深入分析零拷贝的原理,彻底掌握Netty、Kafka、RocketMQ高效率读写的秘诀
文章目录
- 一、前言
- 二、纠正一些网络上流传的错误说法
- 2.1、错误说法一:零拷贝就是零复制或者零拷贝技术没有进行数据的复制操作,所以比较快。
- 2.2、错误说法二:DMA技术诞生后,零拷贝基于DMA,实现了绝对的零复制......
- 三、并不神秘的DMA
- 四、从操作系统理解用户空间和内核空间
- 4.1、操作系统
- 4.2、用户态和内核态
- 4.3、用户空间和内核空间
- 五、零拷贝究竟是什么?
- 5.1、初现端倪
- 5.2、优化数据传输流程
- 5.3、零拷贝成型
- 六、总结
一、前言
众所周知,常见的如NIO、Netty、Kafka、RocketMQ这些框架保持高效率读写的一个原因就是使用了零拷贝技术。如果想要深入研究这些框架,就需要先掌握零拷贝的原理。
比如kafka为什么可以如此高效的读写数据,主要有如下三个原因:
-
kafka本身是分布式集群,同时又采用了分区技术,具有较高的并发度。
-
数据可以顺序写入磁盘,Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。
-
使用了零拷贝技术。
这三个原因里,前两个比较好理解,一方面因为分布式集群模式同时又采用了分区技术,可以有很好的并发读写数据能力;另一方面在kafka官网也提供了数据表明在同样的磁盘下顺序写能到 600M/s,而随机写只有 100K/s,这 与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
但是最后一个零拷贝技术就不是这么容易理解了,下面让我们一起追本溯源,从操作系统底层开始探究零拷贝的奥秘!
二、纠正一些网络上流传的错误说法
2.1、错误说法一:零拷贝就是零复制或者零拷贝技术没有进行数据的复制操作,所以比较快。
从拷贝这个音译词汇的翻译来看,拷贝确实就是复制的意思,但是零拷贝绝对不是零复制,零复制很容易让人以为它进行了0次复制,其实是不对的。下面让我们看下维基百科的解释:
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another.
翻译过来就是说“零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源,这个时候cpu可以干别的事情,至于数据的复制次数只能降低,而不会减少到0(后面会用例子说明)。
到这里第一个错误说法就更正了:零拷贝不是指0次复制而是指0次调用CPU消耗资源。
2.2、错误说法二:DMA技术诞生后,零拷贝基于DMA,实现了绝对的零复制…
首先这个观点直白来讲并没有错误,零拷贝技术确实基于DMA才能实现。但是很多文章讲零拷贝都会先讲传统的文件输入输出,然后引出DMA,最后得出类似的结论。有两个容易让人弄混的点需要强调一下:
- 即使是传统的read和write也会用到DMA,DMA并不神秘;
- 和错误说法一一样,零拷贝不是0次复制。
三、并不神秘的DMA
DMA全称是Direct Memory Access,也就是直接存储器访问。它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。通俗点理解,就是让硬件可以跳过CPU的调度,直接访问主内存。
比如我们常见的磁盘控制器、显卡、网卡、声卡都是支持DMA的,可以说DMA已经彻底融入我们的计算机世界了。
从零拷贝技术的角度来看,DMA的知识我们了解这么多就足够了,不需要关心它内部是怎么处理和实现的。
