Python爬虫实战--(一)解析网页中的元素
- 一使用BeaurifulSoup解析网页
- 二描述要爬取的东西在哪
- 三筛选需要的信息
- 总结
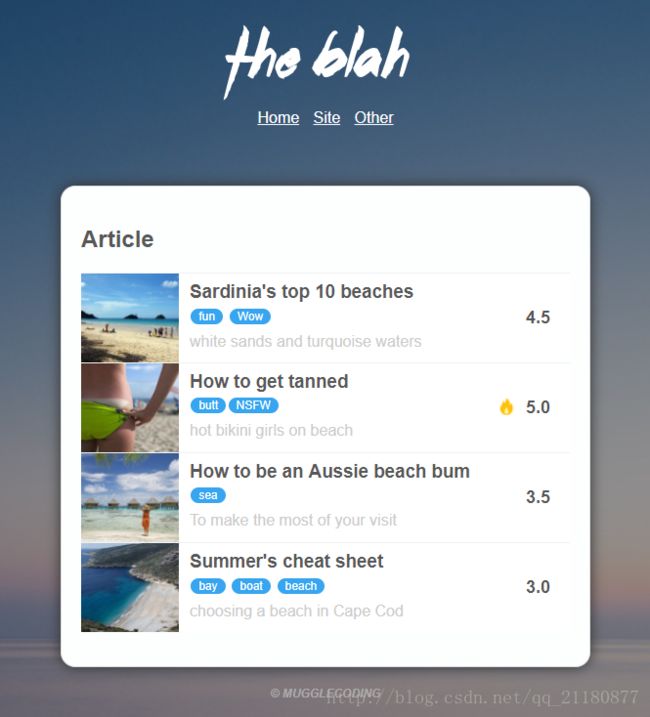
目标:对一个本地自己写的网页来解析其中的内容,筛选出评分大于等于4分的文章。网页如下图所示,每篇文章包含标题、图片、分类、评分和描述五个部分。
解析过程可以大致划分为三个步骤:
- 使用BeaurifulSoup解析网页
- 描述要爬取的东西在哪
- 从标签中获得我们需要的信息
一、使用BeaurifulSoup解析网页
首先要导入python第三方库
from bs4 import BeautifulSoup使用BeaurifulSoup解析网页的核心代码如下,其中html指的是一个html文件,参数“lxml”代表了使用lxml解析库来进行解析。除了lxml外还有其它的解析库,此处使用lxml。这行代码可以结合它的英文名字来进行理解,我们要得到一碗汤,我们需要食材–>html和食谱–lxml来进行制作。
Soup = BeautifulSoup(html, 'lxml')我们通过以下代码来得到我们自己编写的网页的Soup,将Soup输出我们可以得到网页的html源码。
path = './web/new_index.html'
with open(path, 'r') as f:
Soup = BeautifulSoup(f.read(), 'lxml')
print(Soup)<html>
<head>
<link rel="stylesheet" type="text/css" href="new_blah.css">
head>
<body>
<div class="header">
<img src="images/blah.png">
<ul class="nav">
<li><a href="#">Homea>li>
<li><a href="#">Sitea>li>
<li><a href="#">Othera>li>
ul>
div>
<div class="main-content">
<h2>Articleh2>
<ul class="articles">
<li>
<img src="images/0001.jpg" width="100" height="91">
<div class="article-info">
<h3><a href="www.sample.com">Sardinia's top 10 beachesa>h3>
<p class="meta-info">
<span class="meta-cate">funspan>
<span class="meta-cate">Wowspan>
p>
<p class="description">white sands and turquoise watersp>
div>
<div class="rate">
<span class="rate-score">4.5span>
div>
li>
<li>
<img src="images/0002.jpg" width="100" height="91">
<div class="article-info">
<h3><a href="www.sample.com">How to get tanneda>h3>
<p class="meta-info">
<span class="meta-cate">buttspan><span class="meta-cate">NSFWspan>
p>
<p class="description">hot bikini girls on beachp>
div>
<div class="rate">
<img src="images/Fire.png" width="18" height="18">
<span class="rate-score">5.0span>
div>
li>
<li>
<img src="images/0003.jpg" width="100" height="91">
<div class="article-info">
<h3><a href="www.sample.com">How to be an Aussie beach buma>h3>
<p class="meta-info">
<span class="meta-cate">seaspan>
p>
<p class="description">To make the most of your visitp>
div>
<div class="rate">
<span class="rate-score">3.5span>
div>
li>
<li>
<img src="images/0004.jpg" width="100" height="91">
<div class="article-info">
<h3><a href="www.sample.com">Summer's cheat sheeta>h3>
<p class="meta-info">
<span class="meta-cate">bayspan>
<span class="meta-cate">boatspan>
<span class="meta-cate">beachspan>
p>
<p class="description">choosing a beach in Cape Codp>
div>
<div class="rate">
<span class="rate-score">3.0span>
div>
li>
ul>
div>
<div class="footer">
<p>© Mugglecodingp>
div>
body>
html>
二、描述要爬取的东西在哪
现在我们得到了网页的html源码,我们需要一种方法来描述我们想要爬取的东西在html源码中的哪个地方。譬如我们现在要获取第一篇文章的评分的位置,我们在浏览器中选中评分,右键点击审查,然后在弹出的html源码中右键选择Copy–>Copy selector。我们在任意地方粘贴可以得到下面这行文字:
