包详解
-
- 8.1 go mod 详解
-
- go mod 使用
- 自定义包
- 包的init()函数
- 第三方包详解
-
- 查看地址
- 安装第三方包
- 第九章:接口详解
-
- 9.1 接口介绍
- 9.2 接口定义
- 9.3 实现接口
- 9.4 空接口
- 9.5 类型断言
- 9.6 结构体实现多接口、接口嵌套、结构体指针接收者实现接口
- 9.7 空接口和类型断言使用细节-类型断言输出空接口类型结构体属性
- 第十章:goroutine channel实现并发和并行
-
- 关于进程和线程
-
- 进程
- 线程
- 10.1 并发和并行
- sync.WaitGroup 协程等待
- 设置并行运行时占用的CPU数量, runtime包
- 通过循环开启协程
- channel管道
-
- channel 类型
- 创建channel
- 操作channel
- 管道是引用数据类型
- 管道阻塞
-
- 写死锁
- 读死锁
- 解决管道阻塞后死锁问题
- 管道循环遍历
- goroutine结合Channel管道
- 10.2 单向管道
- select多路复用
- goroutine panic处理
- 10.3 goroutine 互斥锁 读写互斥锁
-
- 互斥锁
- 列子
- 读写互斥锁
- 第十一章:反射
- 第十二章:文件目录操作
第一章:Golang的安装和开发工具配置
1.1 安装
- 非常简单,直接默认安装就行,从官网下载直接安装,官网下载地址:
https://golang.google.cn; - 查看是否安装成功,cmd下运行命令:
go version
能正确显示go版本号就说明安装成功
- 查看go语言的环境变量
go env
以前老的版本是用配置环境变量,大于1.13版本后的就不需要配置,都是通过
go mod生成的依赖包来管理项目,也不需要非得把项目放到GOPATH指定的目录下,你可以在你磁盘任意地方新建一个项目
1.2 vscode插件安装失败解决方法
- 由于墙的原因,很多第三方库无法访问按照,需要配置环境变量来设置代理,在命令行下:
go env // 查看环境变量的值
go env -w GO111MODULE=on // 使 通过 go mod 管理生效
go env -w GOPROXY=https://goproxy.cn,direct // 设置代理网站,国内的可以访问
1.3 新建项目,编译文件
- 在
d:\golang下面新建的项目文件夹,每个文件夹属于一个项目
// d:\golang
mkdir firstDemo
cd firstDemo
// 通过go mod 来管理
go mod init firstDemo
// 会在当前下面生成go.mod 文件,用于管理第三方包的依赖文件
- 在
firstDemo目录下面新建main.go文件,也可以是其他名字,以.go结尾, 编辑为如下内容
package main
import (
"fmt"
)
func main() {
fmt.Println("hello world")
}
- 编译运行
go run main.go
就可以查看文件输出的内容;
- 程序打包
go build main.go
会在当前目录下面生成一个main.exe可执行文件
1.4 Go语言开发工具Vscode配置
第二章:GoLang 定义变量、 fmt包、Println、Printf、Go语言注释
2.1. 变量声明和定义
变量声明
var 变量名 类型
变量定义
- 通过 关键字
var声明var 变量名 类型 - 通过类型推导方式
变量名 := 值(只能在函数内部使用) - 基本数据类型都有自己的默认初始化方式
var 变量名 类型 = 值
变量名 := 值
变量初始化
- 基本数据类型都有自己的默认初始化方式, int 默认初始化为0,string默认初始化为空字符串
var num int // 默认初始化为0
var i int = 10 // 显示的初始化
- 一次性声明多个变量
var (
username string
age int
sex bool
)
// 或者
var (
user = "zzz"
age = 20;
)
// 可以是不同的类型
a, b, c = 12, 20, "long"
2.2. fmt包打印输出
Print、Println、Printf
fmt.Println("test") // 有换行
fmt.Println("A","B","C") // 如果同时输出几个值,相邻的值会有空格
fmt.Print("test") // 没有换行
fmt.Print("A","B","C") // 相邻几个值没有空格
fmt.Printf("test") // 没有换行,换行 需要后面加 \n
var a = "aaa"
fmt.Printfln(a)
// 格式化输出, %c, %T, %t, %f
fmt.Printf("%v", a);
2.3. Go语言中的注释
单行注释
// 单行注释的内容
多行注释
/*
多行注释的内容
多行注释的内容
*/
2.4. 变量的来历
2.5. 变量的类型
- 变量的类型就是所指向的内容数据类型
- 匿名变量
_, 当该变量不需要使用的时候使用
func getUser() (string, int) {
return "name", 20
}
func main() {
var _, age = getUser()
fmt.Println(age)
}
2.7. Go语言中的常量
const代替var, 就是常量
2.8. Go语言变量、常量命名规则
- 变量的名称:由字母,数字,下划线组成,其中首个字母不能为数字。
2.9. Go语言代码风格
- go语言区分大小写
- 函数的
{必须要和函数名在同一行;
第三章:基本数据类型和复合类型
3.1. 整数类型(int)
// 1. 定义int类型
var num int = 10
fmt.Printf("num = %v, type: %T", num, num) // num = 10, type: int
- 下面为int的范围
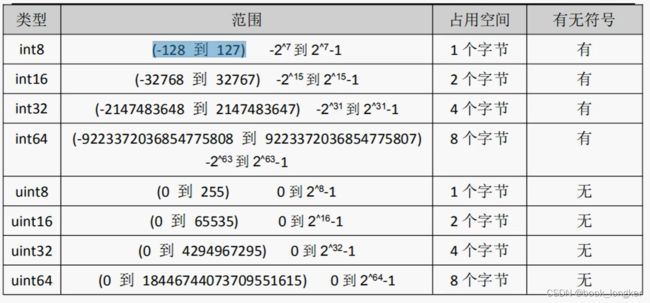
3.2. 浮点数(float)
3.3. 布尔类型(bool)
3.4. 字符串和字符串里面的方法(string)
- 字符串转义符
| 转义符 | 含义 |
|---|---|
| \r | 回车符,返回行首 |
| \n | 换行符,直接跳到下一行的同列位置 |
| \t | 制表符 |
| ’ | 单引号 |
| " | 双引号 |
| |反斜杠 | |
| 举例:当我们打印一个windows平台的路径时: |
str := "d:\\webserver\\"
fmt.Println(str) // d:\webserver\
- 定义多行字符串,使用反引号 ``
func main() {
str := `
this is
book very
good!!`
fmt.Println(str)
- 字符串的常用操作, 需要用到系统包
strings
| 方法 | 说明 |
|---|---|
| len(str) | 求长度 |
| + 或 fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix, strings.HasSuffix | 前缀/ 后缀判断 |
| strings.Index(), strings.LastIndex() | 子串出现的位置, 查找不到返回-1,否则返回位置pos |
| strings.Join(a[]string, sep string) | join操作 |
import (
"fmt"
"strings"
)
func main() {
str := "hello"
// len 求字符串长度
fmt.Println(len(str)); // 5
str2 := " world"
// + , fmt.Sprintf合并字符串
str3 := str + str2
fmt.Println(str3) // hello world
str4 := fmt.Sprintf("%v%v", str, str2)
fmt.Println(str4) // hello world
// 分割字符串 用到了strings 包
var str5 = "123-456-789"
arr := strings.Split(str5, "-")
fmt.Println(arr) // [123 456 789]
fmt.Println(arr[0]) //123
// 把切片链接成一个字符串
str6 := strings.Join(arr, "/")
fmt.Println(str6) // 123/456/789
// 判断字符串是否包含
s := "this is a book"
ret := strings.Contains(s, "book")
fmt.Println(ret) // true
// strings.HasPrefix, strings.HasSuffix | 前缀/ 后缀判断
str11 := "file.txt"
str22 := "file"
flag := strings.HasPrefix(str11, str22)
fmt.Println(flag) // true
flag = strings.HasSuffix(str11, ".txt")
fmt.Println(flag) // true
}
3.5. byte 和 rune类型
- golang中定义的字符,字符属于int类型
func main() {
var a = 'a'
fmt.Printf("值: %v, 类型: %T\n", a, a) // 值: 97, 类型: int32
// 原样输出字符
fmt.Printf("值: %c, 类型: %T\n", a, a) // 值: a, 类型: int32
// 定义一个字符串,输出字符串里面的字符
var str = "this"
fmt.Printf("值: %v, 类型: %T\n", str[2], str[2]) // 值: 105, 类型: uint8
// 一个汉字占用3个字节(utf-8),一个字母占用一个字节
var s = "this"
fmt.Println(unsafe.Sizeof(s)) //16 不能用它来获取string类型的占有的存储空间
