Python3爬取某教育平台题库保存为Word文档
最近在玩树莓派,所以趁有空复习下Python,碰巧一个朋友让我帮他打印下某教育平台的考题(已报名有账号密码的),记得上次让我帮忙打印前,花了一些钱让图文店手打整理才开始打印,现在想起真是千万只草尼玛在心中蹦踏,当时的自己蠢得可以..这次,花了大半天写了这个脚本,一来是帮朋友,二来也是在给自己找个机会练手。
^_^亲测可行!代码中使用的Cookie已去除,只记录过程
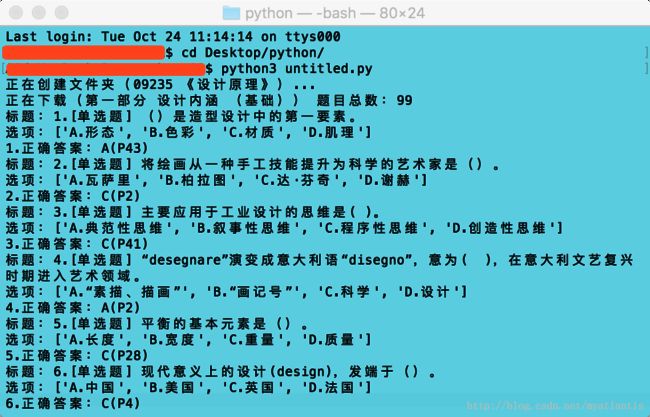

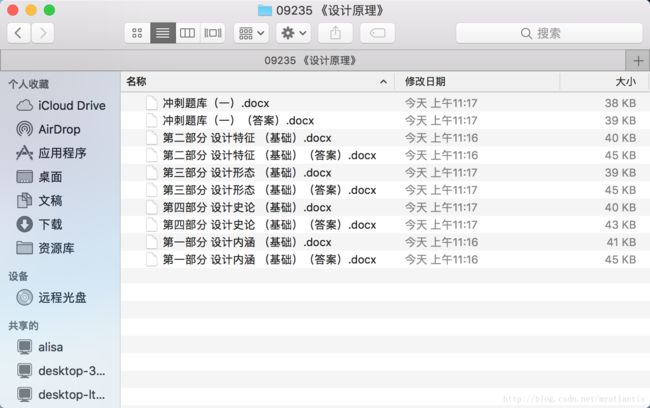

在敲代码前需要用到一个软件Fiddler,负责抓包工作,或者安装Chrome浏览器扩展程序:https://github.com/welefen/Fiddler,但这个Github项目已经停了,扩展程序可以在这个网站下载:http://www.cnplugins.com/devtool/fiddler/
首先,我们打开网站登录页面(这里我用的是Fiddler拓展程序),输入账号和密码,进入我的题库,在Fiddler中可以看到网站请求数据:
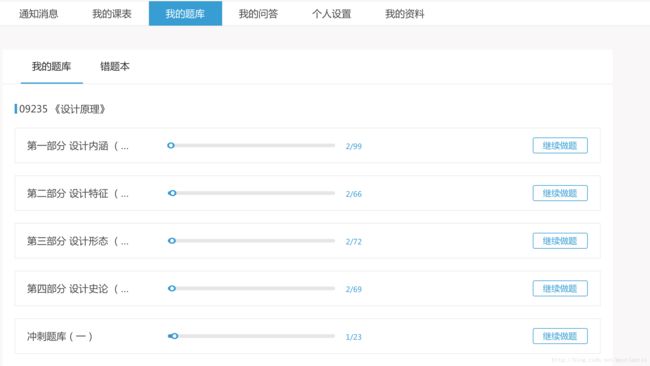
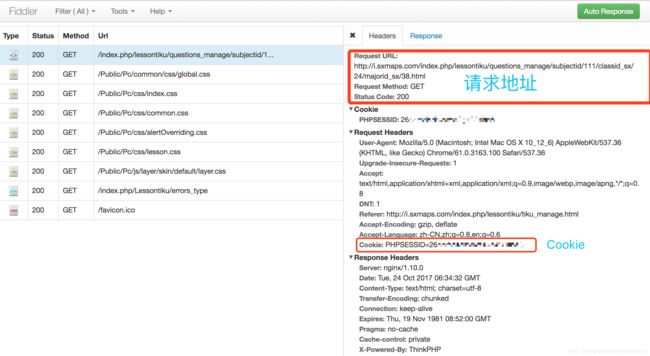
有很多模拟登录是从登录页面开始,账号密码再到获取加载Cookie,而我这个算是一次性脚本程序就简简单单忽略了,直接在请求头中传入Cookie,模拟做题操作(已加入模拟l登录操作,见完整代码)。- 在上面的网页中可以看到09235《设计原理》这门课程下有五套题目,我们右键点击“显示网页源代码”可以看到以下信息:

<div class="database-title clearfix">
<span>这里边包裹着课程名称span>
div>
......
