Android面试题算法之二叉树
转载自 qing的世界 程序员小乐
文章目录
前言
二叉树的递归(深度优先)处理
二叉树的层序处理(广度优先)
总结
“
一、前言
今年可谓是跌宕起伏的一年,幸好结局还算是圆满。开年的时候由于和公司CTO有过节,被"打入冷宫",到下半年开始找工作,过程还是蛮艰辛。先分享一下offer的情况
国内的有
1.阿里口碑(offer)
2.Wish(offer)
3.Booking(Offer)
4.今日头条(Offer)
5.Airbnb(北京)被拒
最让我开心的是拿到了硅谷的offer!
FaceBook Menlo Park总部的offer
Amazon 西雅图总部 offer
在面试的过程中我深深的感受到,对于一个优秀的安卓开发来说,首先摆在第一位的还是他/她作为一个软件工程师的基本素养。无论你是做前端还是后端,最后定义你的优秀程度的还是作为软件工程师的基本素养,学习能力和编程能力,还有设计能力。我自己在现在的公司也做过面试官,发现新加坡的大部分码农(东南亚的码农),对基础的编程能力实在是有所欠缺,熟练的使用API却不能理解为什么。

很多同学会在长久以往的业务逻辑开发中慢慢迷失,逐渐的把写代码变成了一种习惯,而没有再去思考自己代码的优化,结构的调整。这个现象不止是安卓开发的小伙伴有,任何大公司的朋友都会遇到。所以我这一系列的文章打算深入的讲解一下对于安卓程序员面试中可能遇到的算法。也希望能培养大家多思考,业余时间多动手写好代码,优质代码的习惯。
那么第一篇我打算着重讲一下二叉树的问题。
一、二叉树的递归(深度优先)处理
“
二、二叉树的递归(深度优先)处理
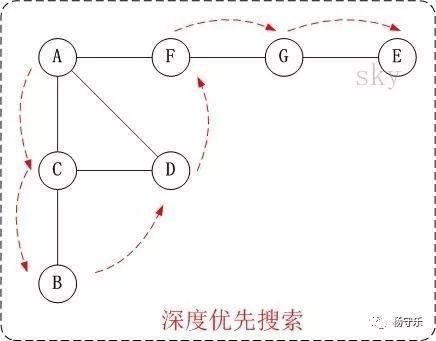
相信大家以前在学习算法与数据结构的时候都遇到过。比如说,打印二叉树前序,中序,后序的字符串这种问题。一般来说我们会选择使用递归的形式来打印,比如说
/**
** 二叉树节点
**/
public class TreeNode{
TreeNode left;
TreeNode Right;
int value;
}
//中序
public void printInoderTree(TreeNode root){
//base case
if(root == null){
return;
}
//递归调用printTree
printInoderTree(root.left);
System.out.println(root.val);
printInoderTree(root.right);
}
//中序
public void printPreoderTree(TreeNode root){
//base case
if(root == null){
return;
}
//递归调用printTree
System.out.println(root.val);
