电子商务网站商品推荐案例分析
本案例的主要目的是通过分析用户和网站数据,使用数据挖掘技术,分析老客户忠诚度下降的原因。
建立客户忠诚度模型,提高其忠诚度。
一、分析方法和过程
数据来源:客户信息、交易信息分别存放在网站数据库的客户表、订单表、订单明细中。
数据抽取:去除不需要的电话、身份证等不重要信息,抽取重要信息,如反应客户个人身份背景、学历等反应其交易心理的相关信息。
数据转换:将抽取的信息转换成能被数据挖掘算法使用的格式,放入数据仓库中。
忠诚度计算方法:
1、忠诚:
2、忠诚变不忠诚:
3、不忠诚变忠诚:
4、不忠诚:
本月消费比前半年月平均消费降低50%,则忠诚度降一级;
本月消费比前半年月平均消费提升20%,则忠诚度升一级。
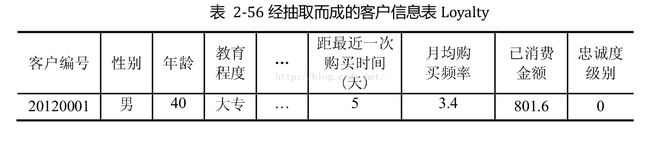
抽取之后的客户信息表如下图:
用户数据不全面的处理:用户数据填写的不全面,重要信息可能缺失。
处理方式:根据专家系统填入缺省值、平均值、
数据转换:如果使用ID3/C45,需要将源数据进行离散化处理。根据统计经验,上图的离散化结果如下图:

本案例基于ID3进行忠诚度分类:(属性值是点值,可以用KNN分类;属性值是范围值,用ID3/C45分类)。
根据ID3算法:输入为上述已分好类的样本数据集,输出是代表分类规则的二叉树或者多叉树。
客户群细分:
1、客户群细分,是根据客户行为特征或者公共属性将客户划分成同类群种的过程。目的是为营销人员实现更加精准的营销策略、为企业提供更好的营销战略做支撑。
2、在客户细分的基础上,再简历客户行为模型,建立其更加细化的、具有相同消费行为的微小群体,就能实现更加精准的营销策略、广告投放策略、商品推荐策略。虽然离一对一的营销还有具体,但对企业制定营销战略已经具有非常强的指导意义。
3、客户群细分可以采用人口统计学变量:年龄、性别、收入、职业、教育背景,这个可以作为初始条件。也可以采用购买行为特征变量:购买量、购买类型、购买频次。
两者的区别是:没有购买行为或者购买行为数据很难获取的情况下,比如低频次需求(装修),采用更加稳定的人口统计学变量。如果购买行为数据容易获取,则建议采用购买行为作为特征变量。另外,如果是非常重要的客户群划分,比如投资风险偏好,则最好让用户自己输入,更加能反应用户真实需求,避免机器分类与人主观愿望上的差别,也能避免法律上的纠纷。
4、客户群细分,可以采用分类或者聚类实现。分类实现时,则需要营销人员提供已经分好类的样本;聚体实现时,则自动对客户群进行分类。
5、决策树等分类算法易于理解,但受限样本划分准确度的影响,即样本划分准确度会对分类解决产生重大影响。聚类算法没有先验知识,依靠算法人员的经验和反复迭代得出结果,有时能得出营销人员没有发现的事实。
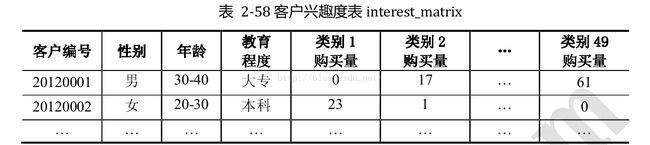
6、处理过程类似客户忠诚度分类:从数据库表单中提取数据;采用、去噪、清理;填入缺省值或者舍去;离散化变换;处理后的数据形如下表:
7、基于此表进行Kmeans聚类。聚类是为了推荐商品做准备的。聚类结果写入user cluster表、cluster info,分别记录客户的分类(字段为客户编号、类编号)、客户类别所有客户的商品购买信息(字段为类编号、商品编号、购买量)。
8、以上是根据用户相似度,推荐相似用户喜欢或者购买的商品。如果依据客户本身的历史行为做推荐,则可以挖掘大部分用户的频繁项集,然后根据当前用户最近的购买行为,计算商品之间的相似度或者关联性最强的商品,推荐给用户。
9、推荐系统的的首要目的:结果的正确性,这就牵涉到推荐正确率要尽量高。比如80%的正确率,也就意味着20%的错误率,即有20%的人群会被推荐他们根本不喜欢或者不感兴趣的商品,这种推荐效果产生的负面影响和损失是不好评估的。因此,我们开发的推荐系统,正确率要尽量高,尽量保持在95%以上。在这之上,提高推荐结果被用户喜欢的程度是提高点击转化率、购买转化率的关键因素。再进一步,如能跟用户实时交互,则能更加快速深入理解用户的需求,使推荐效果更好。
10、推荐系统不一定更需要这么复杂的计算过程。人工编辑的推荐商品目录也是一种,热门榜单也是推荐系统的一种。但是,如果想取得良好的个性化推荐效果,还是需要借助上述的自动化推荐系统,而非人工式推荐系统(专家推荐系统),这样能产生满足用户个性化(用户所属族群)要求的推荐结果。进一步,如果能实时计算用户的浏览、点击、收藏、购买行为,并求出用户特征,就能实现实时推荐效果,这种方式能有效提高网站的用户体验,提高购买转化率,甚至省略用户的搜索查找商品的过程。