<ul class="lesson-chap-ul">
<li class="clearfix">
<div class="lesson-errchap-tit">题目名称div>
......
<span class="progressNum">2/题目总数span>
li>
......
<li class="clearfix">
<div class="lesson-errchap-tit">试题名称div>
......
<span class="progressNum">2/题目总数span>
<div class="lesson-re-do" onclick="window.location.href='/index.php/Lessontiku/questionsmore_manage/sectionid/试题ID/subjectid/111/p/2/classid_sx/24/majorid_sx/38'">
继续做题
div>
li>
ul>从上面的伪网页源代码可知,我们只需要获得课程名称、试题名称、题目总数、试题ID,创建一个课程名称文件夹,然后通过试题ID去解析不同的试题网址:
'''
根据范围截取字符串
'''
def analyse(html, start_s, end_s):
start = html.find(start_s) + len(start_s)
tmp_html = html[start:]
end = tmp_html.find(end_s)
return tmp_html[:end].strip()
'''
解析课程列表
'''
def analyse_lesson(opener, headers, html):
#获取课程名称
tmp_folder = analyse(html, "", "")
folder = analyse(tmp_folder, "", "")
#创建文件夹,改变当前工作目录
print("正在创建文件夹(%s)..." % folder)
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
#循环获取每一个课程的试题
lesson_html = analyse(html, ""
, "")
while True:
tmp_html = analyse(lesson_html, "" , "")
lesson_html = analyse(lesson_html, tmp_html, "")
sectionid = analyse(tmp_html, "index.php/Lessontiku/questionsmore_manage/sectionid/", "/subjectid")
#解析每一套试题
analyse_exam(opener, headers, tmp_html, sectionid)
if not tmp_html or not lesson_html:
break;- 在解析试题之前先看下做题网页时如何,其中一份试题网址是
http://i.sxmaps.com/index.php/Lessontiku/questionsmore_manage/subjectid/111/sectionid/5014/p/3/majorid_sx/38/classid_sx/24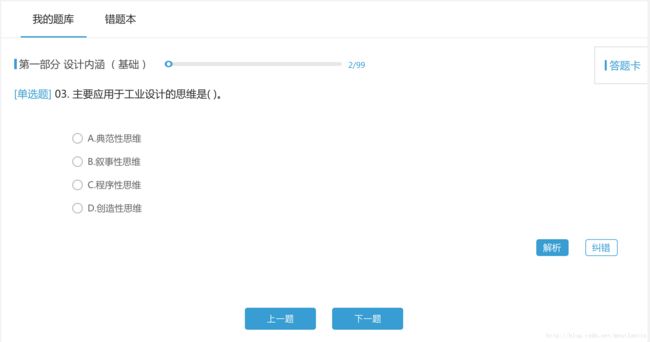
当我们点击下一题时,网址会变成:
http://i.sxmaps.com/index.php/Lessontiku/questionsmore_manage/subjectid/111/sectionid/5014/p/4/majorid_sx/38/classid_sx/24这时p/后的数字由3变成了4,说明这个数字是页数。
再来,我们换一份试题:
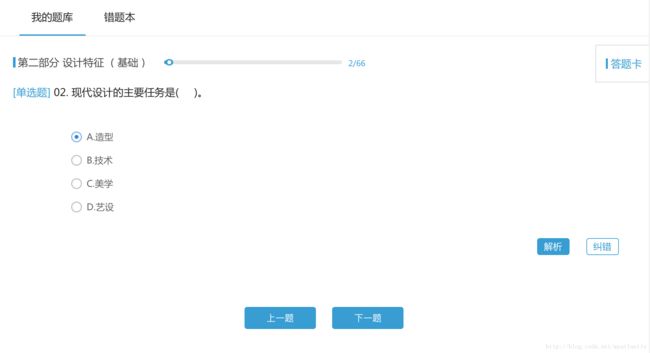
http://i.sxmaps.com/index.php/Lessontiku/questionsmore_manage/sectionid/5015/subjectid/111/p/2/classid_sx/24/majorid_sx/38这时第一个sectionid/后的数字由5014变成了5015,说明这个数字是试题ID。
这样一来,可以在脑海中想到如何把这些题目都下载下来了,使用两个循环语句,第一层负责获取试题ID,第二层负责获取题目页数,其中的请求地址可以这样写:
result_url = 'http://i.sxmaps.com/index.php/Lessontiku/questionsmore_manage/subjectid/111/sectionid/%s/p/%d/majorid_sx/38/classid_sx/24' % (sectionid, index)继续右键点击“显示网页源代码”,可以看到源码中“题目类型、题目内容、选项(只有单选题和多选题才会有)、正确答案”分布位置:


伪网页源代码如下:
<div class="database-txt">
<a style='color:#2f9cd4;font-size:16px;line-height:20px;font-wegit:bold;'>题目类型a>
<pre>题目内容pre>
......
#只有单选题和多选题才会出现选项
<div class="lesson-xz-txt">
选项1
div>
<div class="lesson-xz-txt">
选项2
div>
<div class="lesson-xz-txt">