printPreoderTree(root.left);
printPreoderTree(root.right);
}
一开始上学的时候,我这几段代码都是背下来的,完全没有理解其中的奥妙。对于二叉树的递归操作,其实正确的理解方式
把每次递归想象成对其子集(左右子树)的一个操作,假设该递归已经可以处理好左右子树,那么根据已经处理好的左右子树在调整根节点。
这样的思想其实和分而治之 分治法 相似,就是把一个大问题先分成小问题,再去解决。我们还是以二叉树的中序打印为例子。
因为中序打印我们需要以左中右的顺序打印二叉树,以下图为例子我们分解一下问题。
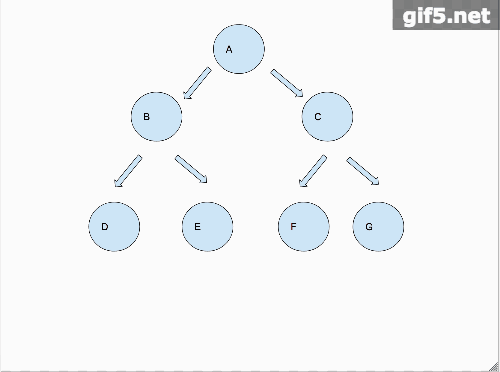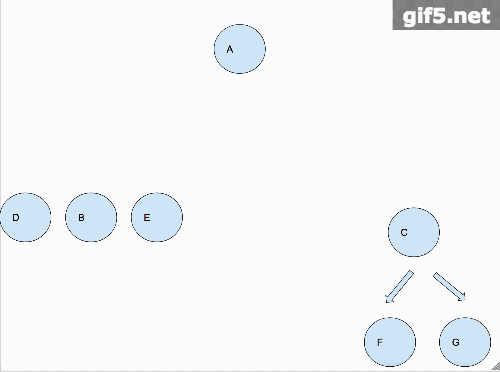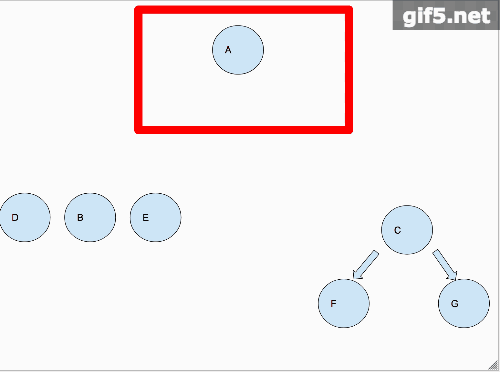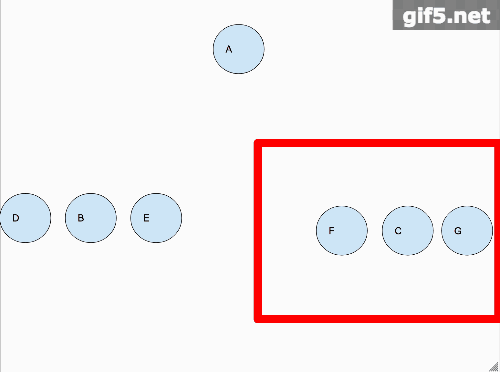
上面这个gif详细的解释了怎么叫分而治之,首先,我们假设A节点的左右子树分开而且已经打印完毕,那么只剩下A节点需要单独处理,那么久打印它。对于B子树来说,我们以同样的思维处理。所以动图里面是B子树先铺平,然后轮到A节点,最后到C子树。
最后我们需要考虑一下这个递归的结束条件。我们假设A节点左右子树都为空,null,那么在调用该方法的时候我们需要在Node为空的时候直接返回不做任何操作。该条件我们一般称为递归的Base Case。每个递归都是这样,先想好我们怎么把问题分治, 再考虑base case是哪些,怎么处理,我们的递归就结束了。
问题来了,我们明明要讲深度优先,为什么讲起递归了。两者的联系是什么?
其实递归对于很多数据结构来说,就是深度优先,比如二叉树,图。因为在递归的过程中,我们就是在一层一层的往下走,比如对于二叉树的中序打印来说,我们递归树的左节点,除非左节点为空,我们会一直往下走,这本身就是深度优先了。所以一般来说,对于深度优先,我们都会用递归来解决,因为写起来最方便。当然我们深度优先如果不想用递归,还可以使用栈(Stack)来解决,我们在以后的文章来讲(不过大家需要知道的是,递归本身就是使用方法栈的一种操作,联想一下我们常常听到的StackOverFlow,你应该能明白其中的奥妙了吧)。
好!相信我已经勾起了大家对大学算法课的记忆了!那么我们来巩固一下。使用分治思想+递归,我们就已经可以解决大部分二叉树的问题了。 我们来看一道题目->
1. 翻转二叉树
这道题是一个经典的题目,Mac上著名软件HomeBrew的作者曾经在面试Google的时候被问到了,还没做出来,因此最后被拒。。。。于是他在个人推特上抱怨到:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so fuck off.