body > div.main-content > ul > li:nth-child(1) > div.rate > span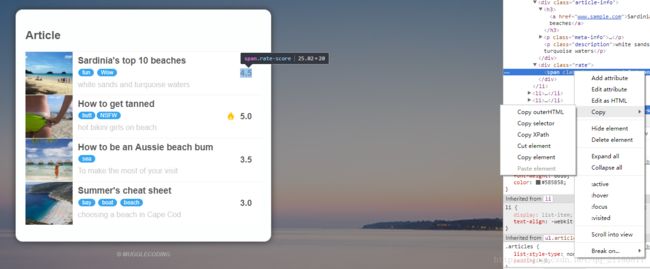
这行文字其实就是一个层级关系,描述了我们想要获取的内容在html中的由外层到内层的位置/路径信息。
结合前面得到的Soup,我们使用以下代码就可以获取第一篇文章的评分对应的html代码。select函数也很好理解,我们现在有一个完整的html源码,我们要想从其中获得一部分则我们需要提供这一部分代码在整个代码当中的位置。而这个位置信息我们通过selector这种描述形式来提供。(代码中的selector和上面的selector稍有不同,将nth-child改为了nth-of-type,否则会报错)
rate = Soup.select('body > div.main-content > ul > li:nth-of-type(1) > div.rate > span')
print(rate)得到如下的结果:
[<span class="rate-score">4.5span>]上面的代码我们只提取了第一篇文章的评分,如果我们想提取所有文章的评分,我们只需要将“nth-of-type(1)”这部分去掉就可以了。这样的话代码会对ul下的每一个li进行遍历来提取对应位置的信息(原来只会提取第一个li对应位置的信息)。
rates = Soup.select('body > div.main-content > ul > li > div.rate > span')
print(rates)[<span class="rate-score">4.5span>, <span class="rate-score">5.0span>, <span class="rate-score">3.5span>, <span class="rate-score">3.0span>]可见所有的评分信息都被提取出来了。同理我们依次处理标题、图片链接、分类和描述:
titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
pics = Soup.select('body > div.main-content > ul > li > img')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select('body > div.main-content > ul > li > div.rate > span')
cates = Soup.select('body > div.main-content > ul > li > div.article-info > p.meta-info')
print(titles,pics,descs,rates,cates,sep='\n-------------------------\n')得到如下结果:
[<a href="www.sample.com">Sardinia's top 10 beachesa>, <a href="www.sample.com">How to get tanneda>, <a href="www.sample.com">How to be an Aussie beach buma>, <a href="www.sample.com">Summer's cheat sheeta>]
-------------------------
[<img height="91" src="images/0001.jpg" width="100"/>, <img height="91" src="images/0002.jpg" width="100"/>, <img height="91" src="images/0003.jpg" width="100"/>, <img height="91" src="images/0004.jpg" width="100"/>]
-------------------------
[<p class="description">white sands and turquoise watersp>, <p class="description">hot bikini girls on beachp>, <p class="description">To make the most of your visitp>, <p class="description">choosing a beach in Cape Codp>]
-------------------------
[<span class="rate-score">4.5span>, <span class="rate-score">5.0span>, <span class="rate-score">3.5span>, <span class="rate-score">3.0span>]
-------------------------
[<p class="meta-info">
<span class="meta-cate">funspan>
<span class="meta-cate">Wowspan>
p>, <p class="meta-info">
<span class="meta-cate">buttspan><span class="meta-cate">NSFWspan>
p>, <p class="meta-info">
<span class="meta-cate">seaspan>
p>, <p class="meta-info">
<span class="meta-cate">bayspan>
<span class="meta-cate">boatspan>
<span class="meta-cate">beachspan>
p>]要注意的是一篇文章对应了多个分类,譬如第一篇文章对应的两个分类的html源码如下:
<p class="meta-info">
<span class="meta-cate">funspan>
<span class="meta-cate">Wowspan>
p>我们要获取一篇文章的所有分类所以我们的位置信息描述停在p.meta-info这一层,从而得到上面的结果。
三、筛选需要的信息