fmt.Println(len(s)) // 4
// 汉字使用的是utf-8 编码
var b = '国'
fmt.Printf("值: %v, 类型: %T\n", b, b) // 值: 22269, 类型: int32
// 通过循环输出字符串中的字符,如果有中文的话
s = "你好 golang"
// 1. 通过for , 输出的类型为byte
for i := 0; i < len(s); i++ {
fmt.Printf("%v(%c)", s[i], s[i]) // 228(ä)189(½)160( )229(å)165(¥)189(½)32( )103(g)111(o)108(l)97(a)110(n)103(g)
}
// 2 通过 for range 输出的类型为rune,可以显示中文
for _, v := range s {
fmt.Printf("%v(%c)", v, v) // 20320(你)22909(好)32( )103(g)111(o)108(l)97(a)110(n)103(g)
}
}
- Go语言中的字符有以下两种:
- uint8类型,或者叫
byte类型,代表了ASCII码的一个字符 - rune类型,代表一个 UTF-8 字符,当需要处理中文,或者其他符合字符时,则需要rune类型,rune类型实际是一个int32
- 修改字符串
- 要修改字符串,需要先将其转换成[]rune 或 []byte,完成后在转换为string,无论哪种转换,都会重新分配内存,并复制字节数组
s1 := "big"
// s1[0] = 'p' 不能这样修改
// 强制类型转换
byte1 := []byte(s1)
byte1[0] = 'p'
fmt.Println(string(byte1)) // pig
s2 := "你好中国"
rune1 := []rune(s2)
rune1[2] = '大'
fmt.Println(string(rune1)) // 你好大国
3.6. 基本数据类型之间的转换
3.6.1 关于golang中的数据类型转换
- 整形转换
int() - float()
3.6.2 数值类型之间的相互转换
3.6.3 其他类型转换成String类型
- 其他类型转换为string
- 通过fmt.Sprintf()
var i int = 10
str := fmt.Sprintf("%d", i)
fmt.Printf("%v, %T", str, str) //10 string
- 使用`strconv`包里面的几种转换
var i int = 10
/*
FormatInt
参数1:int64的数值
参数2:进制
*/
str1 := strconv.FormatInt(int64(i), 10)
fmt.Printf("%v, %T", str1, str1) // 10, string
var f float32 = 20.1111
str2 := strconv.FormatFloat(float64(f),'f', 4, 32)
fmt.Printf("%v, %T", str2, str2) // 20.1111, string
3.6.4 String类型转换成数值类型
var s = "20"
num, _ := strconv.ParseInt(s, 10, 32)
fmt.Printf("%v, %T\n", num,num) // 20, int64
3.6.5 数值类型没法和bool类型进行转换(尽量不使用)
3.7 数组
数组是指一系列同一类型数据的集合
- 数组的声明:
var 数组变量名 [元素数量]类型
比如:
var a [10]int数组的长度必须是常量,并且长度是数组类型的一部分。一旦定义,不能修改
- 数组的初始化 几种方式
// int默认初始化为0, string为空
var arr1 [3]int
fmt.Println(arr1) // [0 0 0]
// 1. 数组的初始化
var arr2 [3]int
arr2[0] = 1
arr2[1] = 2
arr2[2] = 3
fmt.Println(arr2) // [1 2 3]
// 2. 数组的初始化
var arr3 = [3]int{1,2,3}
fmt.Println(arr3) // [1 2 3]
// 3. 数组的初始化, 自动推断数组的长度
var arr4 = [...]int {1,2,3,4,5}
fmt.Printf("值:%v, 长度:%v", arr4, len(arr4)) // 值:[1 2 3 4 5], 长度:5
// 4. 数组的初始化,索引的方式
arr5 := [...]int{0: 1, 1: 10, 2: 20}
fmt.Println(arr5) // [1 10 20]
- 数组的遍历 for, for range 二种方式
var arr = [...]int{1, 2, 3, 4, 5}
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}
for _, v := range arr {
fmt.Println(v)
}
- 数组是值类型(基本数据类型也是值类型),赋值和传参会复制整个数组,因此改变副本的值,不会改变本身的值
- 多维数组
var arr = [3][2]string{{"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}}
// var arr = [..][2]string{{"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}}
arr[0][0] // 北京
/*
[北京 上海]
[广州 深圳]
[成都 重庆]
*/
for _, v := range arr {
fmt.Println(v)
}
3.8 切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容
切片是一个引用类型,它的内部结构包含地址,长度和容量
切片的声明
var name []T
其中name为变量名,T为元素的类型
var arr []int
// arr[0] = 1 切片只是声明,长度为0,不但能通过这样赋值,赋值需要用append
fmt.Printf("%v , %T, %v\n", arr, arr, len(arr)) //[] , []int, 0
fmt.Println(arr == nil) // true, 声明切片没有赋值,默认切片的默认值为nil
var s = []int{1,2,3}
fmt.Printf("%v , %T, %v\n", s, s, len(s)) //[1 2 3] , []int, 3
s[0] = 100 // 有切片长度,在切片长度内是可以通过这样赋值的
// s[1] = 2
- 关于nil的认识:当你声明了一个变量,却还没有赋值时,golang中会自动给你的变量赋值一个默认零值,下面是每种类型对应的值
| 类型 | 默认值 |
|---|---|
| bool | false |
| numbers | 0 |
| string | “” |
| pointers | nil |
| slices | nil |
| maps | nil |
| channels | nil |
| functions | nil |
| interfaces | nil |
切片的循环遍历
基于数组来定义切片
var s = [5]int{1, 2, 3, 4, 5}
s1 := s[2:5] //
fmt.Printf("%v , %T, %v\n", s1, s1, len(s1)) // [3 4 5] , []int, 3
s2 := s[1:]
s3 := s[:3]
s4 := s[:]
fmt.Println(s2, s3, s4) // [2 3 4 5] [1 2 3] [1 2 3 4 5]
切片的长度和容量
- 切片拥有自己的长度和容量,使用内置的len()求长度,内置的cap()求切片容量
- 切片的长度就是它包含元素的个数
- 切片的容量就是从它的第一个元素开始数,到其底层数组元素末尾的个数
var s = []int{1, 2, 3, 4, 5, 6}
s2 := s[2:]
fmt.Printf("len:%v, cap:%v\n", len(s2), cap(s2)) // len:4 cap:4
s3 := s[1:3]
fmt.Printf("len:%v, cap:%v\n", len(s3), cap(s3)) // len:2 cap:5
s4 := s[:3]
fmt.Printf("len:%v, cap:%v\n", len(s4), cap(s4)) // len:3 cap:6
fmt.Println(s2, s3, s4) //[3 4 5 6] [2 3] [1 2 3]
使用make()函数构造切片
- make构造切片格式:
make([]T, int size)其中T为数据类型,size为元素个数
var slice = make([]int, 4)
fmt.Println(slice) //[0 0 0 0]
fmt.Printf("len:%v, cap: %v", len(slice), cap(slice)) //len:4, cap: 4
使用append()添加元素,合并多个切片
var slice = make([]int, 4)
fmt.Println(slice) //[0 0 0 0]
fmt.Printf("%v, len:%v, cap: %v\n", slice, len(slice), cap(slice)) //[0 0 0 0], len:4, cap: 4
slice = append(slice, 10)
fmt.Printf("%v, len:%v, cap: %v", slice, len(slice), cap(slice)) //[0 0 0 0 10], len:5, cap: 8
sliceA := []string {"php", "C"}
sliceB := []string {"golang", "java"}
sliceA = append(sliceA, sliceB...)
