【论文阅读】【Vehicle ReID】Vehicle Re-identification with Viewpoint-aware Metric Learning
【论文阅读】【Vehicle ReID】Vehicle Re-identification with Viewpoint-aware Metric Learning
- 研究背景和动机
- 方案概述
- 实验结果
- 分析讨论
- 车辆方向预测准确率对算法性能的影响
- 更加细化的分支
- 参考文献
《Vehicle Re-identification with Viewpoint-aware Metric Learning》是ICCV2019上的一篇关于车辆ReID的论文,介绍了一个名为VANet(viewpoint-aware network)的网络结构,论文整体思路比较清晰,实验论证也很充分。在这里简单分享一下对论文的一些理解。
原论文地址
研究背景和动机
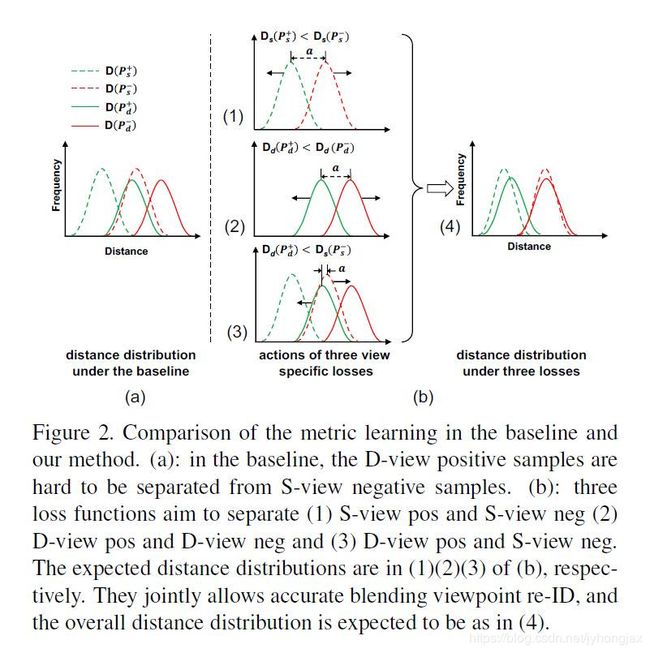
在车辆ReID任务中,由于很多车辆外形很相似(特别是同一品牌型号的车辆),而拍摄的车辆图片的视角变化是很大的(最大180°),这就导致了在使用传统的特征提取网络时,同一辆车不同视角图片之间的差异,可能会比不同车在相同视角中的差异还要大。这就给ReID任务带来了很大的挑战。如下图中(a)、(b)、(c)所示。

作者从人识别车辆的过程中得到启发:人在判断两辆车是否是同一辆车时,如果两辆车是同一视角,那么人会仔细观察车辆的细节做出判断,而如果两辆车是不同视角的图片,人会更多地依赖联想记忆。因此文章的思路可以用一句话概括:分而治之,将相同视角下的图片和不同视角下的图片分开进行处理。
方案概述
论文将车辆ReID任务进行细化,首先使用一个CNN模型预测出车辆的朝向(正面、背面、侧面等)。然后通过两个分支分别完成处于相同视角(S-view,例如两个正面)的车辆和处于不同视角(D-view,例如一个正面一个背面)的车辆的ReID任务。在每个分支中,使用的是人脸识别算法中常用的三元损失函数,分别记作 L s L_s Ls和 L d L_d Ld:
L s = m a x { D s ( P s + ) − D s ( P s − ) + α , 0 } L_s=max\{D_s(P_s^+)-D_s(P_s^-)+\alpha,0\} Ls=max{Ds(Ps+)−Ds(Ps−)+α,0} L d = m a x { D d ( P d + ) − D d ( P d − ) + α , 0 } L_d=max\{D_d(P_d^+)-D_d(P_d^-)+\alpha,0\} Ld=max{Dd(Pd+)−Dd(Pd−)+α,0}上式中, P