现在我们得到了每一篇文章对应的标题、图片、评分、分类、描述五个部分的html源码,但我们想要的是其中的内容。因而我们要对第二步得到的结果进行进一步地筛选,剔除掉我们不需要的html标签,得到我们想要的文本信息。
使用get_text()方法来获取标签中包含的文本信息:
for title in titles:
print(title.get_text())Sardinia's top 10 beaches
How to get tanned
How to be an Aussie beach bum
Summer's cheat sheet可以看到标签部分已经被去除,我们得到了其中的文本信息。对于描述和评分部分也是一样,使用get_text()来获取文本。
使用get(‘xxx’)来获得属性内容:
对于图片部分,没有文本信息。假设我们要提取它的src属性的内容,则可以使用get(‘src’)来获得它的src属性内容。
使用stripped_strings获得父级标签下所有子标签的文本信息:
对于分类部分,由于一篇文章对应多个分类,所以我们把分类标签及其父标签一同提取了出来。我们可以用stripped_strings来获得父标签下所有子标签的文本信息,然后将其转换为一个列表来得到我们想要的多种分类信息。
综上所述对于文章五个部分的处理筛选代码如下所示,我们使用一个字典来对每一篇文章进行封装:
data = []
for title, pic, desc, rate, cate in zip(titles, pics, descs, rates, cates):
info = {
'title': title.get_text(),
'pic': pic.get('src'),
'descs': desc.get_text(),
'rate': rate.get_text(),
'cate': list(cate.stripped_strings)
}
data.append(info)
print(data)[
{'title': "Sardinia's top 10 beaches", 'pic': 'images/0001.jpg', 'descs': 'white sands and turquoise waters', 'rate': '4.5', 'cate': ['fun', 'Wow']},
{'title': 'How to get tanned', 'pic': 'images/0002.jpg', 'descs': 'hot bikini girls on beach', 'rate': '5.0', 'cate': ['butt', 'NSFW']},
{'title': 'How to be an Aussie beach bum', 'pic': 'images/0003.jpg', 'descs': 'To make the most of your visit', 'rate': '3.5', 'cate': ['sea']},
{'title': "Summer's cheat sheet", 'pic': 'images/0004.jpg', 'descs': 'choosing a beach in Cape Cod', 'rate': '3.0', 'cate': ['bay', 'boat', 'beach']}
]现在我们已经把文章的五部分信息完整地提取了出来,之后简单地删选出评分大于等于4分的文章就可以了。
for i in data:
if float(i['rate']) >= 4:
print(i['title'],i['rate'])Sardinia's top 10 beaches 4.5
How to get tanned 5.0最后给出程序的完整代码:
from bs4 import BeautifulSoup
data = []
path = './web/new_index.html'
with open(path, 'r') as f:
Soup = BeautifulSoup(f.read(), 'lxml')
titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
pics = Soup.select('body > div.main-content > ul > li > img')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select('body > div.main-content > ul > li > div.rate > span')
cates = Soup.select('body > div.main-content > ul > li > div.article-info > p.meta-info')
# print(titles,pics,descs,rates,cates,sep='\n-------------------------\n')
for title, pic, desc, rate, cate in zip(titles, pics, descs, rates, cates):
info = {
'title': title.get_text(),
'pic': pic.get('src'),
'descs': desc.get_text(),
'rate': rate.get_text(),
'cate': list(cate.stripped_strings)
}
data.append(info)
# print(data)
for i in data:
if float(i['rate']) >= 4:
print(i['title'],i['rate'])
总结
1、使用BeaurifulSoup解析网页
Soup = BeautifulSoup(html, 'lxml')2、爬取部分信息
Soup.select('selector')3、进一步筛选出文本信息
get_text()获得文本信息
get('xxx')获得属性内容
stripped_strings获得父级标签下所有子标签的文本信息
Beautiful Soup文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/