fmt.Println(sliceA) //[php C golang java]
切片的扩容策略
var sliceC []int
for i := 1; i < 10; i++ {
sliceC = append(sliceC, i)
fmt.Printf("%v, len: %v, cap: %v\n", sliceC, len(sliceC), cap(sliceC))
}
/*
[1], len: 1, cap: 1
[1 2], len: 2, cap: 2
[1 2 3], len: 3, cap: 4
[1 2 3 4], len: 4, cap: 4
[1 2 3 4 5], len: 5, cap: 8
[1 2 3 4 5 6], len: 6, cap: 8
[1 2 3 4 5 6 7], len: 7, cap: 8
[1 2 3 4 5 6 7 8], len: 8, cap: 8
[1 2 3 4 5 6 7 8 9], len: 9, cap: 16
*/
切片为引用数据类型
sliceA := []int{1,2,3,4}
sliceB := sliceA
sliceB[0] = 100
fmt.Println(sliceA) // 打印的和下面是一样的
fmt.Println(sliceB) // [100 2 3 4]
// 切片是引用类型,无需返回值
func sortIntAsc(slice []int) {
for i := 0; i < len(slice); i++ {
for j:= i + 1; j < len(slice); j++ {
if (slice[i] > slice[j]) {
slice[i], slice[j] = slice[j], slice[i]
}
}
}
}
func main() {
sliceA := []int{12,22,1,6,5,3}
sortIntAsc(sliceA)
fmt.Println(sliceA) // [1 3 5 6 12 22]
}
copy()函数复制切片
sliceA := []string {"php", "C"}
sliceB := make([]string ,2)
copy(sliceB, sliceA)
sliceB[0] = "C++"
fmt.Printf("%v, %v", sliceA, sliceB) // [php C], [C++ C]
从切片中删除元素
go语言中没有删除切片元素的专门方法,可以用切片本身的特性删除元素
切片的常用算法:选择排序,冒泡排序
1. 选择排序
// 选择排序(升序)
slice := []int{5,3,2,1,9,6,4,8,7}
for i := 0; i < len(slice); i++ {
for j := i+1; j < len(slice); j++ {
// 找出最小的放在第一个位置上
if (slice[i] > slice[j]) {
// 两个数的交互,不需要第三个中间变量
slice[i], slice[j] = slice[j], slice[i]
}
}
}
fmt.Printf("%v", slice) // [1 2 3 5 6 7 8 9]
2. 冒泡排序
概念:从头到尾,比较相邻的两个元素的大小,如果符合交换条件,交换两个元素的位置
特点:每一轮比较中,都会选出一个最大的数,放在正确的位置
for i := 0; i < len(slice); i++ {
// 注意判断的条件
for j := 0; j < len(slice)-1 - i; j++ {
if (slice[j] > slice[j+1]) {
slice[j], slice[j+1] = slice[j+1], slice[j]
}
}
}
fmt.Printf("%v", slice) // [1 2 3 5 6 7 8 9]
3. 内置Sort包对切片进行排序
3.9 map
map 是一种无序的基于 key - vlaue 的数据结构,go语言中的map也是引用数据类型,必须初始化才能使用
map的定义
格式:map[KeyType]ValueType
KeyType表示键的类型ValueType表示键对应的值的类型
需要用make 来初始化,make用于slice, map, channel 的初始化
var user = make(map[string]string)
user["username"] = "zhangshan"
user["age"] = "20"
fmt.Println(user) // map[age:20 username:zhangshan]
userinfo := map[string]string {
"usernmae": "zhansan",
"age" : "20",
}
fmt.Println(userinfo)
循环遍历map数据
for k, v := range userinfo {
fmt.Printf("key:%v, value:%v\n", k, v)
}
map数据类型的curd(增删改查)
- 增加数据
userinfo["keyString"] = "new content"
- 删除数据delete()
delete(userinfo, "age");
- 修改数据(直接赋值)
- 查数据, 判断键值是否存在
// 判断是否有xxx这个
fmt.Pringln(userinfo["age"])
v, ok := userinfo["xxx"]
fmt.Println(v, ok)
基于map的切片
var userinfo = make([]map[string]string, 3)
var person1 = make(map[string]string)
person1["username"] = "zs"
person1["age"] = "10"
var person2 = make(map[string]string)
person2["username"] = "ls"
person2["age"] = "20"
userinfo[0] = person1
userinfo[1] = person2
fmt.Println(userinfo) // [map[age:10 username:zs] map[age:20 username:ls] map[]]
// 循环切片中的map
for _, v := range userinfo {
for key, value := range v {
fmt.Printf("key:%v, value: %v \n", key, value)
}
}
/*
key:username, value: zs
key:age, value: 10
key:username, value: ls
key:age, value: 20
*/
map类型的值定义为切片
var userinfo = make(map[string][]string)
userinfo["hobby"] = []string {
"吃饭",
"睡觉",
}
fmt.Println(userinfo) // map[hobby:[吃饭 睡觉]]
对map的key进行升序排序输出
func main() {
var map1 = make(map[int]int)
map1[10] = 100
map1[5] = 50
map1[1] = 10
map1[3] = 30
map1[7] = 70
map1[2] = 20
fmt.Println(map1)
// 按照map中的key小到大输出值
// 1. 放入map key的值到一个切片中
var slice []int
for k, _ := range map1 {
slice = append(slice, k)
}
fmt.Println(slice)
// 2. 在切片中算出升序,选择排序或者冒泡排序
for i := 0; i < len(slice); i++ {
for j := i+1; j < len(slice); j++ {
if (slice[i] > slice[j]) {
slice[i], slice[j] = slice[j], slice[i]
}
}
}
fmt.Println(slice)
// 3. 输出map的值
for _, v := range slice {
fmt.Printf("map key:%v, value:%v\n", v, map1[v])
}
/*
map key:1, value:10
map key:2, value:20
map key:3, value:30
map key:5, value:50
map key:7, value:70
map key:10, value:100
*/
}
3.10 结构体
Golang中没有类的概念,结构体和类有点相似,可以封装多个基本类型,这种数据类型叫结构体
自定义类型
- 使用
type关键字来定义自定义类型 type myInt int
其中:
myInt: 定义myInt类型,myInt就是一种新的类型,它具有int的特征
type myInt int
func main() {
var a myInt = 10
fmt.Printf("a: %v , a type:%T\n", a, a) // a: 10 , a type:main.myInt
}
类型别名
type myFloat = float64
type myFloat = float64
func main() {
var a myFloat = 10
fmt.Printf("a: %v , a type:%T\n", a, a) // a: 10 , a type:float64
}
结构体的定义
使用type和struct 关键字来定义结构体,格式如下:
type 类型名 struct {
字段名 字段类型
字段名 字段类型
...