四、从操作系统理解用户空间和内核空间
如果想要真正弄明白零拷贝技术,就要先熟悉用户空间和内核空间的概念,而熟悉用户空间和内核空间就需要先掌握用户态和内核态的概念,而熟悉用户态和内核态就需要从操作系统说起。

4.1、操作系统
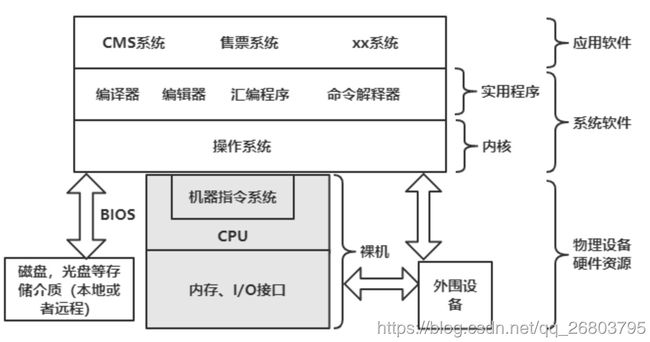
操作系统是由"硬件"和"软件"两部分组成。
硬件很好理解,以计算机系统为例,计算机硬件包括一个或多个处理器(CPU)、内存、键盘、显示器、磁盘、I/O接口以及其他一些外围设备比如打印机,绘图仪等等。 总之,计算机硬件部分是一个由多种电子和机械设备组成的硬件系统。
不是每个人都掌握所有这些硬件的,对于大部分人来说,这么多乱七八糟的硬件放在一起,根本不可能熟练的去使用,那怎么办呢?于是,为了让所有人都能方便正确的使用这些硬件设备,就需要编写若干程序来管理它们,正是这些程序组成了计算机的软件系统。
软件也可以分为两大类:系统软件和应用软件。工程师们首先直接在硬件上加载一层程序,用它来管理整个计算机硬件设备以及一些软件信息资源,同时还为用户提供开发应用程序的环境,这就是操作系统软件和实用软件。
应用软件是在操作系统支持下,为实现用户要求而编制的各种应用程序。
它们的关系可以概括为下图这样:
整体的蓝图诞生后,就需要定义一些概念了:
首先CPU、内存和I/O接口组成的主设备称为主机,把没有加载操作系统的主机叫做裸机。裸机与操作系统软件的接口是由CPU的指令系统和厂商提供的系统BIOS组成。
由于操作系统向用户隐藏了系统使用的硬件设备,因此操作系统要为它上面的应用系统软件提供一组命令或系统调用接口供用户程序使用。比如我们需要使用磁盘,可以通过系统命名或系统调用来间接完成,而不需要亲自手动编写一个磁盘设备驱动程序。因此对于用户来说,当计算机加载操作系统后,用户不直接与计算机硬件打交道,而是利用操作系统提供的命令和功能区使用计算机。
由于操作系统处于硬件和软件的中央位置,因此我们可以把操作系统称为计算机系统软件的核心,简称核心或内核。
4.2、用户态和内核态
知道了操作系统的大概组成之后,我们要思考一个问题:怎么让操作系统区分”普通用户“和”超级管理员“,也就是怎么给操作系统加一个“儿童模式” ?既能让不关心内核的普通用户可以任性的干自己的事情而不损害内核,又能让内核系统能任性的执行一系列特权指令。
于是,用户态和内核态诞生了。
从系统安全和保护的角度出发,在进行计算机体系结构设计时,处理机的执行模式一般设定为两种:分别称为内核模式(内核态)和用户模式(用户态)。
-
内核态:当处理机处于内核模式执行时,意味着系统除了可以执行一般指令外,还可以执行特权指令,即可以执行访问各种控制寄存器的指令、I/O指令以及程序状态字。
-
用户态:当处理机处于用户模式执行时,只能执行一般指令,而不允许执行特权指令。
这样做可以保护核心代码不受用户程序有意和无意的攻击。可以肯定的是,在系统运行期间需要在内核模式和用户模式之间不断的进行切换。
4.3、用户空间和内核空间
理解了用户态和内核态之后,用户空间和内核空间就可以用一句话概括了:用户空间就是用户进程所在的内存区域,处于用户态的程序只能访问用户空间;内核空间就是操作系统占据的内存区域,处于内核态的程序可以访问用户空间和内核空间。
五、零拷贝究竟是什么?
既然已经弄明白了DMA、用户空间、内核空间,那零拷贝就会变的很容易理解了。下面我们从一个问题出发,层层递进的来分析。
5.1、初现端倪
问题:如下是最传统的read和send文件处理操作伪代码,一共有几次数据复制和CPU调用?
