深度学习加速神器-BNN
今天给大家讲讲深度学习加速神器BNN,同时,欢迎大家加入微信群“深度学习与NLP”,入群方式可以看公众号右下角。Binarized Neural Networks(BNN)是一种为了降低深度学习模型占用内存,加速模型运算速度而诞生的一种深度学习网络,于2016年发表于Neural Information Processing Systems (NIPS 2016)的论文《Binarized Neural Networks》提出,作者还给公开了他们做实验的源代码,地址:https://github.com/MatthieuCourbariaux/BinaryNet。与传统的深度学习模型,比如DNN(Deep Neural Networks)相比,BNN最大的不同在于它的weights和activation全都进行二值化了,以此来减少DNN运行速度和减少占用的内存。论文指出,与32bit的DNN相比,BNN占用的内存减少了32倍,在GPU上的运行速度提升了7倍之多。It is so amazing ! 那么接下来就让我们来看看它到底是怎么做到的。
如何进行二值化?
作者提出了两种对weights和activation进行二值化的函数function,第一种是Deterministic Binarization,即确定型二值化:
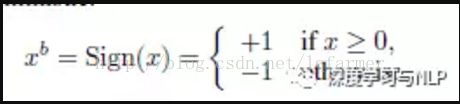
第二种是Stochastic Binarization,即随机型二值化:

第一种方式看起来比较简单,却不如第二种看起来更合理。第二种虽然更合理,但是每次计算生成随机数却非常耗时,出于加速目的考虑,一般还是选择第一种函数类似符号形式确定型函数。但是问题又来了,符号型函数导数处处为0,不能进行梯度计算反向传播。因此,作者又提出想办法。
通过离散化来进行梯度的反向传播
借鉴Yoshua Benjio在2013年的时候通过“straight-through estimator”随机离散化神经元来进行梯度计算和反向传播的工作,提出了一种考虑激活函数饱和死区特性的“straight-through estimator”,简单就是做了如下图的处理:
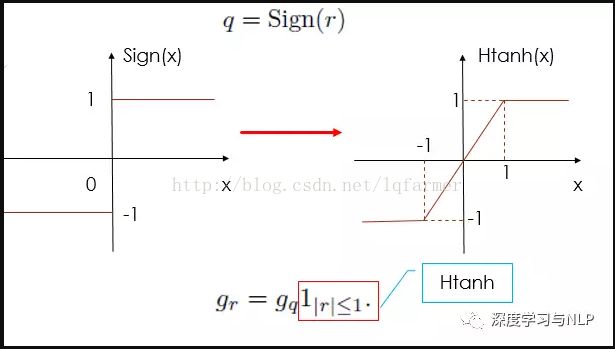
使得函数在[-1,1]之间是可导的,且梯度恒为1。
梯度计算和累加求和:
模型进行梯度计算时候,采用的是高精度的实数值。因为梯度量级很小,假设梯度服从正太分布,通过梯度的累加效果可以过滤掉梯度中噪声的影响。此外,对weights和activation的二值化,相当于对网络的参数引入噪声,可以提高网络抗过拟合的能力,这可以看做是dropout的一种变形。
训练算法1:
有了以上几条处理技巧,网络最难的求导问题得到解决,给出了一个包含BN(Batch-Normalization)的算法;

这里注意,

W(k)进行二值化之后,与上一层的输出a(k-1)相乘再进行BN之后得到k层的输出a(k),因为BN的参数θ(k)不是二值的,所以BN的输出a(k)也不是二值的,需要在进行一次Binarize操作转换成二值输出。BN的作用是可以加速训练,减少权重尺度大小影响,同时归一化引入的噪声也起到了正则化的作用。
但是,BN涉及很多矩阵运算(matrix multiplication),会降低运算速度,因此,提出了一种shift-based Batch Normalization。
shift-based Batch Normalization:
使用SBN来替换传统的BN,SBN最大的优势就是几乎不需要进行矩阵运算,而且还不会对性能带来损失。基于SBN,又提出了训练算法3:

Shift based AdaMax:ADAM是一种用于削弱权重大小对训练影响的优化算法。作者希望使用。但是ADAM和BN一样涉及很多矩阵运算,又提出了Shift based AdaMax来加速网络训练。

First Layer:整个网络出了第一层以外,其余层的weights和输出activation都是二值的。因此,只需要对第一层做一下处理就可以了,论文一图像为例,转换成一个8bit的固定输入,提出算法4:

理论分析,算法设计做完之后,就是一些性能分析和实验验证,最终得出了我们上面所说的结论:与32bit的DNN相比,BNN占用的内存减少了32倍,在GPU上的运行速度提升了7倍之多。深度学习模型权重和activation的二值化可以大大减少占用内存,提升运行速度,使得深度学习模型可以嵌入移动设备运行(手机端,Ipad),确实是不错的尝试,也给我们提供实例参考。
更多深度学习在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注微信公众号“深度学习与NLP”或“DeepLearning_NLP”或扫描二维码添加关注。