}
结构体初始化多种方法
type Person struct {
name string
age int
sex string
}
func main() {
var p1 Person // 实例化Person结构体
p1.name = "zs"
p1.sex = "男"
p1.age = 20
fmt.Printf("p1: %v , type:%T\n", p1, p1)
fmt.Printf("p1: %#v, type:%T\n", p1, p1)
/*
p1: {zs 20 男} , type:main.Person
p1: main.Person{name:"zs", age:20, sex:"男"}, type:main.Person
*/
var p2 = new(Person)
// (*p2).age = 10 基本不这样写
p2.name = "ls"
p2.sex = "女"
p2.age = 18
fmt.Printf("p2: %v , type:%T\n", p2, p2)
fmt.Printf("p2: %#v, type:%T\n", p2, p2)
/*
p2: &{ls 18 女} , type:*main.Person
p2: &main.Person{name:"ls", age:18, sex:"女"}, type:*main.Person
*/
var p3 = &Person{}
p3.name = "lxxs"
p3.sex = "女"
p3.age = 11
fmt.Printf("p3: %v , type:%T\n", p3, p3)
fmt.Printf("p3: %#v, type:%T\n", p3, p3)
var p4 = Person {
name: "x嘻嘻嘻",
age: 10,
sex: "男",
}
fmt.Printf("p4: %v , type:%T\n", p4, p4)
fmt.Printf("p4: %#v, type:%T\n", p4, p4)
}
结构体为值类型
type Person struct {
name string
age int
sex string
}
func main() {
var p1 Person // 实例化Person结构体
p1.name = "zs"
p1.sex = "男"
p1.age = 20
p2 := p1
p2.name = "aaaa"
fmt.Printf("p1: %v\n", p1) // p1: {zs 20 男}
fmt.Printf("p2: %v\n", p2) // p2: {aaaa 20 男}
}
结构体方法
在go语言中,没有类的概念但是可以给类型(结构体,自定义类型)定义方法,所谓方法就是定义了接收者的函数。接收者的概念类似于其他语言的this
方法定义如下:
func (结构体变量 结构体类型) 方法名(参数列表) (返回参数) {函数体}
其中:
结构体类型: 可以是普通类型或者指针类型
type Person struct {
name string
age int
sex string
}
// 接收者类型可以是指针类型
func (p Person) PrintInfo() {
fmt.Printf("姓名:%v, 年龄:%v\n", p.name, p.age)
}
func (p *Person) SetInfo(name string, age int) {
p.name = name
p.age = age
}
func main() {
var p1 Person // 实例化Person结构体
p1.name = "zs"
p1.sex = "男"
p1.age = 20
p1.PrintInfo() // 姓名:zs, 年龄:20
p1.SetInfo("xxx", 28)
p1.PrintInfo() // 姓名:xxx, 年龄:28
}
结构体切片
// 用户结构体类型
type ClientInfo struct {
wxConn string;
isConnect bool;
ip string;
}
// 绑定ClientInfo类型方法
func (p *ClientInfo) setInfo(conn string, isConnect bool, ip string) {
p.wxConn = conn
p.isConnect = isConnect
p.ip = ip
}
func main() {
// 结构体切片
var clients []ClientInfo
// 赋值方式一
var client1 = ClientInfo{"conn1", true, "888"}
var client2 = ClientInfo{"conn2", false, "999"}
// 赋值方式二, 通过方法
var person1 ClientInfo
person1.setInfo("conn3", true, "777")
// 添加到切片中
clients = append(clients, client1)
clients = append(clients, client2)
clients = append(clients, person1)
for _, v := range clients {
fmt.Printf("client: %v, connect: %v, ip: %v\n", v.wxConn, v.isConnect, v.ip)
}
/*
client: conn1, connect: true, ip: 888
client: conn2, connect: false, ip: 999
client: conn3, connect: true, ip: 777
*/
}
结构体的匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段,结构体里面的匿名字段类型必须是唯一的
结构体嵌套或继承
- 先看下面的列子
type Person struct {
Name string
Age int
Hobby []string
map1 map[string]string
}
func main() {
var p Person
p.Name = "张三"
p.Age = 20
p.Hobby = make([]string, 6)
p.Hobby[0] = "写代码"
p.Hobby[1] = "打篮球"
p.Hobby[2] = "睡觉"
p.map1 = make(map[string]string)
p.map1["address"] = "beijing"
p.map1["phone"] = "138888"
fmt.Printf("%#v\n", p) // main.Person{Name:"张三", Age:20, Hobby:[]string{"写代码", "打篮球", "睡觉", "", "", ""}, map1:map[string]string{"address":"beijing", "phone":"138888"}}
fmt.Printf("%#v\n", p.Hobby) //[]string{"写代码", "打篮球", "睡觉", "", "", ""}
}
- 嵌套
type User struct {
Username string
Password string
Age int
// 匿名字段,类型Address
Address
}
type Address struct {
Name string
Phone string
City string
}
func main() {
var user User
user.Username = "zs"
user.Password = "passwoddo"
user.Age = 18
user.Address.Name = "caoyang"
user.Address.City = "beijin"
user.Address.Phone = "1888888"
fmt.Printf("%#v\n", user)
// main.User{Username:"zs", Password:"passwoddo", Age:18, Address:main.Address{Name:"caoyang", Phone:"1888888", City:"beijin"}}
}
- 继承
type Animate struct {
Name string
}
func (a Animate) run() {
fmt.Printf("name:%v run\n",a.Name)
}
type Dog struct {
Age int
Animate
}
func (d Dog) wang() {
fmt.Printf("name:%v wang wang\n",d.Name)
}
func main() {
var d Dog
d.Age = 10
d.Name= "小白"
d.wang() // name:小白 wang wang
d.run() // name:小白, run
}
结构体和Json相互转换 序列化 反序列化
关于JSON 数据
JSON(javascript object notation) 是一种轻量级的数据交换格式。易于人阅读和编写,同时也易于机器简析和生成。RESTfull api 接口中返回的数据都是json数据
- json基本格式
{
"username": "name1",
"password": "xxx1113888"
}
序列化:把结构体转成JSON字符串
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int
Name string
Sno string
age int
// 私有属性不能被json包访问
}
func main() {
var s1 = Student{
ID: 11,
Name: "张三",
Sno: "s0001",
age: 18,
}
// main.Student{ID:11, Name:"张三", Sno:"s0001", age:18}
fmt.Printf("%#v\n", s1)
// 1. 序列化
jsonByte, _ := json.Marshal(s1)
jsonStr := string(jsonByte)
fmt.Println(jsonStr) // {"ID":11,"Name":"张三","Sno":"s0001"}
}
反序列化:把JSON数据转换为结构体数据
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int
Name string
Sno string
age int
// 私有属性不能被json包访问
}
func main() {
// 2. 反序列化
jsonStr := `{"ID":18,"Name":"lisi","Sno":"s0002"}`
var s2 Student
// s2需要指针转到,才能达到修改
err := json.Unmarshal([]byte(jsonStr), &s2)
if err != nil {
fmt.Println(err)
}
fmt.Printf("%#v\n", s2) //main.Student{ID:18, Name:"lisi", Sno:"s0002", age:0}
}
结构体标签Tag
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来,Tag在结构体字段的后方定义,由一对反引号包裹起来,具体格式如下:
key1:"vaule1" key2: "value2"
结构体tag由一个或多个键值对组成,键与值使用冒号分割,值用双引号括起来,同一个结构体字段可以设置多个键值对,不同的键值对之间使用空格分隔
type Student struct {
ID int `json:"id"`
Name string `json:"name"`
Sno string `json:"sno"`
age int
// 私有属性不能被json包访问
}
func main() {
var s1 = Student{
ID: 11,
Name: "张三",
Sno: "s0001",
age: 18,
}
fmt.Printf("%#v\n", s1)
// 1. 序列化
jsonByte, _ := json.Marshal(s1)
jsonStr := string(jsonByte)
fmt.Println(jsonStr) // {"id":11,"name":"张三","sno":"s0001"}
}
复杂的结构体转json,在项目中经常使用
import (
"encoding/json"
"fmt"
)
type Student struct {
Id int `json:"id"`
Name string `json:"name"`
Sno string `json:"sno"`
}
type Class struct {
Title string `json:"title"`
Students []Student `json:"students"`
}
func main() {
// Class 初始化方式一
var c Class
c.Title = "二一班"
for i := 1; i <= 10; i++ {
s1 := Student{
Id: i,
Name: fmt.Sprintf("Student%v", i),
Sno: fmt.Sprintf("s%v", i),
}
// c.Students = (c.Students, s1)
c.Students = append(c.Students, s1)
}
// 1. 序列化
jsonByte, _ := json.Marshal(c)
jsonStr := string(jsonByte)
fmt.Println(jsonStr)
// {"title":"二一班","students":[{"id":1,"name":"Student1","sno":"s1"},{"id":2,"name":"Student2","sno":"s2"},{"id":3,"name":"Student3","sno":"s3"},{"id":4,"name":"Student4","sno":"s4"},{"id":5,"name":"Student5","sno":"s5"},{"id":6,"name":"Student6","sno":"s6"},{"id":7,"name":"Student7","sno":"s7"},{"id":8,"name":"Student8","sno":"s8"},{"id":9,"name":"Student9","sno":"s9"},{"id":10,"name":"Student10","sno":"s10"}]}
}
3.11 通道(channel)
3.12 接口
第四章:运算符
4.1 算术运算符( +, -, *, /, % )
4.2 关系运算符( >, < ,=>, <=)
4.3 逻辑运算符( &&, || , ! )
4.4 赋值运算符 ( = , +=, -=, *=, /=, %= )
4.5 运算符的几个练习 位运算符
第五章:流程控制和循环语句
5.1 流程控制 if else for的基本使用
5.2 流程控制 for range swirch case
5.3 流程控制 continue break goto
5.4 数组的循环遍历
5.5 多维数组 值类型 引用类型
第六章:函数详解
6.1 函数定义、函数参数、函数返回值
函数定义
func 函数名(参数)(返回值) {
函数体
}
函数参数
- 可变参数
func fn1(y ...int) int {
fmt.Printf("y: %v, type: %T\n", y, y) // y: [100 200 300], type: []int
sum := 0
for _, v := range y {
fmt.Println(v)
sum += v
}
return sum
}
func main() {
sum:= fn1(100, 200, 300)
fmt.Print(sum) // 600
}
函数返回值
- 返回多个值
func calc(x int, y int) (int, int) {
sum := x + y
sub := x -y
return sum, sub
}
func main() {
sum, sub := calc(200, 100)
fmt.Printf("sum:%v, sub: %v\n", sum, sub) // sum:300, sub: 100
}
- 返回值命名,在函数体中直接可以使用这些返回值的变量名
func calc(x int, y int) (sum int, sub int) {
sum = x + y
sub = x -y
return
}
func main() {
sum, sub := calc(200, 100)
fmt.Printf("sum:%v, sub: %v\n", sum, sub) // sum:300, sub: 100
}
6.2 map当做函数参数
import (
"fmt"
"sort"
)
func mapSort(map1 map[string]string) string {
var sliceKey []string
// 1. 把map对象的可以放在一个切片里面
for k, _ := range map1 {
sliceKey = append(sliceKey, k)
}
// 2. 对key进行升序排列
sort.Strings(sliceKey)
temp := ""
for _, v := range sliceKey {
temp += fmt.Sprintf("%v=%v", v , map1[v])
}
return temp
}
func main() {
// 对map进行key的排序,主要用于签名算法
var map1 = map[string]string{"username": "name1", "age": "20", "sex": "男", "height": "180"}
list := mapSort(map1)
fmt.Println(list) //age=20height=180sex=男username=name1
}
函数变量作用域
- 全局变量
定义在函数体外的变量,在程序运行整个周期都存在的变量,称为全局变量
- 局部变量
定义在函数体内的变量,只在变量的函数体存在,函数结束,变量就不存在的变量,称为局部变量
6.3 函数类型
函数类型定义
type fnName func(int, int) int
上面语句定义了fnName 类型,它是一种函数类型,这种类型接收两个int类型的参数,并且返回一个int类型的返回值.
