Python爬取指定关键字的淘宝商品信息-Selenium
我们在新浪微博的抓取中,已经实现了ajax抓取的操作,详情请戳链接:https://blog.csdn.net/qq_29027865/article/details/83239316
但是对于一些ajax获取的数据,有些接口比较复杂,包含动态的参数等,如果没有办法及时分析出参数的规律,那么此时使用Selenium来抓取也是一个不错的选择。

一.搜索关键字

(1)首先引入selenium的库:
from selenium import webdriver(2)使用webdriver生成一个浏览器驱动:
browser = webdriver.Chrome()
#browser = webdriver.PhantomJS()注:需要提前将driver.exe添加到环境变量,下载路径请戳:
https://download.csdn.net/download/qq_29027865/10328885
https://download.csdn.net/download/qq_29027865/10328884
(3)请求淘宝首页:
browser.get('https://www.taobao.com')(4)因为加载页面需要时间,为了防止加载时间过长而出现报错,在这里加上一个判断加载是否成功的操作:
通过selenium官方文档找到waits方法,详情戳:https://selenium-python.readthedocs.io/
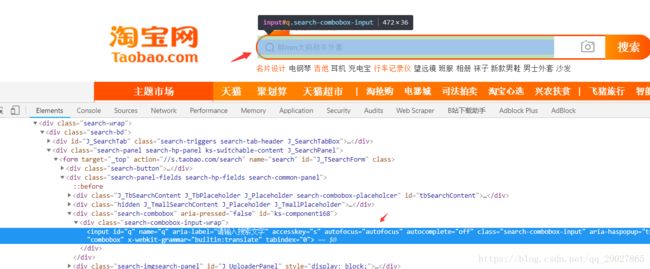
通过定位右键copy selector,可以得到输入框的css选择器的内容,同样方法获取到按钮的css选择器的内容,如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#定位等待使用presence_of_element_located
#定位点击使用element_to_be_clickable
#容易出现超时错误,加上超时异常来作为判断
def search():
try:
browser.get('https://www.taobao.com')
# 判断是否加载成功
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))
)
submit = WebDriverWait(browser,10).until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
input.send_keys('手机')
submit.click()
except TimeoutException:
return search()二.分析页码及翻页:

通过分析淘宝商品的页面,
如果是通过直接点击下一页来遍历每页,会存在一个问题:
遍历到最后一页时,程序会因找不到下一页这个selector而选择异常退出,这是最好的情况。但是如果在爬取过程中出现了异常退出,这时也没有记录当前的页数,就无法继续爬取后续对应的页面了。还需要在点击下一页获取中做异常检测,整个流程相对复杂,因此这里我们呢采取第二种方法来获取页面。

实现如下:
def next_page(page_number):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
)
submit = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page_number)
submit.click()
# 判断是否为当前页
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number)))
get_products()
except TimeoutException:
next_page(page_number)三.分析提取商品的内容
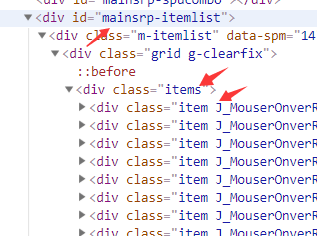
根据商品信息的源码,我们可以看出:每个商品都是一个item,它们在id为'mainsrp-itemlist'下的items的列表中:
1.首先判定这个items是否加载成功:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
2.通过pagesorce拿到网页源代码,并使用pyQyery来解析css;
3.获取商品值:attr获取属性值text()获取文本值,对于一些文本值,使用列表形式进行切割,[:-3]指从前面到倒数第三个:
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
# 通过page_source方法获取源代码
html = browser.page_source
# 初始化pyquery对象
doc = pq(html)
# 通过调用items的方法来得到一个生成器,遍历生成器,来逐个得到li节点的对象
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)完整代码如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
browser = webdriver.Chrome()
browser.set_window_size(1400,900)
wait = WebDriverWait(browser,10)
# 翻页的两种方法:1.下一页;2.输入到某页后点击确定
# 判断高亮的数字
def search():
print("正在搜索...")
try:
browser.get('https://www.taobao.com')
# 判断是否加载成功
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))
)
submit = WebDriverWait(browser,10).until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
input.send_keys('手机')
submit.click()
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:
return search()
# 自动翻页
def next_page(page_number):
print('正在翻页...',page_number)
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
)
submit = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page_number)
submit.click()
# 判断是否为当前页
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number)))
get_products()
except TimeoutException:
next_page(page_number)
# 解析方法
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
# 通过page_source方法获取源代码
html = browser.page_source
# 初始化pyquery对象
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text().strip()[2:],
'deal':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
def main():
try:
total = search()
# 提取出100的数字
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
next_page(i)
except Exception:
print("出错啦~")
finally:
browser.close()
if __name__ == '__main__':
main()
# 再加一个等待操作,这里实现得是分页得逻辑
# total = wait.until(EC.presence_of_element_located(By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total'))
# 返回内容