选项3
div>
<div class="lesson-xz-txt">
选项4
div>
<pre style='line-height: 1.5;white-space: pre-wrap;'>
正确答案
pre>
div>到这里我们就可以写出正确解析所有试题的代码了:
'''
解析试题标题、题目总数
'''
def analyse_exam(opener, headers, html, sectionid):
#获取标题
title = analyse(html, "", "")
#获取题目总数
total_size = analyse(html, "", "")
start = total_size.find("/") + 1
total_size = total_size[start:]
print("正在下载(%s) 题目总数:%s" % (title, total_size))
#循环解析题目
for index in range(1, int(total_size) + 1):
result_url = 'http://i.sxmaps.com/index.php/Lessontiku/questionsmore_manage/subjectid/111/sectionid/%s/p/%d/majorid_sx/38/classid_sx/24' % (sectionid, index)
item_request = request.Request(result_url, headers = headers)
try:
response = opener.open(item_request)
html = response.read().decode('utf-8')
exam_doc = analyse_item(index, html, exam_doc)
answers_doc = analyse_answers(index, html, answers_doc)
except error.URLError as e:
if hasattr(e, 'code'):
print("HTTPError:%d" % e.code)
elif hasattr(e, 'reason'):
print("URLError:%s" % e.reason)
'''
解析每道试题详细信息
'''
def analyse_item(index, html):
#题目类型
type_s = ""
start = html.find(type_s) + len(type_s)
tmp_html = html[start:]
end = tmp_html.find("")
start = end - 5
exam_type = tmp_html[start:end].strip()
#标题
title = analyse(tmp_html, ""
, "")
paragraph = "%d.%s %s" % (index, exam_type, title)
print("标题:%s" % paragraph)
if(exam_type == '[单选题]' or exam_type == '[多选题]'):
#选项
options = []
while True:
option_s = ""
end_s = "确定"
end_div_s = ""
if tmp_html.find(option_s) <= 0:
break
start = tmp_html.find(option_s) + len(option_s)
end = tmp_html.find(end_s)
tmp_html = tmp_html[start:end]
end = tmp_html.find(end_div_s)
option = tmp_html[:end].strip()
options.append(option)
print("选项:%s" % options)
'''
解析每道试题的正确答案
'''
def analyse_answers(index, html):
#正确答案
right_s = ""
right = "%s.正确答案:%s" % (index, analyse(html, right_s, ""))
print(right)
- 最后一步,我们需要将解析好的题目保存为Word文档,而且需要将题目和答案分开存储,在网上找了好久,Python的第三方类库中比较出名的是python-docx:http://python-docx.readthedocs.io/en/latest/index.html,支持Python3,在其官网中有详细的文档和例子说明:
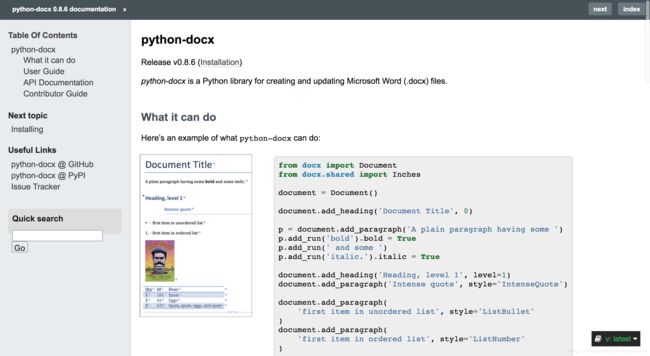
我们脚本中只需要使用里边的两三个API即可,很简单:
from docx import Document
exam_doc = Document()
#创建一个标题,第一个参数为文字,第二个参数为标题等级
heading = exam_doc.add_heading(title, 0)
#居中显示
heading.alignment = WD_ALIGN_PARAGRAPH.CENTER
#插入一段文字
exam_doc.add_paragraph(paragraph)
#保存为docx后缀的文件
exam_doc.save("test.docx")
以下是Github:https://github.com/WhoIsAA/Lesson-Crawler完整版代码(去掉了Cookie,仅供参考):