type myInf int 定义自己的类型
只要满足这个条件的函数都是fnName类型的函数。列如下面的add和sub是fnName类型
type fnName func(int, int) int
type MyInt int // 也可以自定义自己的类型
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
func main() {
var op fnName
op = add
fmt.Printf("op 的类型:%T\n", op) // op 的类型:main.fnName
fmt.Println(op(10, 20)) // 30
op = sub
fmt.Println(op(10, 20)) // -10
var i MyInt
fmt.Printf("%T\n", i) // main.MyInt
}
函数作为参数
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
type calcType func(int, int) int
func calc(x, y int, cb calcType) int {
return cb(x, y)
}
func main() {
sum := calc(20, 10, add)
fmt.Println(sum) // 30
// 也可以通过匿名函数传递参数
num := calc(10,5, func(x, y int) int {
return x * y
})
fmt.Println(num) // 50
}
函数作为返回值
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
// 定义一个方法类型
type calcType func(int, int) int
func do(o string) calcType {
switch o {
case "+":
return add
case "-":
return sub
case "*":
return func(x, y int) int {
return x * y
}
default:
return nil
}
}
func main() {
// 返回一个方法
var a = do("*")
b := a(10, 20)
fmt.Println(b) // 50
}
匿名函数
函数可以作为函数的返回值,但在go语言中,函数里面的函数只能使用匿名函数,匿名函数就是没有名字的函数。
- 定义匿名函数格式
func (参数) 返回值 { 函数体 }
func main() {
// 匿名函数, 匿名自执行函数
func (x, y int) {
fmt.Println("Test:", x + y) // Test: 30
}(10, 20)
// 匿名函数赋值给一个变量
var fn = func (x, y int)int {
return x + y
}
fmt.Println(fn(10,20)) // 30
}
函数递归
函数自己调用自己就是递归函数, 递归函数需要退出的条件,否则就是死循环
- 打印小于自然数的所有整数
func fn(n int) {
fmt.Println(n)
if (n > 0) {
n--
fn(n)
}
}
func main() {
fn(10)
}
- 求和
// 求1 ... n 的数的和
func fn(n int) int {
if n > 1 {
return n + fn(n-1)
} else {
return 1
}
}
func main() {
fmt.Println(fn(100)) // 5050
}
- 求数的阶乘
闭包
闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。或者说是函数和其引用环境的组合体
6.5 defer panic recover
6.5.1 defer 语句
被defer 语句修饰的语句,是最后执行语句,当在一个函数中有多个defer语句时,则按后写的defer语句先执行,先写的defer语句后执行
func test() {
fmt.Println("start ...")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end ...")
}
func main() {
test()
/*
start ...
end ...
3
2
1
*/
}
区分defer和return语句的先后顺序
func test1() int {
var a int // 0
defer func () {
a++
}()
return a
}
func test2() (a int) {
defer func () {
a++
}()
return a
}
func main() {
fmt.Println(test1()) // 0
fmt.Println(test2()) // 1
}
panic抛出异常 recover接收异常
当我们手动
panic抛出异常的时候,必须要通过recover来接收异常,否则程序会崩溃。同时需要用defer语句来修饰一个匿名函数,并且是自执行的
func fn1() {
fmt.Println("fn1 start")
}
func fn2() {
defer func() {
err := recover()
if err != nil {
fmt.Println(err)
}
}()
panic("fn2 异常")
}
// 当除数是0 的时候,程序也不会崩溃
func fn3(a, b int) int {
defer func () {
err := recover()
if err != nil {
fmt.Println("err:", err)
}
}()
return a / b
}
func main() {
fn1()
fn2()
fmt.Println(fn3(10, 0)) // err: runtime error: integer divide by zero
fmt.Println("main end")
}
panic, recover案例
panic可以在任何地方引发,但 recover只有在 defer 调用的函数中有效
import (
"errors"
"fmt"
)
func readFile(fileName string) error {
if fileName == "main.go" {
return nil
} else {
return errors.New("读取文件失败")
}
}
func myFn() {
defer func () {
e := recover()
if e!= nil {
fmt.Println("send a email to admin")
}
}()
err := readFile("xx.go")
if err != nil {
panic(err)
}
}
func main() {
myFn() // send a email to admin
}
第七章:指针详解 、make new方法分配内存
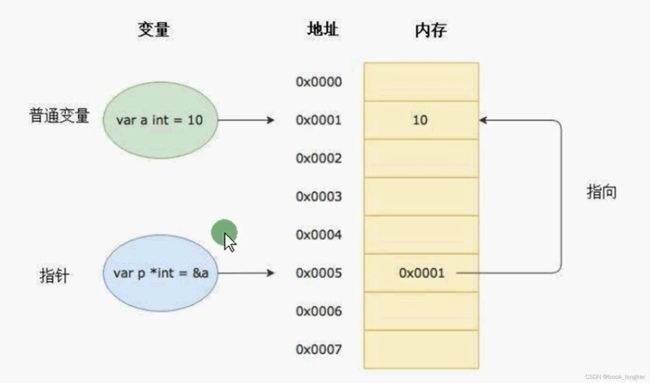
关于指针
变量是用来存储数据的,变量的本质是给存储数据的内存地址起了一个好记的别名。比如我们定义了一个变量
a := 10, 这个时候可以直接通过a这个变量来读取内存中保存的10这个值。在计算机底层a这个变量其实对应了一个内存地址
指针也是一个变量,但它是一种特殊的变量,它存储的数据不是普通的值,而是另一个变量的内存地址
看图理解普通变量和指针的关系
指针地址和指针类型
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置,Go语言使用
&放在变量前面对变量进行取地址操作。每种数据类型,都有相对应的指针类型
取变量指针语法:
ptr := &v
其中:
v:代表变量,类型为T
ptr:用于接收地址的变量,ptr类型为*
取指针的值(和C,C++ 一样的语法)
*p 代表取出p这个变量对应的内存地址的所指向的值
func main() {
var a = 10
var p = &a
// *p取该指针指向内存地址所指向的值
fmt.Println(*p) // 10
// 赋值
*p = 30
fmt.Println(a) // 30
}
引用类型必须要分配空间
切片和map中的分配空间
func main() {
// 错误的,因为没有给map分配空间,切片也是一样
// var userinfo map[string]string
// userinfo["username"] = "zs"
// fmt.Println(userinfo)
var userinfo = make(map[string]string)
userinfo["username"] = "zs"
fmt.Println(userinfo) // map[username:zs]
// var a []int // 错误
// a[0] = 10
var a []int
a = append(a, 10) // append 也会分配存储空间,就是扩容操作
a = append(a, 20)
fmt.Println(a) // [10 20]
}
指针也是引用数据类型
// 指针也是引用类型, 下面是错误的
// var b *int
// *b = 100
var b *int
b = new(int)
*b = 100
fmt.Println(*b) //100
// 通过new函数分配内存
var c = new(int)
fmt.Printf("值:%v, 类型:%T,指针对应的值:%v\n", c, c, *c) // 值:0xc0000120e8, 类型:*int,指针对应的值:0
new函数分配内存
new和make都是内建函数,主要用来分配内存。new 使用格式如下:
func new(Type) *Type
其中:
Type: 表示类型,new函数只接收一个参数,这个参数是一个类型
*Type: 表示类型指针,new函数返回一个指向该类型内存地址的指针
make函数分配内存