最后大家的关注点就慢慢从作者被拒本身转移到了题目上了。。。那我们看看这道题到底有多难。
翻转前
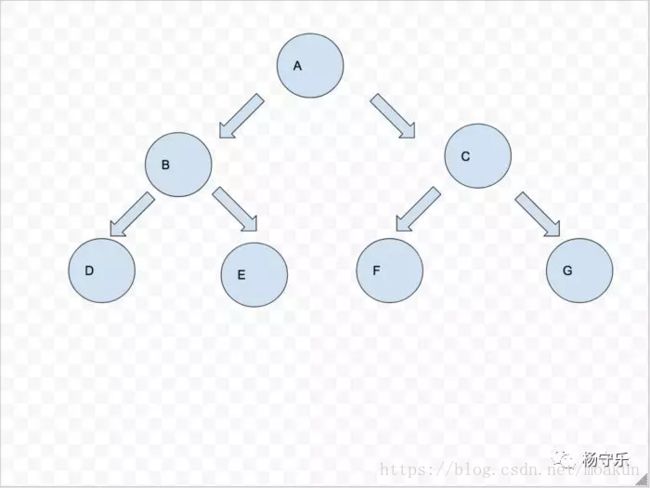
翻转后
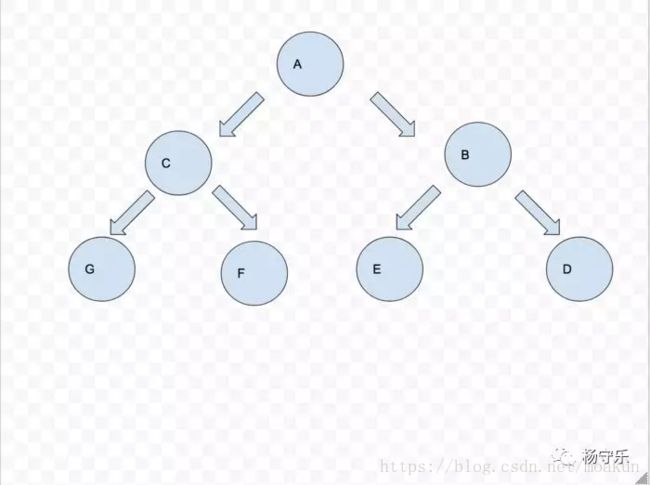
看起来好像很麻烦的样子,每个子树本身都被翻转一遍。但是我们使用分治的思维,假如说我们有个函数,专门翻转二叉树的。假如我们把B子树翻转好,再把C子树翻转好,那么我们要做的岂不就是简单的把A节点的左赋给C(原来是B),再把A节点的右赋给B(原来是C)。这个问题是不是就解决了?
对于B和C我们可以用同样的分治思维去递归解决。用一段代码来描述一下
public TreeNode reverseBinaryTree(TreeNode root){
//先处理base case,当root ==null 时,什么都不需要做,返回空指针
if(root == null){
return null;
}
else{
//把左子树翻转
TreeNode left = reverseBinaryTree(root.left);
//把右子树翻转
TreeNode right = reverseBinaryTree(root.right);
//把左右子树分别赋值给root节点,但是是翻转过来的顺序
root.left = right;
root.right = left;
//返回根节点
return root;
}
}
根据这个例子,再加上中序打印的题目,我们应该已经可以很轻松的理解到了,对于二叉树的题目或者算法,分而治之 和 递归 的核心思想了,就是把左右子树分开处理,最后在把结果合并(把处理好的左右子树对应根节点进行处理)。
那么接下来我们来一个复杂一点点的题目
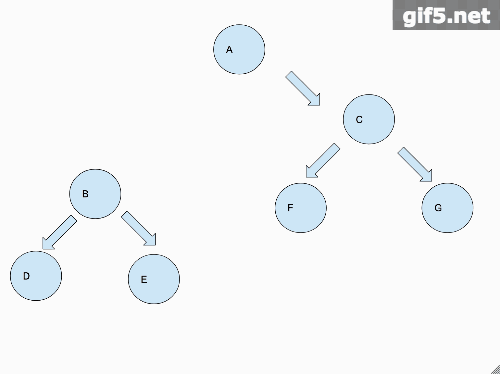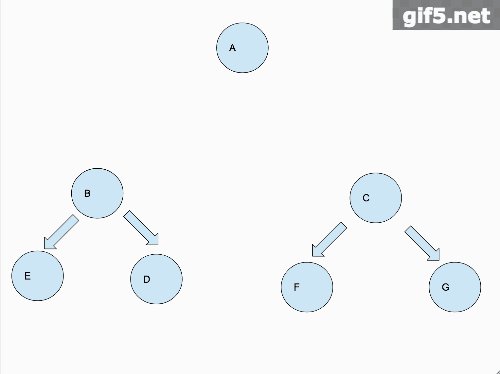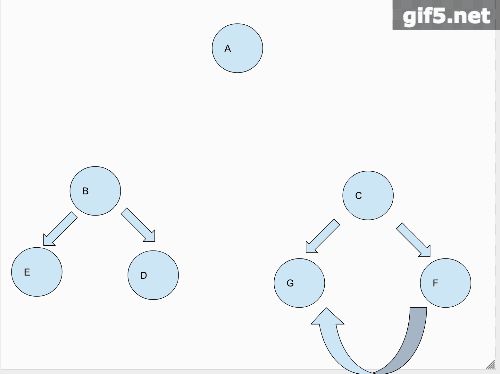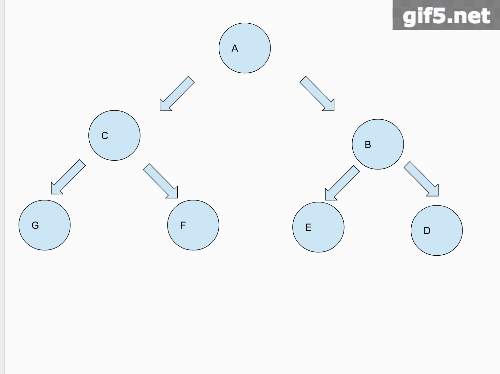