#! /usr/bin/env python3
from urllib import request
from urllib import error
from urllib import parse
from http import cookiejar
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from datetime import datetime
import os
'''
根据范围截取字符串
'''
def analyse(html, start_s, end_s):
start = html.find(start_s) + len(start_s)
tmp_html = html[start:]
end = tmp_html.find(end_s)
return tmp_html[:end].strip()
'''
解析课程列表
'''
def analyse_lesson(opener, headers, html):
#获取课程名称
tmp_folder = analyse(html, "", "")
folder = analyse(tmp_folder, "", "")
#创建文件夹,改变当前工作目录
print("正在创建文件夹(%s)..." % folder)
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
#循环获取每一个课程的试题
lesson_html = analyse(html, ""
, "")
while True:
tmp_html = analyse(lesson_html, "" , "")
lesson_html = analyse(lesson_html, tmp_html, "")
sectionid = analyse(tmp_html, "index.php/Lessontiku/questionsmore_manage/sectionid/", "/subjectid")
analyse_exam(opener, headers, tmp_html, sectionid)
if not tmp_html or not lesson_html:
break;
'''
解析试题标题、题目总数
'''
def analyse_exam(opener, headers, html, sectionid):
#获取标题
title = analyse(html, "", "")
#获取题目总数
total_size = analyse(html, "", "")
start = total_size.find("/") + 1
total_size = total_size[start:]
print("正在下载(%s) 题目总数:%s" % (title, total_size))
#考题,添加标题
exam_doc = Document()
heading = exam_doc.add_heading(title, 0)
heading.alignment = WD_ALIGN_PARAGRAPH.CENTER
#答案,添加标题
answers_doc = Document()
heading = answers_doc.add_heading(title + "(答案)", 0)
heading.alignment = WD_ALIGN_PARAGRAPH.CENTER
#循环解析题目
for index in range(1, int(total_size) + 1):
result_url = 'http://i.sxmaps.com/index.php/Lessontiku/questionsmore_manage/subjectid/111/sectionid/%s/p/%d/majorid_sx/38/classid_sx/24' % (sectionid, index)
item_request = request.Request(result_url, headers = headers)
try:
response = opener.open(item_request)
html = response.read().decode('utf-8')
exam_doc = analyse_item(index, html, exam_doc)
answers_doc = analyse_answers(index, html, answers_doc)
except error.URLError as e:
if hasattr(e, 'code'):
print("HTTPError:%d" % e.code)
elif hasattr(e, 'reason'):
print("URLError:%s" % e.reason)
filename = "%s.docx" % title
exam_doc.save(filename)
print("成功创建文件:%s" % filename)
filename = "%s(答案).docx" % title
answers_doc.save(filename)
print("成功创建文件:%s" % filename)
'''
解析每道试题详细信息
'''
def analyse_item(index, html, document):
#题目类型
type_s = ""
start = html.find(type_s) + len(type_s)