make也是用于分配内存,区别于new,它只能用于slice, map, channel的内存创建,而且返回的类型是三个类型本身,而不是他们的指针,因为这三种类型就是引用类型,所以就没有必要返回他们的指针
make 函数的格式
func make(t Type, size ...integerType) Type
第八章:Golang 中的 go mod 以及 Golang 包详解
8.1 go mod 详解
go mod 包管理工具,在Golang1.11版本之前如果我们要自定义包的话必须把项目方在GOPATH目录下,之后无需手动配置环境变量,使用go mod管理项目,也不需要非得把项目放到GOPATH指定目录下,可以在你磁盘的任何位置新建项目,Go1.13之后彻底不要GOPATH了
实际开发中,在项目目录中使用go mod命令生成一个go.mod文件管理我们项目的依赖
go mod 使用
- 创建项目文件夹
demo - 进入
demo文件夹,执行命令:go mod init demo, 就会在当前目录下面创建一个go.mod文件,内容如下:
module demo
go 1.18
其中:
module demo 当前项目名称
go 1.18 go的版本号
自定义包
- 在项目文件夹下
demo创建包的目录,如calc - 在
calc目录下面创建一个calc.go文件,复制如下内容:
package calc // 定义包的名字,命名方式就是它上级文件夹的名字
// 方法名字大写开头,代表可以在其他包中能访问这个方法
func Add(x, y int) int {
return x + y
}
func Sub(x, y int) int {
return x - y
}
- 在项目文件夹下创建
main.go文件,复制如下内容:
import (
"fmt"
"demo/calc" //引入自定义包
)
func main() {
sum := calc.Add(10, 20)
fmt.Println(sum) // 30
}
包的init()函数
在一个包文件里面如果有
init()函数,则会先执行这个函数,多个包导入时,被最后导入的包会最先初始化并调用其init()函数,比main函数还要先执行。如图:
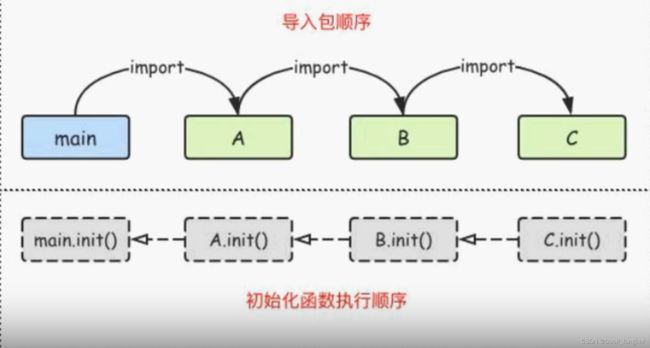
init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它
第三方包详解
查看地址
https://pkg.go.dev/
安装第三方包
- 第一种方法:
go get 包的地址(全局安装) - 第二种方法:
go mod download(全局安装),自动下载到$GOPATH/pkd/mod,多个项目共享缓存mod, 注意使用go mod download时候需要在你的项目里面引入第三方包 - 第三种方法:
go mod vendor将依赖复制到当前项目的vendor下(本项目), 你需要在你的项目里面引入第三方包
第九章:接口详解
9.1 接口介绍
现实生活中,要想实现电脑的
USB接口和其他设备连接,其他的设备必须按照USB的规范去实现;
Golang的接口是一种抽象数据类型,接口定义了对象的行为规范,只定义规范不实现,接口定义的规范有具体的对象来实现
9.2 接口定义
接口(interface)是一种类型,一种抽象的类型。接口是一组函数method的集合,Golang中的接口不能包含任何变量
接口中的所有方法都没有方法体,接口定义了一个对象的行为规范,只定义不实现,接口体现了程序设计的多太和高内聚低耦合的思想
只需要一个变量含有接口类型中的所有方法,那么这个变量就实现了这个接口
- 格式定义
type 接口名 inferface {
方法名1(参数列表1) 返回值列表1
方法名2(参数列表2) 返回值列表2
}
接口名:一般在单词后面添加er,如有写操作的接口Writer, 有字符串功能的接口叫Stringer
方法名:首字母大写且接口类型首字母也是大写,这个方法可以被接口所在的包之外的代码访问
参数列表,返回值列表:参数变量名可以省略
9.3 实现接口
type Usber interface {
start()
stop()
}
// 如果接口里有方法的话,必须要通过结构体或自定义类型实现这个接口
type Phone struct {
Name string
}
func (p Phone) start() {
fmt.Println(p.Name, "start")
}
func (p Phone) stop() {
fmt.Println(p.Name, "stop")
}
type Camera struct {
}
func (c Camera) start(){
fmt.Println("Camera start")
}
func (c Camera) stop(){
fmt.Println("Camera stop")
}
func (c Camera) run(){
fmt.Println("Camera run")
}
func main() {
var phone = Phone{"apple"}
// 现在还没有和接口绑定
phone.start()
phone.stop()
var p1 Usber
p1 = phone // 表示手机实现Usb接口
p1.start()
p1.stop()
var c Camera
var c1 Usber = c
c.start()
c.stop()
c.run()
c1.start()
c1.stop()
}
type Usber interface {
Start()
Stop()
}
type Computer struct {
}
func (c Computer) work(usb Usber) {
usb.Start()
usb.Stop()
}
type Phone struct {
Name string
}
func (p Phone) Start() {
fmt.Printf("name:%v start\n", p.Name)
}
func (p Phone) Stop() {
fmt.Printf("name:%v stop\n", p.Name)
}
func main() {
p := Phone{"apple"}
// var usb Usber = p
var c Computer
c.work(p)
/*
name:apple start
name:apple stop
*/
}
9.4 空接口
空接口可以代表任何数据类型
Golang 中的接口可以不定义任何方法,没有定义任何方法的接口就是空接口。空接口表示没有任何约束,因此任何类型变量都可以实现空接口
// 空接口, 不需要定义也行
type A interface {
}
func main() {
var a A
var name string = "hello world"
a = name
fmt.Printf("%v, %T\n", a, a) // hello world, string
var age int = 18
a = age
fmt.Printf("%v, %T\n", a, a) // 18, int
}
- 直接interface{}当类型使用,它代表任何类型
func main() {
var a interface{}
fmt.Printf("%v, %T\n", a, a) // ,
b := 0
a = b
fmt.Printf("%v, %T\n", a, a) // 0, int
a = "hello"
fmt.Printf("%v, %T\n", a, a) // hello, string
var s1 = []interface{}{1,"hello", true}
fmt.Printf("%v, %T\n", s1, s1) // [1, hello, true], []interface {}
}
- 空接口作为函数的参数,作为切片,map的interface{}类型
func Show(a interface{}) {
fmt.Printf("%v, %T\n", a, a)
}
func main() {
Show("abc") //abc, string
Show(123) //123, int
Show(true) //true, bool
Show([]int{1,3,5}) //[1 3 5], []int
//map[age:18 username:name1], map[string]string
Show(map[string]string{"username":"name1", "age": "18"})
// map[age:18 username:name2], map[string]interface {}
Show(map[string]interface{}{"username":"name2", "age": 18})
}
- 类型断言,判断空接口的目前代表的类型
func Show(a interface{}) {
if _, ok := a.(int); ok {
fmt.Println("var is int type")
} else if _, ok := a.(string); ok {
fmt.Println("var is string type")
} else if _, ok := a.(bool); ok {
fmt.Println("var is bool type")
} else {
fmt.Printf("not find type")
}
}
func main() {
Show(11)
Show("string")
Show(true)
}
9.5 类型断言
一个接口的值是由一个具体的类型和具体类型的值两部分组成,这两部分分别称为接口的动态类型和动态值
如果我们想要判断空接口中值的类型,那么这个时候就可以使用类型断言
格式如下:
x.(T)
其中:
x:表示类型为interface{}的变量
T:表示断言x可能是的类型
该语法返回两个值,第一个参数是x转化为T类型后的变量,第二个值是一个布尔值
func MyPrint(x interface{}) {
switch x.(type) {
case int:
fmt.Println("int type")
case string:
fmt.Println("string type")
case bool:
fmt.Println("bool type")
default:
fmt.Println("传入错误")
}
}
func main() {
var a interface{}
a = "hello"
MyPrint(a)
a = 10
MyPrint(a)
a = true
MyPrint(a)
}
- 获取切片或者map类型下的空接口,必须要使用如下的方式获取,没有索引
func main() {
var a interface{}
a = "hello"
v, ok := a.(string)
if ok {
fmt.Println("a is string type, ", v) //a is string type, hello
}
var userInfo = make(map[string]interface{})
userInfo["name"] = "user1"
userInfo["age"] = 18
// 想取得hobby的值,必须要使用类型断言的方式获取
userInfo["hobby"] = []string{"langqil", "yumaoqiu"}
// 可以打印全部信息
fmt.Println(userInfo) // map[age:18 hobby:[langqil yumaoqiu] name:user1]
fmt.Println(userInfo["hobby"]) // [langqil yumaoqiu]
// 如果你想访问hobby里面的某个信息,就必须使用类型断言的方法去做
// fmt.Println(userInfo["hobbyl"][1]) // 错误
// 使用类型断言的方式获取hobby的值
if v, ok := userInfo["hobby"].([]string); ok {
fmt.Println(v[0])
fmt.Println(v[1])
}
}
9.6 结构体实现多接口、接口嵌套、结构体指针接收者实现接口
9.7 空接口和类型断言使用细节-类型断言输出空接口类型结构体属性
第十章:goroutine channel实现并发和并行
关于进程和线程
进程
进程(Process)就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位,进程是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间。一个进程至少有5种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
线程
线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单元.
一个进程可以创建多个线程,同一个进程中的多线程可以并发执行
10.1 并发和并行
sync.WaitGroup 协程等待
程序中开辟其他线程后,主线程要等待其他线程运行完后才能退出的实现方法
- sync.WaitGroup 申请一个变量 var wg sync.WaitGroup
- 在调用线程的时候,加上一个wg.Add(1) (协程计数器加1) , 在线程函数体里面最后面加上wg.Done()(协程计数器-1)
- 主进程加上wg.Wait() 等待协程执行完毕
import (
"fmt"
"sync"
"time"
)
func Test1() {
for i := 0; i < 10; i++ {
fmt.Println("Test1 start ... ", i)
time.Sleep(time.Millisecond * 20)
}
wg.Done()
}
func Test2() {
for i := 0; i < 10; i++ {
fmt.Println("Test2 start ... ", i)
time.Sleep(time.Millisecond * 20)
}
wg.Done()
}
var wg sync.WaitGroup
func main() {
wg.Add(1)
go Test1()
wg.Add(1)
go Test2()
for i := 0; i < 10; i++ {
fmt.Println("main start ", i)
}
time.Sleep(time.Millisecond * 20)
wg.Wait() //等待协程执行完毕
fmt.Println("main end ")
}
设置并行运行时占用的CPU数量, runtime包
// 获取CPU的核心数
number := runtime.NumCPU()
fmt.Println("Cpu = ", number)
// 设置可以使用的最大核心数
runtime.GOMAXPROCS(number -1)
fmt.Println("main end ")
通过循环开启协程
import (
"fmt"
"sync"
)
func Test(num int) {
for i := 1; i < 10; i++ {
fmt.Printf("Test(%v) 打印的第%v条数据 ... \n", num, i)
}
defer wg.Done()
}
var wg sync.WaitGroup
func main() {
for i := 0; i < 10; i++ {
wg.Add(1)
Test(i)
}
fmt.Println("main end ")
}
channel管道
管道是 Golang 在语言级别上提供的 goroutine 间的通讯方式,我们可以使用 channel 在多个 goroutine 之间传递消息。如果说 goroutine 是 Go 程序并发的执行体,channel 就是它们之间的连接。channel 是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制
Golang 的并发模型是 CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
Go 语言中的管道(channel)是一种特殊的类型。管道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个管道都是一个具体类型的导管,也就是声明 channel 的时候需要为其指定元素类型。
channel 类型
- channel 是一种类型,一种引用类型。声明管道类型的格式如下:
var a chan int
var b chan string
var c chan []int
var d chan []map[string]string
创建channel
- 声明的管道后需要使用 make 函数初始化之后才能使用,必须要有容量。创建channel 的格式如下:
//创建一个能存储 10 个 int 类型数据的管道,
ch1 := make(chan int, 10)
//创建一个能存储 4 个 bool 类型数据的管道
ch2 := make(chan bool, 4)
//创建一个能存储 3 个[]int 切片类型数据的管道
ch3 := make(chan []int, 3)
操作channel
- 管道有发送(send)、接收(receive)和关闭(close)三种操作。发送和接收都使用<-符号。
func main() {
// 1.创建管道
ch := make(chan int, 3)
// 2.使用管道,先进先出
// 写入数据
ch <- 10
ch <- 20
ch <- 30
// 3. 读取数据
num := <-ch
// 10
fmt.Println(num)
<-ch // 从管道里面取值 20
c := <-ch
// 30
fmt.Println(c)
// 查看管道的基本信息
fmt.Printf("channel value:%v, cap: %v, len:%v\n", ch, cap(ch), len(ch))
// channel value:0xc0000d4080, cap: 3, len:0
ch <- 11
fmt.Printf("channel value:%v, cap: %v, len:%v\n", ch, cap(ch), len(ch))
// channel value:0xc0000d4080, cap: 3, len:1
// close channel
close(ch)
}
管道是引用数据类型
// 判断管道的类型(引用数据类型)
ch1 := make(chan int, 4)
ch1 <- 11
ch1 <- 22
ch1 <- 33
ch2 := ch1
ch2 <- 44
<- ch1
<- ch1
<- ch1
d := <- ch1
fmt.Println(d) //44
管道阻塞
写死锁
// 管道阻塞
ch1 := make(chan int, 1)
ch1 <- 11
ch1 <- 22 // fatal error: all goroutines are asleep - deadlock!
读死锁
ch2 := make(chan string, 2)
ch2 <- "data1"
ch2 <- "data2"
d1 := <-ch2
d2 := <-ch2
fmt.Println(d1, d2) // data1 data2
ch2 <- "data4"
ch2 <- "data5"
d3 := <- ch2
d4 := <- ch2
// 管道里面没有数据,在读取就会有致命错误:死锁
d5 := <- ch2 // fatal error: all goroutines are asleep - deadlock!
fmt.Println(d3, d4,) // data1 data2
解决管道阻塞后死锁问题
- 在协程里面使用管道,就不会出现管道阻塞时的死锁问题
管道循环遍历
- 通过for range 循环读取管道内容,需要关闭管道,否则会有错误
func main() {
// 1.创建管道
ch := make(chan int, 10)
for i := 1; i <= 10; i++ {
ch <- i
}
close(ch)
// 通过for range循环读取管道内容, 能读取数据,但会有“fatal error: all goroutines are asleep - deadlock!”