2. 把二叉树铺平
这个题目我们需要把一个二叉树变成一个类似于链表的结构,所有的子节点都移到右节点去,看图为例。
转变之后
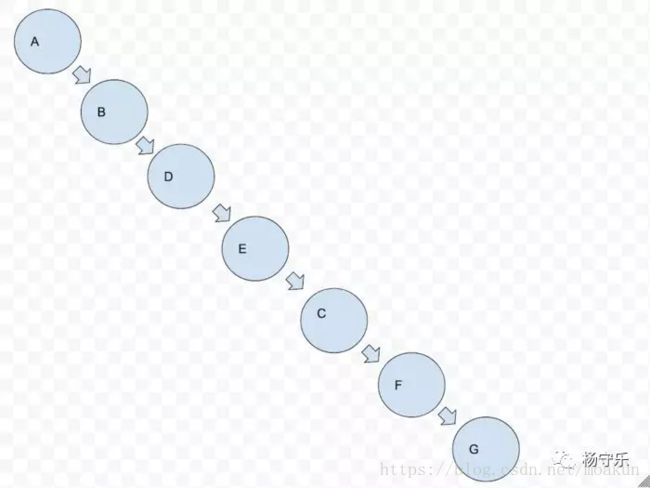
从图中我们可以看出来,把二叉树铺平的这个过程,是先把左子树铺平,链接到根节点的右节点上面,再把右子树铺平,链接到已经铺平的左子树的最后一个节点上。最后返回根节点。那么我们从一个宏观的角度来说,需要做的就是先把左右子树铺平。
假设我们有一个方法叫flatten(),它会把一个二叉树铺平最后返回根节点
public TreeNode flatten(TreeNode root){
}
那么从宏观的角度,我们对铺平这个操作,已经做完了!!!接下来就是第二步,还是以一个动画来阐述这个过程。
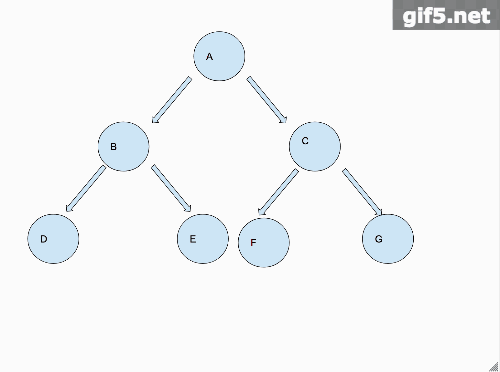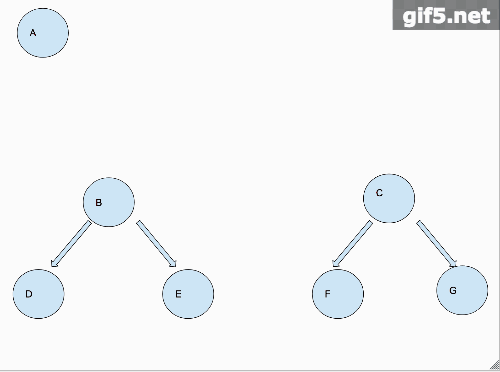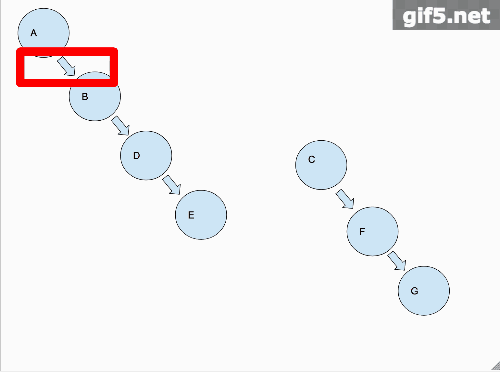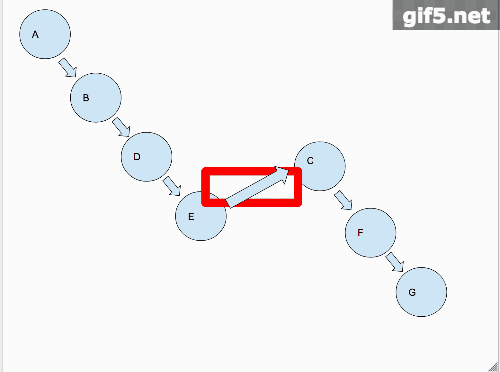
最终代码如下,附上注释
public TreeNode flatten(TreeNode root){
//base case
if(root == null){
return null;
}
else{
//用递归的思想,把左右先铺平
TreeNode left = flatten(root.left);
TreeNode right = flatten(root.right);
//把左指针和右指针先指向空。
root.left = null;
root.right = null;
//假如左子树生成的链表为空,那么忽略它,把右子树生成的链表指向根节点的右指针
if(left == null){
root.right = right;
return root;
}
//如果左子树生成链表不为空,那么用while循环获取最后一个节点,并且它的右指针要指向右子树生成的链表的头节点