s + P_s^+ Ps+表示由相同视角的同一辆车(正样本)组成的样本对(如果用 X X X代表样本集,则 P = ( x i , x j ) P=(x_i,x_j) P=(xi,xj)),同理 P s − P_s^- Ps−表示相同视角下的负样本对, P d + P_d^+ Pd+和 P d − P_d^- Pd−分别表示不同视角下的正样本对和负样本对。
D ( P ) D(P) D(P)表示样本对之间特征的欧式距离。 D ( P ) = D ( x i , x j ) = ∣ ∣ f ( x i ) − f ( x j ) ∣ ∣ 2 D(P)=D(x_i,x_j)=||f(x_i)-f(x_j)||_2 D(P)=D(xi,xj)=∣∣f(xi)−f(xj)∣∣2 α \alpha α是正负样本之间的最小间隔(论文中设置 α = 0.5 \alpha=0.5 α=0.5)。
但在实际应用时,由于并不知道检索的图片和注册库中的图像是不是处于同一个视角,所以当两个分支分别计算得出一个和检索照最接近的样本时,只能通过特征距离大小来确定哪个是最终识别出的结果。因此必须要对两个分支的进行联合约束,使得相同视角下的负样本对之间的特征距离尽量大于不同视角下正样本对之间的特征距离,为此,作者引入了 cross-space 约束(作为对比,将上述 L s L_s Ls和 L d L_d Ld称为 within -space 约束)。具体形式如下:
L c r o s s = m a x { D d ( P d + ) − D s ( P s − ) + α , 0 } L_{cross}=max\{D_d(P_d^+)-D_s(P_s^-)+\alpha,0\} Lcross=max{Dd(Pd+)−Ds(Ps−)+α,0}将三个损失联合作为整个模型的损失函数:
L = L s + L d + L c r o s s L=L_s+L_d+L_{cross} L=Ls+Ld+Lcross两种约束的作用示意图如下,最终实现了Figure 1中(d)的效果:
下图是算法的总体框图:

可以看出,两个分支都会计算出两两样本之间的特征距离(组成特征距离矩阵),但只会选择相应的相同(绿色)或不同视角(红色)的样本对计算 L s L_s Ls和 L d L_d Ld,最后将两个距离矩阵合并,计算 L c r o s s L_{cross} Lcross。
简单介绍下具体的网络结构。在车辆方向预测上,作者尝试了GoogLeNet和Xception,Xception网络参数只是GoogLeNet的10%,达到了差不多的预测准确率(99%左右)。在核心模型上,作者尝试了GoogLeNet和ResNet50,将较浅的一些层作为共享层,而把后面的层复制两份分别作为两个分支网络。和GooLeNet相比,以ResNet50作为基模型的性能表现更好。