// 需要关闭管道就不会有上面的错误, 或者通过for 循环
for v := range ch {
fmt.Println(v)
}
}
- 直接通过for 循环,可以不关闭管道
func main() {
// 1.创建管道
ch := make(chan int, 10)
for i := 1; i <= 10; i++ {
ch <- i
}
for j := 1; j <= 10; j++ {
fmt.Println(<-ch)
}
}
goroutine结合Channel管道
- 需求:goroutine和channel 协同工作案例
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
// 写入管道数据
func writeData(ch chan int) {
for i := 1; i <= 10; i++ {
// 用来调试
time.Sleep(time.Millisecond * 500)
ch <- i
fmt.Printf("【写入】数据 %v 成功\n", i)
}
close(ch)
wg.Done()
}
// 读取管道数据
func readData(ch chan int) {
for v := range ch {
fmt.Printf("【读取】数据 %v 成功\n", v)
time.Sleep(time.Millisecond * 10)
}
wg.Done()
}
func main() {
// 这里的容量可以设置为1,也不会有问题
ch := make(chan int, 10)
wg.Add(1)
go writeData(ch)
wg.Add(1)
go readData(ch)
wg.Wait()
}
分析:
for , for range 都会读取chan 里面的数据,所以chan的大小可以设置为1
- 需求:求出指定范围的素数,把所有的数放在一个协程里面(inChan),判断素数的协程从里面(inChan)取数据,放到(primeChan)里面,判断素数的协程可以开很多个,然后通过另外的协程打印(primeChan)里面的数据;需要注意的地方是:
- 一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做素数。素数又叫质数
- 判断素数协程有很多个,怎么才能知道这里的协程全部运行完毕,就需要一个(exitChan)来获取开辟的协程数,通过这个协程数来判断是否完全执行完毕,看下面的代码
- channel 是协程安全的
// 放入全部自然数 到 inChan 管道里面
func putNum(inChan chan int, maxNum int) {
for i := 2; i <= maxNum; i++ {
inChan <- i
}
defer func() {
close(inChan)
wg.Done()
}()
}
// 判断自然数
func primeNum(inChan chan int, primeChan chan int, exitChan chan bool) {
for num := range inChan {
flag := true
for i := 2; i < num; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
// fmt.Printf("素数:%v \n", num)
primeChan <- num
}
}
exitChan <- true
wg.Done()
}
// 打印素数
func printPrime(primeChan chan int) {
for v := range primeChan {
fmt.Println(v)
}
wg.Done()
}
// 判断函数primeNum开了几个协程,然后通过判断exitChan的状态来关闭primeChan 管道
// 如果使用len(exitChan) 求出为16个长度,也代表primeNum的函数协程执行完成,但没有阻塞作用,性能不好
func checkExitFlag(exitChan chan bool, primeChan chan int) {
for i := 0; i < 16; i++ {
<-exitChan
}
close(primeChan)
close(exitChan)
wg.Done()
}
var wg sync.WaitGroup
func main() {
// 思考为什么只要1000个容量就够了;
inChan := make(chan int, 1000)
primeChan := make(chan int, 1000)
exitChan := make(chan bool, 16)
start := time.Now().UnixMilli()
wg.Add(1)
go putNum(inChan, 1000000)
for i := 0; i < 16; i++ {
wg.Add(1)
go primeNum(inChan, primeChan, exitChan)
}
wg.Add(1)
go printPrime(primeChan)
wg.Add(1)
go checkExitFlag(exitChan, primeChan)
wg.Wait()
end := time.Now().UnixMilli()
fmt.Println("main run time = ", end-start)
}
10.2 单向管道
只能读,或者写的管道,在函数参数中限定,主要在函数参数中使用
func Fn1(ch chan<- int) {
for i := 0; i < 5; i++ {
ch <- i
fmt.Println("写入:", i)
time.Sleep(time.Millisecond * 20)
}
close(ch)
wg.Done()
}
func Fn2(ch <-chan int) {
for v := range ch {
fmt.Println("读取:", v)
time.Sleep(time.Millisecond * 20)
}
wg.Done()
}
var wg sync.WaitGroup
func main() {
var ch = make(chan int, 10)
wg.Add(1)
go Fn1(ch)
wg.Add(1)
go Fn2(ch)
wg.Wait()
}
select多路复用
- 传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock,在实际开发中,可能我们不好确定什么关闭该管道。
- 你也许会写出如下代码使用遍历的方式来实现:
for {
ch1 := <- ch1
ch2 := <- ch2
}
- 这种方式虽然可以实现从多个管道接收值的需求,但是运行性能会差很多。为了应对这种场景,Go 内置了 select 关键字,可以同时响应多个管道的操作。
- 使用select多路复用, 不需要关闭管道, 需要配合for使用,下面是一个完整的列子
func main() {
var intChan = make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
var stringChan = make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello " + fmt.Sprintf("%d", i)
}
for {
select {
case v := <-intChan:
fmt.Println("从intChan 读取数据:", v)
case v := <-stringChan:
fmt.Println("从stringChan 读取数据:", v)
default:
fmt.Println("数据读取完毕")
return
}
}
}
goroutine panic处理
当一个程序有多个协程的话,如果一个协程有错误,不经过recover来接收,就会使其他的协程也会不运行, 但我用这里还是有些错误
func sayHello() {
for i := 0; i < 10; i++ {
fmt.Println("hello")
time.Sleep(time.Millisecond *10)
}
}
func test() {
var map1 map[string]string
map1["username"] = "aaaa" //非法的,因为没有分配空间
defer func() {
// 捕获test报出的panic
if err := recover(); err != nil {
fmt.Println("test() 发生错误,", err)
}
}()
}
func main() {
go sayHello()
go test()
// 延时退出
time.Sleep(time.Second * 10)
}
10.3 goroutine 互斥锁 读写互斥锁
互斥锁
互斥锁是传统并发编程中对共享资源进行访问控制的主要手段,它有标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock;
- 来看一个例子
import (
"fmt"
"sync"
"time"
)
var count = 0
var wg sync.WaitGroup
var mutex sync.Mutex
func test() {
main()
count++
fmt.Println("the count is : ", count)
time.Sleep(time.Millisecond)
wg.Done()
}
func main() {
for i := 0; i < 20; i++ {
wg.Add(1)
go test()
}
wg.Wait()
}
其中:通过go run -race main.go 运行后,最后面会出现Found 1 data race(s) 代表发现1个数据竞争,解决这个问题就需要在修改全局变量的地方加上互斥锁
列子
- 编写一个函数,来计算各个数的阶乘,并放入到 map 中
- 启动多个协程,将统计的将结果放入到 map 中
var (
numMap = make(map[int]int)
wg sync.WaitGroup
)
func test(num int) {
sum := 1
for i := 1; i <= num; i++ {
sum *= i
}
numMap[num] = sum
fmt.Printf("numMap key = %v, value = %v \n", num, numMap[num])
wg.Done()
}
func main() {
for r := 1; r <= 20; r++ {
wg.Add(1)
go test(r)
}
wg.Wait()
}
- 互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个 goroutine 可以访问共享资源。Go 语言中使用 sync 包的 Mutex 类型来实现互斥锁。 使用互斥锁来修复上面代码的问题:
var (
numMap = make(map[int]int)
wg sync.WaitGroup
mutex sync.Mutex
)
func test(num int) {
sum := 1
for i := 1; i <= num; i++ {
sum *= i
}
// 锁住,其他协程的就不能写入这个map,具体这个放在那里,
// 应该就是在修改这个变量之前锁住是最好的方式
mutex.Lock()
numMap[num] = sum
mutex.Unlock()
fmt.Printf("numMap key = %v, value = %v \n", num, numMap[num])
wg.Done()
}
func main() {
for r := 1; r <= 20; r++ {
wg.Add(1)
go test(r)
}
wg.Wait()
}
读写互斥锁
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的,当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择。读写锁在 Go 语言中使用 sync 包中的 RWMutex 类型。
读写锁分为两种:读锁和写锁。当一个 goroutine 获取读锁之后,其他的 goroutine 如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个 goroutine 获取写锁之后,其他的goroutine 无论是获取读锁还是写锁都会等待。
第十一章:反射
第十二章:文件目录操作