root.right = left;
TreeNode lastLeft = left;
while(lastLeft != null && lastLeft.right != null){
lastLeft = lastLeft.right;
}
lastLeft.right = right;
return root;
}
}
至此,我们已经做完了这道题了,希望大家最后能好好理解我们所谓的分而治之的思想和二叉树中对左右子树递归的处理。大部分的二叉树算法题也就是围绕着这个思想为中心,只要从宏观上能把对左右子树处理的逻辑想清楚,那么就不难解决了。
3. 安卓开发中遇到的树形结构?
那么对于安卓开发中,我们会不会遇到类似的问题呢?或者说安卓开发中会遇到树形结构的算法么?
答案是肯定有!
我们都知道在安卓系统里面,每个ViewGroup里面又会包含多个或者零个View,每一个View 或者 ViewGroup 都有一个整型的Id,那么每次我们在使用ViewGroup的findViewById(int id)的时候,我们是以什么方式来查找并返回在当前ViewGroup下面,我们要查找的View呢?
这个也是我非常喜欢对来我司应聘的求职者的问题,不过很遗憾,目前为止能完完整整写出来的就一个。。。。(再次可见东南亚开发者的水平,不忍吐槽)
那么题目来了
请完成以下方法
//返回一个在vg下面的一个View,id为方法的第二个参数
public static View find(ViewGroup vg, int id){
}
可以使用的方法有:
View -> getId() 返回一个int 的 id
ViewGroup -> getChildCount() 返回一个int的孩子数量
ViewGroup -> getChildAt(int index) 返回一个孩子,返回值为View。
这个题目就可以说非常经典了,以往的树形结构的题目,我们都是做一个二叉树的处理,除了左就是右,但是这里我们每个ViewGroup都可能有多个孩子,每个孩子既可能是ViewGroup,也可能只是View(ViewGroup是View的子类,这里是一个知识点!)
