Denoising Distantly Supervised Open-Domain Question Answering
摘要
远距离监督的开放领域问答(DS-QA)的目的是在未标记文本的集合中找到答案。现有的DS-QA模型通常从大型语料库中检索相关段落,并应用阅读理解技术从最相关的段落中提取答案。他们忽略了其他段落中包含的丰富信息。此外,远距离监督的数据不可避免地会伴随着错误的标签问题,而这些嘈杂的数据将大大降低DS-QA的性能。为了解决这些问题,我们提出了一种新颖的DS-QA模型,该模型采用段落选择器过滤掉那些嘈杂的段落,并使用段落阅读器从那些去噪的段落中提取正确答案。实际数据集上的实验结果表明,与所有baselines相比,我们的模型可以从嘈杂的数据中捕获有用的信息,并在DS-QA上取得重大改进。本文的源代码和数据可以从https://github.com/thunlp/OpenQA获得。
1.介绍
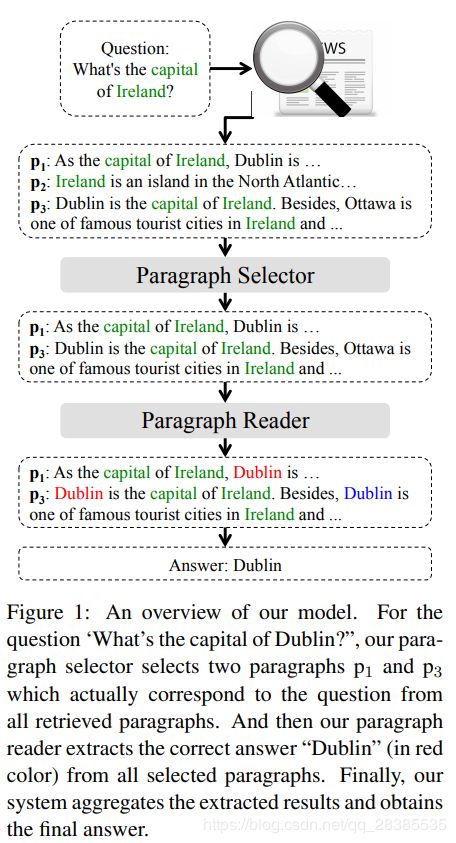
阅读理解旨在回答有关文档的问题,最近已成为NLP研究的重点。自从多层结构和注意力机制允许模型对问题进行推理,许多阅读理解系统被提出并取得了较好的结果。在某种程度上,阅读理解已显示出最新的神经模型具有阅读,处理和理解自然语言文本的能力。
尽管取得了成功,但现有的阅读理解系统仍依赖于预先确定的相关文本,而这些文本在现实世界中的问答系统中并不总是存在。因此,阅读理解技术不能直接应用于开放领域的QA任务。近年来,研究人员尝试使用大规模的未标记语料库来回答开放域问题。Chen et al. (2017) 提出了一种远距离监督的开放领域问答系统(DS-QA),该系统使用信息检索技术从Wikipedia中获取相关文本,然后应用阅读理解技术来提取答案。
尽管DS-QA提出了一种有效的策略来自动收集相关文本,但是它始终遭受噪声问题的困扰。例如,对于“Which country’s capital is Dublin?”这一问题,我们可能会遇到以下文本:(1)检索到的段落“Dublin is the largest city of Ireland …”实际上并未回答该问题;(2)检索到的段落“Dublin is the capital of Ireland. Besides, Dublin is one of the famous tourist cities in Ireland and …”中的第二个“Dublin”并非正确的答案。这些噪声段落和字符在DS-QA中被视为有效实例。为了解决这个问题,Choi et al. (2017)将DS-QA中的答案生成分为两个模块,包括选择文档中的目标段落和通过阅读理解从目标段落中提取正确答案。此外,Wang et al. (2018a)使用强化学习来共同训练目标段落选择和答案提取。
这些方法仅根据最相关的段落提取答案,这将丢失那些被忽略的段落中包含的大量丰富信息。实际上,正确的答案通常会在多个段落中提到,而问题的不同方面可能会在多个段落中得到回答。因此,Wang et al. (2018b)建议进一步明确汇总来自不同段落的证据,以对提取的答案进行重新排序。然而,重新排序方法仍然依赖于现有DS-QA系统获得的答案,并且不能充分解决DS-QA的噪声问题。
为了解决这些问题,我们为DS-QA提出了从粗到细的降噪模型。如图1所示,我们的系统首先通过信息检索从大型语料库中根据问题检索段落。之后,为了利用所有信息丰富的段落,我们采用了一个快速的段落选择器来浏览所有检索到的段落并过滤掉那些嘈杂的段落。然后,我们使用精确的段落阅读器对每个选定的段落进行仔细的阅读,以提取答案。最后,我们汇总所有选定段落的派生结果以获得最终答案。我们的方法中对段落选择器的快速浏览和对段落阅读器的密集阅读使DS-QA可以对嘈杂的段落进行降噪并保持效率。
在包括Quasar-T,SearchQA和TriviaQA的现实世界数据集上的实验结果表明,与所有baseline方法相比,我们的系统通过汇总所有内容丰富的段落的提取答案,实现了显着且一致的改进。特别是,我们表明,通过选择一些信息丰富的段落,我们的模型可以实现较好的性能,从而极大地加快了整个DS-QA系统的速度。我们将在Github上发布这项工作的所有源代码和数据集,以进行进一步的研究探索。