File.read(file, buf, len);
Socket.send(socket, buf, len);
回答之前先来看一下数据传递的过程:
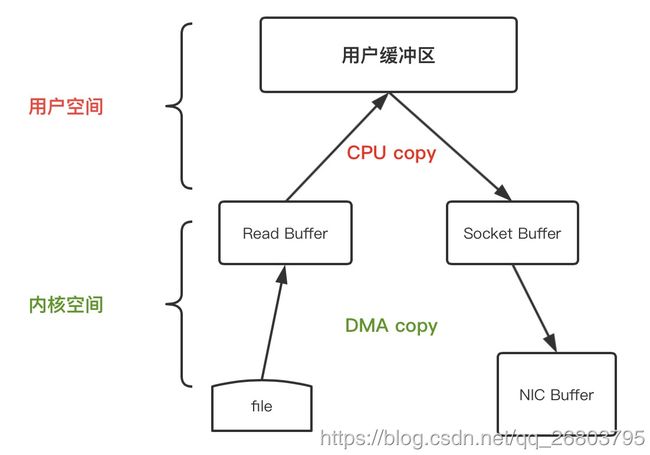
答案是:4次数据复制,2次cpu调用。
没想到吧,其实基础的read和send也用到了DMA技术,不过这个过程是不消耗cpu的。
下面为了加深理解,我们详细解释下这4步:
-
首先应用程序中调用
read()方法,这里会涉及到一次上下文切换(用户态->内核态),底层采用DMA技术读取磁盘的文件,并把内容存储到内核空间的读取缓存区。 -
通过前面的学习,我们知道处于用户空间的应用程序无法读取内核空间的数据,如果应用程序要操作这些数据,必须把这些内容从读取缓冲区拷贝到用户缓冲区。这个时候,
read()调用返回,且引发一次上下文切换(内核态->用户态),现在数据已经被拷贝到了用户地址空间缓冲区。(其实这个时候应用程序可以根据需求操作修改这些内容) -
我们最终目的是把这个文件内容通过Socket传到另一个服务中,调用Socket的
send()方法,这里又涉及到一次上下文切换(用户态->内核态),这时候,文件内容被进行第三次拷贝,被再次拷贝到内核地址空间缓冲区,但是这次的缓冲区与目标套接字相关联,与读取缓冲区没有任何关系。 -
send()调用返回,引发第四次的上下文切换,同时进行第四次的数据拷贝,通过DMA把数据从目标套接字相关的缓存区传到相关的协议引擎进行发送。
通过上面的详细分析,不难明白,过程1和4是由DMA负责,并不会消耗CPU,只有过程2和3的拷贝需要CPU参与,但是整个过程还是需要进行4次的数据复制。
5.2、优化数据传输流程
当我们面对海量的数据需要处理时,频繁的数据复制会浪费很多资源和时间,那上一小节的数据传输能不能进行优化呢?当然可以。
比如,当我们在应用程序中,不需要操作内容,过程2和3就是多余的,如果可以直接把内核态读取缓存冲区数据直接拷贝到套接字相关的缓存区,就可以起到优化的作用,如下图:
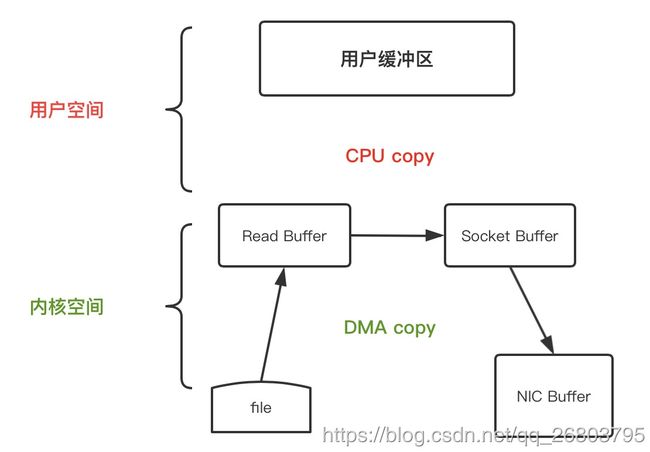
经过上图的优化,目前数据的复制次数从4次减少到了3次(2次DMA复制,1次cpu复制),并且上下文的切换次数也从4次减少到了2次。
其实这种优化并非空穴来风,在Java NIO里,FileChannel的transferTo() 方法就可以实现这个过程,该方法将数据从文件通道传输到给定的可写字节通道。对应的可以把file.read()和 socket.send() 替换为 transferTo() "
public void transferTo(long position, long count, WritableByteChannel target);
ps:其实在linux系统和unix系统里,这个调用被传递到 sendfile() 系统调用中,这样就实现了优化将数据从一个文件描述符传输到了另一个文件描述符。
5.3、零拷贝成型
我们知道零拷贝粗略来说就是0次CPU调用的意思,那上一小节,还是调用了1次cpu来复制数据,显示还达不到真正的零拷贝,那怎么优化呢?