tmp_html = html[start:]
end = tmp_html.find("")
start = end - 5
exam_type = tmp_html[start:end].strip()
#标题
title = analyse(tmp_html, ""
, "")
paragraph = "%d.%s %s" % (index, exam_type, title)
document.add_paragraph(paragraph)
print("标题:%s" % paragraph)
if(exam_type == '[单选题]' or exam_type == '[多选题]'):
#选项
options = []
while True:
option_s = ""
end_s = "确定"
end_div_s = ""
if tmp_html.find(option_s) <= 0:
break
start = tmp_html.find(option_s) + len(option_s)
end = tmp_html.find(end_s)
tmp_html = tmp_html[start:end]
end = tmp_html.find(end_div_s)
option = tmp_html[:end].strip()
document.add_paragraph(option)
options.append(option)
print("选项:%s" % options)
elif(exam_type == '[简答题]'):
document.add_paragraph("")
document.add_paragraph("")
document.add_paragraph("")
#加入一个空白行
document.add_paragraph("")
return document
'''
解析每道试题的正确答案
'''
def analyse_answers(index, html, document):
#正确答案
right_s = ""
right = "%s.正确答案:%s" % (index, analyse(html, right_s, ""))
print(right)
document.add_paragraph(right)
return document
if __name__ == '__main__':
login_url = "http://i.sxmaps.com/index.php/member/login.html"
list_url = "http://i.sxmaps.com/index.php/lessontiku/questions_manage/subjectid/111/classid_sx/24/majorid_sx/38.html"
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36',
'Connection': 'keep-alive',
'DNT': '1',
'Referer': 'http://i.sxmaps.com/index.php/member/login.html',
'Origin': 'http://i.sxmaps.com',
}
#请求参数
data = {}
data['password'] = "你的密码"
data['phone'] = "你的手机号码"
data['rember_me'] = "0"
logingData = parse.urlencode(data).encode('utf-8')
cookie = cookiejar.CookieJar()
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
#登录请求
login_request = request.Request(url=login_url, data=logingData, headers=headers)
#课程列表请求
list_request = request.Request(list_url, headers = headers)
try:
#模拟登录
login_rsp = opener.open(login_request)
response = opener.open(list_request)
html = response.read().decode('utf-8')
start_t = datetime.now()
analyse_lesson(opener, headers, html)
end_t = datetime.now()
print("*" * 80)
print("* 下载完成,总共用了%s秒。" % (end_t - start_t).seconds)
print("*" * 80)
except error.URLError as e:
if hasattr(e, 'code'):
print("HTTPError:%d" % e.code)
elif hasattr(e, 'reason'):
print("URLError:%s" % e.reason)
PS:2017.10.31更新
原来有个更牛逼的html解析库BeautifulSoup,用它重新写了脚本,感觉不错,不需要手动截取字符串了,虽然…完成时间差不多
源码:https://github.com/WhoIsAA/Lesson-Crawler/blob/master/lesson_bs4.py