2.相关工作
问答是NLP中最重要的任务之一。在QA方面已经投入了很多努力,尤其是在开放领域的QA方面。开放领域QA最早是由(Green Jr et al., 1961)提出的。该任务旨在使用外部资源来回答开放领域的问题,例如文档集合,网页,结构化知识图谱或自动提取的关系三元组。
近年来,随着机器阅读理解技术的发展,研究人员试图通过对纯文本进行阅读理解来回答开放领域的问题。Chen et al. (2017) 提出了一种DS-QA系统,该系统从大型语料库中检索问题的相关文本,然后使用阅读理解模型从这些文本中提取答案。但是,在DS-QA中检索到的文本总是很嘈杂,这可能会损害DS-QA的性能。因此,Choi et al. (2017)和Wang et al. (2018a)尝试通过将问答分为段落选择和答案提取来解决DS-QA中的噪声问题,他们都只在所有检索到的段落中选择最相关的段落来提取答案,这丢失了那些被忽略的段落中包含的大量丰富信息。因此,Wang et al. (2018b)提出了基于强度和覆盖率的重新排名方法,该方法可以汇总现有DS-QA系统从每个段落中提取的结果,以更好地确定答案。但是,该方法依赖于现有DS-QA模型的预先提取的答案,并且由于仍然不加区别地考虑所有检索到的段落,因此仍然存在远程数据中的噪声问题。与这些方法不同,我们的模型采用段落选择器来过滤出那些嘈杂的段落并保留那些信息丰富的段落,从而可以充分利用嘈杂的DS-QA数据。
我们的工作还受到NLP中从粗到精模型的想法的启发。Cheng and Lapata (2016)和Choi et al. (2017) 提出了一种从粗到精的模型,该模型首先选择基本句子,然后分别对所选句子进行文本汇总或阅读理解。Lin et al. (2016)利用选择性注意聚合所有句子的信息以提取相关事实。Yang et al. (2016)提出了一个分层的注意力网络,在单词和句子层面上有两个层次的注意力用于文档分类。我们的模型还采用了从粗到精的模型来处理DS-QA中的噪声问题,该模型首先选择内容丰富的检索段落,然后从这些选定的段落中提取答案。
3.方法
在本节中,我们将详细介绍我们的模型。我们的模型旨在提取大规模未标记语料库中给定问题的答案。我们首先使用信息检索技术从开放领域语料库中检索与该问题相对应的段落,然后从这些检索的段落中提取答案。
形式上,给定一个问题 q = ( q 1 , q 2 , ⋅ ⋅ ⋅ , q ∣ q ∣ ) q=(q^1,q^2,···,q^{|q|}) q=(q1,q2,⋅⋅⋅,q∣q∣),我们将检索m个段落,定义为 P = { p 1 , p 2 , ⋅ ⋅ ⋅ , p m } P=\{p_1,p_2,···,p_m\} P={p1,p2,⋅⋅⋅,pm}的,其中 p i = ( p i 1 , p i 2 , ⋅ ⋅ ⋅ , p i ∣ p i ∣ ) p_i=(p^1_i,p^2_i,···,p^{|p_i|}_i) pi=(pi1,pi2,⋅⋅⋅,pi∣pi∣)是第 i i i个检索到的段落。我们的模型测量在给定问题 q q q和相应的段落集 P P P的条件下提取出答案 a a a的概率。如图1所示,我们的模型包含两个部分:
(1)段落选择器
给定问题 q q q和检索到的段落 P P P,段落选择器会测量所有检索到的段落的概率分布 P r ( p i ∣ q , P ) Pr(p_i|q,P) Pr(pi∣q,P),该概率分布用于选择确实包含问题 q q q答案的段落。
(2)段落阅读器
给定问题 q q q和段落 p i p_i pi,段落阅读器计算通过多层长短期记忆网络提取答案 a a a的概率 P r ( a ∣ q , p i ) Pr(a|q,p_i) Pr(a∣q,pi)。
总体而言,给定问题 q q q的条件下答案 a a a被提取的概率 P r ( a ∣ q , P ) Pr(a|q,P) Pr(a∣q,P)可以计算为:
P r ( a ∣ q , P ) = ∑ p i ∈ P P r ( a ∣ q , p i ) P r ( p i ∣ q , P ) . (1) Pr(a|q,P)=\sum_{p_i\in P}Pr(a|q,p_i)Pr(p_i|q,P).\tag{1} Pr(a∣q,P)=pi∈P∑Pr(a∣q,pi)Pr(pi∣q,P).(1)
3.1 段落选择器
由于DS-QA数据中不可避免地会出现错误的标注问题,因此在利用所有检索到的段落的信息时,我们需要过滤掉那些噪声段落。这很简单,我们只需要估计每个段落的置信度。因此,我们采用一个段落选择器来度量每个段落中包含答案的概率。
(1)段落编码
我们首先将段落 p i p_i pi中的每个单词 p i j p^j_i pij表示为单词向量 p i j \pmb p^j_i pppij,然后将每个单词向量带入神经网络以获得隐藏的表示形式 p ^ i j \hat{\pmb p}^j_i ppp^ij。在这里,我们采用两种类型的神经网络,包括:
1.多层感知器(MLP)
p ^ i j = M L P ( p i j ) , (2) \hat{\pmb p}^j_i=MLP(\pmb p^j_i),\tag{2} ppp^ij=MLP(pppij),(2)
2.循环神经网络(RNN)
{ p ^ i 1 , p ^ i 2 , ⋅ ⋅ ⋅ , p ^ i ∣ p i ∣ } = R N N ( { p i 1 , p i 2 , ⋅ ⋅ ⋅ , p i ∣ p i ∣ } ) , (3) \{\hat{\pmb p}^1_i,\hat{\pmb p}^2_i,···,\hat{\pmb p}^{|p_i|}_i\}=RNN(\{\pmb p^1_i,\pmb p^2_i,···,\pmb p^{|p_i|}_i\}),\tag{3} {ppp^i1,ppp^i2,⋅⋅⋅,ppp^i∣pi∣}=RNN({pppi1,pppi2,⋅⋅⋅,pppi∣pi∣}),(3)
其中 p ^ i j \hat{\pmb p}^j_i ppp^ij被编码为单词 p i j p^j_i pij及其周围单词的语义信息。对于RNN,我们选择一个单层双向长x短期记忆网络(LSTM)作为我们的RNN单元,并串联所有层的隐藏状态以获得 p ^ i j \hat{\pmb p}^j_i ppp^ij。
(2)问题编码
与段落编码类似,我们还将问题中的每个单词 q i q_i qi表示为其单词向量 q i \pmb q_i qqqi,然后将其带入MLP:
q ^ j = M L P ( q j ) , (4) \hat{\pmb q}^j=MLP(\pmb q^j),\tag{4} qqq^j=MLP(qqqj),(4)
或者RNN:
{ q ^ 1 , q ^ 2 , ⋅ ⋅ ⋅ , q ^ ∣ q ∣ } = R N N ( { q 1 , q 2 , ⋅ ⋅ ⋅ , q ∣ q ∣ } ) . (5) \{\hat{\pmb q}^1,\hat{\pmb q}^2,···,\hat{\pmb q}^{|q|}\}=RNN(\{\pmb q^1,\pmb q^2,···,\pmb q^{|q|}\}).\tag{5} {qqq^1,qqq^2,⋅⋅⋅,qqq^∣q∣}=RNN({qqq1,qqq2,⋅⋅⋅,qqq∣q∣}).(5)
其中 q ^ j \hat{\pmb q}^j qqq^j是单词 q j q^j qj的隐藏表示形式,表示为对其进行上下文信息的编码。之后,我们对隐藏的表示进行self-attention操作,以获得问题 q q q的最终表示 q \pmb q qqq:
q ^ = ∑ j α j q ^ j , (6) \hat{\pmb q}=\sum_j \alpha^j \hat{\pmb q}^j,\tag{6} qqq^=j∑αjqqq^j,(6)
其中 α j α_j αj编码每个疑问词的重要性,并计算为:
α j = e x p ( w b q i ) ∑ j e x p ( w b q j ) , (7) \alpha_j=\frac{exp(\pmb w_b\pmb q_i)}{\sum_j exp(\pmb w_b\pmb q_j)},\tag{7} αj=∑jexp(wwwbqqqj)exp(wwwbqqqi),(7)
其中 w \pmb w www是可学习的权重向量。
接下来,我们通过最大池化层和softmax层计算每个段落的概率:
P r ( p i ∣ q , P ) = s o f t m a x ( m a x j ( p ^ i j W q ) ) , (8) Pr(p_i|q,P)=softmax(\mathop{max}\limits_{j}(\hat{\pmb p}^j_i\pmb W\pmb q)),\tag{8} Pr(pi∣q,P)=softmax(jmax(ppp^ijWWWqqq)),(8)
其中 W \pmb W WWW是可学习的权重矩阵。
3.2 段落阅读器
段落阅读器旨在从段落 p i p_i pi中提取答案。与段落选择器类似,我们首先通过多层双向LSTM将每个段落 p i p_i pi编码为 { p ˉ i 1 , p ˉ i 2 , ⋅ ⋅ ⋅ , p ˉ i ∣ p i ∣ } \{\bar{\pmb p}^1_i,\bar{\pmb p}^2_i,···,\bar{\pmb p}^{|p_i|}_i\} {pppˉi1,pppˉi2,⋅⋅⋅,pppˉi∣pi∣}。并且我们还通过self-attention及多层双向LSTM获得了问题嵌入 q ˉ \bar{\pmb q} qqqˉ。
段落阅读器旨在提取最可能是正确答案的字符范围。然后将其划分为预测答案范围的开始和结束位置。因此,从给定的段落 p i p_i pi中提取问题 q q q的答案 a a a的概率可以计算为:
P r ( a ∣ q , p i ) = P s ( a s ) P e ( a e ) , (9) Pr(a|q,p_i)=P_s(a_s)P_e(a_e),\tag{9} Pr(a∣q,pi)=Ps(as)Pe(ae),(9)
其中 a s a_s as和 a e a_e ae表示段落中答案 a a a的开始和结束位置, P s ( a s ) P_s(a_s) Ps(as)和 P e ( a e ) P_e(a_e) Pe(ae)分别是 a s a_s as和 a e a_e ae作为开始词和结束词的概率,其计算公式为:
P s ( j ) = s o f t m a x ( p ˉ i j W s q ˉ ) , (10) P_s(j)=softmax(\bar{\pmb p}^j_i\pmb W_s\bar{\pmb q}),\tag{10} Ps(j)=softmax(pppˉijWWWsqqqˉ),(10)
P e ( j ) = s o f t m a x ( p ˉ i j W e q ˉ ) , (11) P_e(j)=softmax(\bar{\pmb p}^j_i\pmb W_e\bar{\pmb q}),\tag{11} Pe(j)=softmax(pppˉijWWWeqqqˉ),(11)
W s \pmb W_s WWWs和 W e \pmb W_e WWWe是两个要学习的权重矩阵。在DS-QA中,由于我们没有人工标记答案的位置,因此我们可能有段落中的多个字符与正确答案匹配。令 { ( a s 1 , a e 1 ) , ( a s 2 , a e 2 ) , ⋅ ⋅ ⋅ , ( a s ∣ a ∣ , a e ∣ a ∣ ) } \{(a^1_s,a^1_e),(a^2_s,a^2_e),···,(a^{|a|}_s,a^{|a|}_e)\} {(as1,ae1),(as2,ae2),⋅⋅⋅,(as∣a∣,ae∣a∣)}为段落 p i p_i pi中与答案 a a a匹配的开始和结束字符的位置集合。等式(9)进一步定义了两种方法:
(1)Max。也就是说,我们假设该段落中只有一个字符表示正确答案。在这个方法中,通过最大化所有候选标记的概率来定义提取的答案 a a a的概率:
P r ( a ∣ q , p i ) = m a x j P r s ( a s j ) P r e ( a e j ) (12) Pr(a|q,p_i)=\mathop{max}\limits_{j}\mathop{Pr}\limits_{s}(a^j_s)\mathop{Pr}\limits_{e}(a^j_e)\tag{12} Pr(a∣q,pi)=jmaxsPr(asj)ePr(aej)(12)
(2)Sum。在这个方法中,我们认为所有与正确答案匹配的字符都相等。我们将答案提取概率定义为:
P r ( a ∣ q , p i ) = ∑ j P r s ( a s j ) P r e ( a e j ) (13) Pr(a|q,p_i)=\sum_j\mathop{Pr}\limits_{s}(a^j_s)\mathop{Pr}\limits_{e}(a^j_e)\tag{13} Pr(a∣q,pi)=j∑sPr(asj)ePr(aej)(13)
我们的段落阅读器模型的灵感来自先前的机器阅读理解模型,即(Chen et al., 2016)中所述的Attentive Reader。实际上,其他阅读理解模型也可以很容易地用作我们的段落阅读器。由于篇幅所限,本文仅探讨Attentive Reader的有效性。
3.3 学习和预测
对于学习的目标,我们使用最大似然估计定义损失函数 L L L:
L ( θ ) = − ∑ ( a ˉ , q , P ) ∈ T l o g P r ( a ∣ q , P ) − α R ( P ) , (14) L(\theta)=-\sum_{(\bar a,q,P)\in T}log~Pr(a|q,P)-\alpha R(P),\tag{14} L(θ)=−(aˉ,q,P)∈T∑log Pr(a∣q,P)−αR(P),(14)
其中 θ θ θ表示模型的参数, a a a表示正确答案, T T T是整个训练集, R ( P ) R(P) R(P)是段落选择器上的正则化项,以避免其过拟合。在此, R ( P ) R(P) R(P)定义为 P r ( p i ∣ q , P ) Pr(p_i|q,P) Pr(pi∣q,P)与概率分布 X \mathcal X X之间的KL散度,其中如果段落 p i p_i pi包含正确答案,则 X i = 1 c P \mathcal X_i =\frac{1}{c_P} Xi=cP1( c P c_P cP是包含正确答案的段落数), 否则为0。具体地说, R ( P ) R(P) R(P)定义为:
R ( P ) = ∑ p i ∈ P X i l o g X i P r ( p i ∣ q , P ) . (15) R(P)=\sum_{p_i\in P}\mathcal X_ilog\frac{\mathcal X_i}{Pr(p_i|q,P)}.\tag{15} R(P)=pi∈P∑XilogPr(pi∣q,P)Xi.(15)
为了解决优化问题,我们采用如(Kingma and Ba, 2015)中所述的Adamax最小化目标函数。
在测试过程中,我们提取概率最高的答案 a ^ \hat a a^如下:
a ^ = a r g m a x a P r ( a ∣ q , P ) = a r g m a x a ∑ p i ∈ P P r ( a ∣ q , p i ) P r ( p i ∣ q , P ) (16) \hat a=\mathop{argmax}\limits_{a}Pr(a|q,P)\\ =\mathop{argmax}\limits_{a}\sum_{p_i\in P}Pr(a|q,p_i)Pr(p_i|q,P)\tag{16} a^=aargmaxPr(a∣q,P)=aargmaxpi∈P∑Pr(a∣q,pi)Pr(pi∣q,P)(16)
在这里,段落选择器可以看作是对所有段落的快速浏览,它确定了每个段落包含答案的概率分布。因此,我们可以简单地汇总那些具有较高概率的段落的预测结果,从而加速模型阅读。