11、实际使用过程中,这些推荐算法并不是相互矛盾排斥的,经常会综合实用,取长补短,适应不同场景下的推荐要求。
结合多种推荐方案的推荐系统实例:针对商务网站,设计一套推荐系统。
1、在网站首页,根据统计方法,列出前10名的热销商品。给新用户和访问者(没有历史数据,同时又适应所有用户)最普世的推荐方案。
2、对已注册、有浏览数据的用户,提供更个性化的推荐结果。
3、基于用户分类,将同类用户中,其他用户购买的总商品数的前N推荐给当前用户。或者是这些商品的新品。
4、基于商品分类,找出当前用户购买历史商品中,最相似的商品推荐给用户,或者通过关联技术,找出关联商品推荐给用户,
5、关联规则需要的客户交易数据存放在网站数据库的订单表和订单明细表中,通过订单表编号到订单明细表中查找关联的商品,并挖掘出关联规则。
注意事项:
1、这里的客户忠诚度等级,可以替换为不同等级的购物欲望、电子设备发烧友、电话费消费额、手机流量等级、信用卡不同等级、股票/理财投资风险爱好不同等级、外卖送餐单价不同等级,等等形如不同等级的客户划分,商品划分的分类情况。
2、对客户忠诚度的划分,等价于对不同客户群的细分。划分出的客户群,必定对应不同的客户特征属性,根据这些特征属性,就可以采用不同营销策略,提高销售转化率;还可以采取不同的推荐商品,提高购买率;采取不同的广告展示策略、提高点击率。
3、数据特征向量过多,可以采用主成分分析、SVD奇异值分解方法降维;如果ID3过拟合,如何解决?
4、底层数据如何架构?应用层数据如何分析?数据仓库如何架构?
5、数据如何清洗?如何去噪?不完全数据如何填入缺省值,如何舍去?
6、如何计算商品、客户的相似度?
7、如何求最优化问题?针对什么情况?
8、Kmeans聚类计算量大,特别是用户和特征向量都很多的时候,聚类的速度会非常慢。而且计算最佳K值时,必须不断尝试,才能得到K值与所有样本点的误差和曲线,得到最佳K值,这个计算量也是非常巨大的。建议只在一段时间内运算一次,比如一个月,得出用户的分类情况后,就可通过ID3、KNN对待分类样本进行分类,降低运算量提高计算速度。
建立客户忠诚度模型,提高其忠诚度。
一、分析方法和过程
数据来源:客户信息、交易信息分别存放在网站数据库的客户表、订单表、订单明细中。
数据抽取:去除不需要的电话、身份证等不重要信息,抽取重要信息,如反应客户个人身份背景、学历等反应其交易心理的相关信息。
数据转换:将抽取的信息转换成能被数据挖掘算法使用的格式,放入数据仓库中。
忠诚度计算方法:
1、忠诚:
2、忠诚变不忠诚:
3、不忠诚变忠诚:
4、不忠诚:
本月消费比前半年月平均消费降低50%,则忠诚度降一级;
本月消费比前半年月平均消费提升20%,则忠诚度升一级。
抽取之后的客户信息表如下图:
用户数据不全面的处理:用户数据填写的不全面,重要信息可能缺失。
处理方式:根据专家系统填入缺省值、平均值、
数据转换:如果使用ID3/C45,需要将源数据进行离散化处理。根据统计经验,上图的离散化结果如下图:
本案例基于ID3进行忠诚度分类:(属性值是点值,可以用KNN分类;属性值是范围值,用ID3/C45分类)。
根据ID3算法:输入为上述已分好类的样本数据集,输出是代表分类规则的二叉树或者多叉树。
客户群细分:
1、客户群细分,是根据客户行为特征或者公共属性将客户划分成同类群种的过程。目的是为营销人员实现更加精准的营销策略、为企业提供更好的营销战略做支撑。
2、在客户细分的基础上,再简历客户行为模型,建立其更加细化的、具有相同消费行为的微小群体,就能实现更加精准的营销策略、广告投放策略、商品推荐策略。虽然离一对一的营销还有具体,但对企业制定营销战略已经具有非常强的指导意义。
3、客户群细分可以采用人口统计学变量:年龄、性别、收入、职业、教育背景,这个可以作为初始条件。也可以采用购买行为特征变量:购买量、购买类型、购买频次。
两者的区别是:没有购买行为或者购买行为数据很难获取的情况下,比如低频次需求(装修),采用更加稳定的人口统计学变量。如果购买行为数据容易获取,则建议采用购买行为作为特征变量。另外,如果是非常重要的客户群划分,比如投资风险偏好,则最好让用户自己输入,更加能反应用户真实需求,避免机器分类与人主观愿望上的差别,也能避免法律上的纠纷。