实验结果
在VehicleID和Veri-776两个公开数据集上,都取得了SOTA的结果。
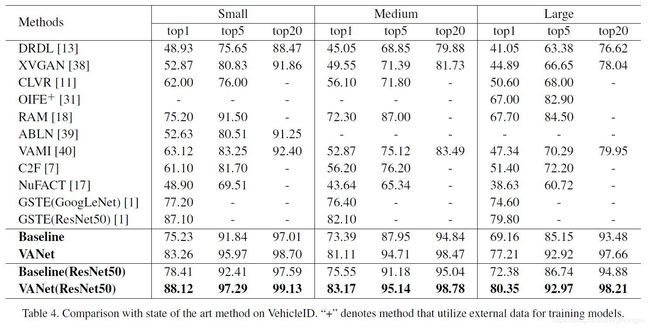
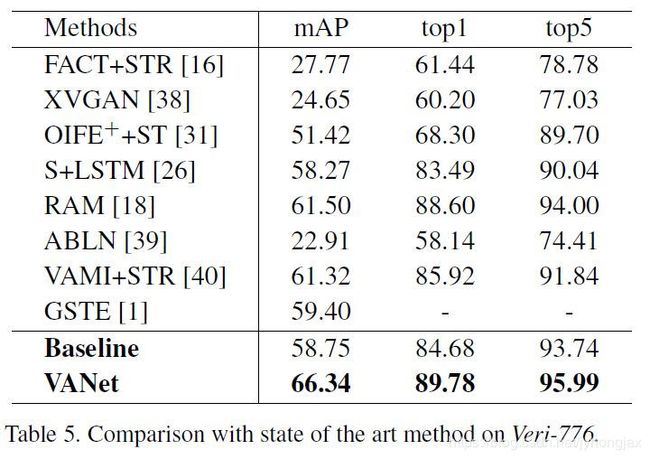
作者还对两种约束进行了对比实验(具体实施步骤这里不再详述,原论文里介绍的很详细),结果如下:


对比实验结果表明:
- 和Baseline方法(相同的模型,单分支)相比,VANet性能有了显著的提高,特别是不同视角下的识别准确率,证明了双分支策略的有效性。
- 两种约束中, cross-space 约束起决定性作用(去掉该约束后性能比Baseline方法还低),within-space 约束可以进一步提高识别准确率。
分析讨论
车辆方向预测准确率对算法性能的影响
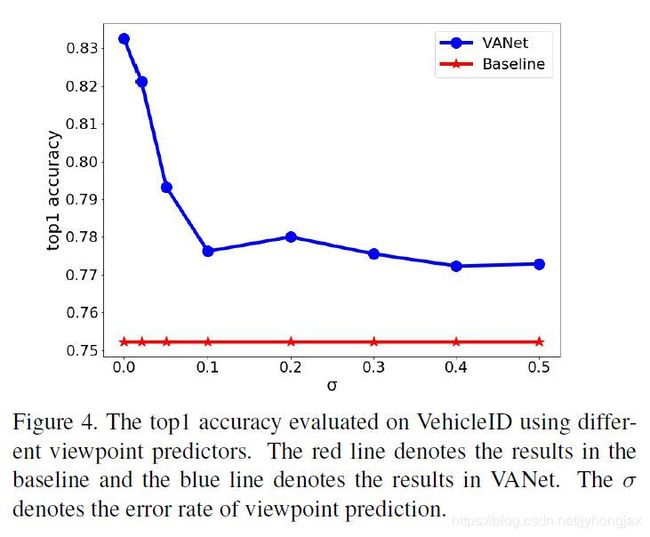
由上图可以看出,车辆方向分类的准确率对算法识别率有较大的影响,分类准确率下降10个点,识别率会下降大约6个点。值得注意的是即使分类准确率下降到50%,识别率仍然超过了Baseline。(有点不太理解-_-)
更加细化的分支
作者对VehicleID数据集标注了“前”、“后”两个方向,对Veri-776数据集标注了“前”、“后”、“侧面”三个方向,但是只设置了两个分支:S-view分支和D-view分支(例如“前-前”和“后-后”都被当作S-view,“前-后”和“后-侧”都被当作D-view)。为了研究分支数量对算法的影响,作者测试了3分支(“前-前”、“后-后”、“前/后”),4分支(“前-前”、“后-后”、“前-后”、“后-前”),并在Veri-776上测试了6分支(“前-前”、“后-后”、“侧-侧”、“前/后”、“前/侧”、“后/侧”),实验结果如下(不得不说,大佬的科研实验做得是真的充分。。。):

可以看出,当分支数量上升时,算法的识别率反而下降了(6分支的结果更差)。作者给出了两个解释:
- 数据集样本有限,分支越多每个分支的训练样本就越少,模型越容易过拟合。
- 分支越多,算法对车辆方向预测的准确性越敏感。
参考文献
- Ruihang Chu, Yifan Sun, Yadong Li, Zheng Liu, Chi Zhang: “Vehicle Re-identification with Viewpoint-aware Metric Learning”, 2019; [http://arxiv.org/abs/1910.04104 arXiv:1910.04104].