到这里,如果还想优化,就需要底层网络接口支持收集操作才可以。
所以在Linux 内核 2.4 及后期版本中,工程师们针对套接字缓冲区描述符做了相应调整,使得DMA自带了收集功能,当然对于用户方面,用法还是一样的,但是内部操作已经发生了改变。过程如下图:
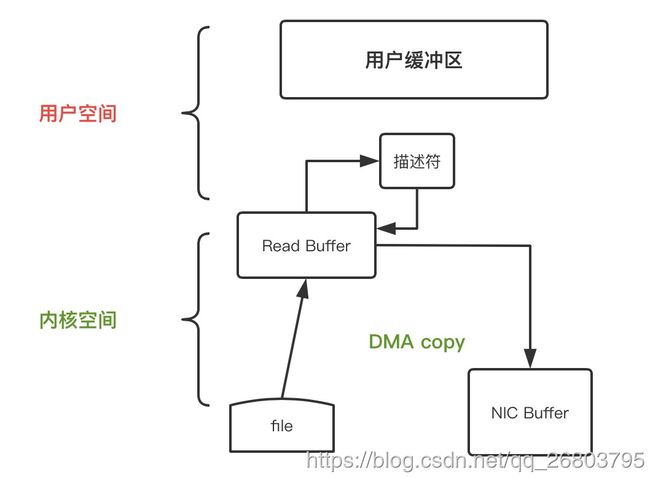
这时,数据的传输只需要两步就能搞定:
-
transferTo() 方法引发 DMA 将文件内容复制到内核读取缓冲区。
-
把包含数据位置和长度信息的描述符追加到套接字缓冲区,避免了内容整体的拷贝,DMA 引擎直接把数据从内核缓冲区传到协议引擎,全程都是DMA参与,从而消除CPU参与的数据复制消耗。
这样当传输一份数据到一个设备时使用零拷贝技术就可以只对数据复制2次,CPU调用0次,上下文切换2次。
六、总结
总体来说,零拷贝是指将数据直接从磁盘文件复制到内核读取缓冲区,然后多个消费者可以共用一个缓冲区,然后DMA 引擎直接把数据从内核读取缓冲区传到消费者,全程都是DMA参与,从而消除CPU参与的数据复制消耗,也不需要经由应用程序之手,减少了内核空间和用户空间之间的上下文切换,同时也大大减少了数据复制的次数。
以kafka为例,如果有100个消费者消费一份数据,在普通的数据传输方式下,复制次数一共是100*4 = 400次,cpu调用次数一共是100*2 = 200次;而使用了零拷贝技术之后,复制次数一共是100+1 = 101次(1次数据从磁盘到内核读取缓冲区,100次发送给100个消费者消费),cpu调用次数一共是0次。极大的提高了数据读写效率。