4、客户群细分,可以采用分类或者聚类实现。分类实现时,则需要营销人员提供已经分好类的样本;聚体实现时,则自动对客户群进行分类。
5、决策树等分类算法易于理解,但受限样本划分准确度的影响,即样本划分准确度会对分类解决产生重大影响。聚类算法没有先验知识,依靠算法人员的经验和反复迭代得出结果,有时能得出营销人员没有发现的事实。
6、处理过程类似客户忠诚度分类:从数据库表单中提取数据;采用、去噪、清理;填入缺省值或者舍去;离散化变换;处理后的数据形如下表:
7、基于此表进行Kmeans聚类。聚类是为了推荐商品做准备的。聚类结果写入user cluster表、cluster info,分别记录客户的分类(字段为客户编号、类编号)、客户类别所有客户的商品购买信息(字段为类编号、商品编号、购买量)。
8、以上是根据用户相似度,推荐相似用户喜欢或者购买的商品。如果依据客户本身的历史行为做推荐,则可以挖掘大部分用户的频繁项集,然后根据当前用户最近的购买行为,计算商品之间的相似度或者关联性最强的商品,推荐给用户。
9、推荐系统的的首要目的:结果的正确性,这就牵涉到推荐正确率要尽量高。比如80%的正确率,也就意味着20%的错误率,即有20%的人群会被推荐他们根本不喜欢或者不感兴趣的商品,这种推荐效果产生的负面影响和损失是不好评估的。因此,我们开发的推荐系统,正确率要尽量高,尽量保持在95%以上。在这之上,提高推荐结果被用户喜欢的程度是提高点击转化率、购买转化率的关键因素。再进一步,如能跟用户实时交互,则能更加快速深入理解用户的需求,使推荐效果更好。
10、推荐系统不一定更需要这么复杂的计算过程。人工编辑的推荐商品目录也是一种,热门榜单也是推荐系统的一种。但是,如果想取得良好的个性化推荐效果,还是需要借助上述的自动化推荐系统,而非人工式推荐系统(专家推荐系统),这样能产生满足用户个性化(用户所属族群)要求的推荐结果。进一步,如果能实时计算用户的浏览、点击、收藏、购买行为,并求出用户特征,就能实现实时推荐效果,这种方式能有效提高网站的用户体验,提高购买转化率,甚至省略用户的搜索查找商品的过程。
11、实际使用过程中,这些推荐算法并不是相互矛盾排斥的,经常会综合实用,取长补短,适应不同场景下的推荐要求。
结合多种推荐方案的推荐系统实例:针对商务网站,设计一套推荐系统。
1、在网站首页,根据统计方法,列出前10名的热销商品。给新用户和访问者(没有历史数据,同时又适应所有用户)最普世的推荐方案。
2、对已注册、有浏览数据的用户,提供更个性化的推荐结果。
3、基于用户分类,将同类用户中,其他用户购买的总商品数的前N推荐给当前用户。或者是这些商品的新品。
4、基于商品分类,找出当前用户购买历史商品中,最相似的商品推荐给用户,或者通过关联技术,找出关联商品推荐给用户,
5、关联规则需要的客户交易数据存放在网站数据库的订单表和订单明细表中,通过订单表编号到订单明细表中查找关联的商品,并挖掘出关联规则。
注意事项:
1、这里的客户忠诚度等级,可以替换为不同等级的购物欲望、电子设备发烧友、电话费消费额、手机流量等级、信用卡不同等级、股票/理财投资风险爱好不同等级、外卖送餐单价不同等级,等等形如不同等级的客户划分,商品划分的分类情况。
2、对客户忠诚度的划分,等价于对不同客户群的细分。划分出的客户群,必定对应不同的客户特征属性,根据这些特征属性,就可以采用不同营销策略,提高销售转化率;还可以采取不同的推荐商品,提高购买率;采取不同的广告展示策略、提高点击率。
3、数据特征向量过多,可以采用主成分分析、SVD奇异值分解方法降维;如果ID3过拟合,如何解决?
4、底层数据如何架构?应用层数据如何分析?数据仓库如何架构?
5、数据如何清洗?如何去噪?不完全数据如何填入缺省值,如何舍去?
6、如何计算商品、客户的相似度?
7、如何求最优化问题?针对什么情况?
8、Kmeans聚类计算量大,特别是用户和特征向量都很多的时候,聚类的速度会非常慢。而且计算最佳K值时,必须不断尝试,才能得到K值与所有样本点的误差和曲线,得到最佳K值,这个计算量也是非常巨大的。建议只在一段时间内运算一次,比如一个月,得出用户的分类情况后,就可通过ID3、KNN对待分类样本进行分类,降低运算量提高计算速度。