我这里就不做过多的解释了,直接贴代码,而且安卓系统本身也是用这种方式进行View的查找的。
//返回一个在vg下面的一个View,id为方法的第二个参数
public static View find(ViewGroup vg, int id){
if(vg == null) return null;
int size = vg.getChildCount();
//循环遍历所有孩子
for(int i = 0 ; i< size ;i++){
View v = vg.getChildAt(i);
//如果当前孩子的id相同,那么返回
if(v.getId == id) return v;
//如果当前孩子id不同,但是是一个ViewGroup,那么我们递归往下找
if(v instance of ViewGroup){
//递归
View temp = find((ViewGroup)v,id);
//如果找到了,就返回temp,如果没有找到,继续当前的for循环
if(temp != null){
return temp;
}
}
}
//到最后还没用找到,代表该ViewGroup vg 并不包含一个有该id的孩子,返回空
return null;
}
“
三、二叉树的层序处理(广度优先)
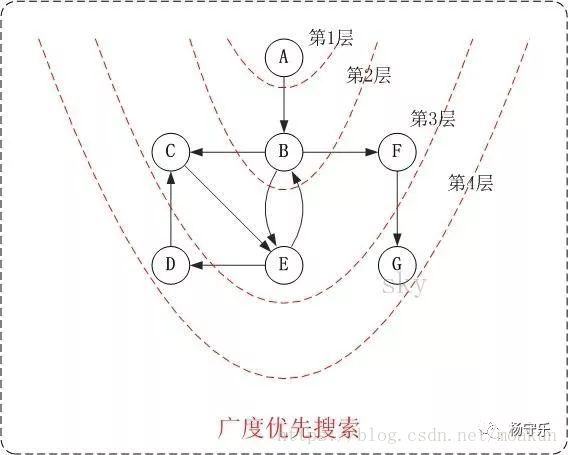
说到广度优先,大部分同学可能会想到图,不过毕竟树结构本身就是一种特殊的图。所以一般说树,尤其是二叉树的广度优先我们指的一般是层序遍历。
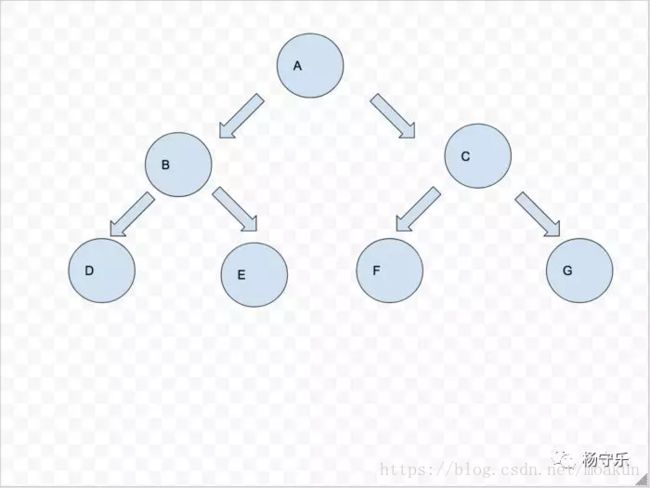
比如说树
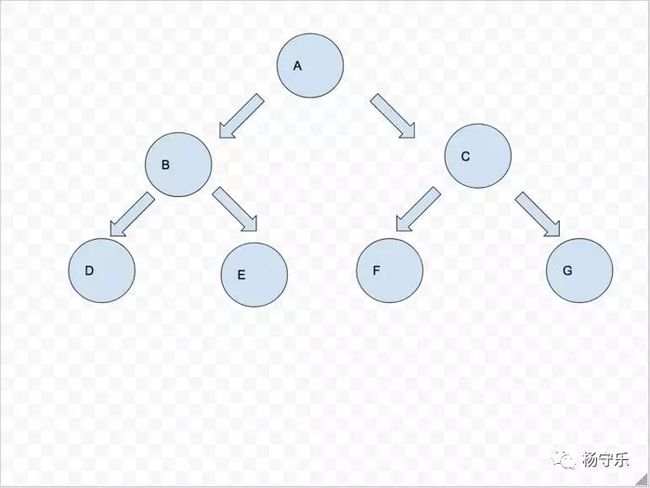
层序打印的结果就是A->B->C->D->D->E->F->G
对于层序遍历的相关算法,真理只有一个!

就是用队列(Queue)!
道理很简单,每次遍历当前节点的时候,把该节点从队列拿出来,并且把它的子节点全部加入到队列中。over~
上一个简单的打印代码
public void printTree(TreeNode root){
if(root == null){
return;
}
Queue queue = new LinkedList();
queue.add(root);
while(!queue.isEmpty()){
TreeNode current = queue.poll();
System.out.println(current.toString());
if(current.left != null){
queue.add(current.left);
}
if(current.right != null){
queue.add(current.right);
}
}
}
这段代码很简单,利用队列先进先出的性质,我们可以一层层的打印二叉树的节点们。
所以对于二叉树的层序遍历来说,一般都会使用队列,这都是套路。因此,二叉树的层序遍历相对来说比较简单,大家下次见到二叉树的层序遍历相关的面试题,先大胆的和面试官说出你打算使用队列,肯定没错!

最后对于层序遍历来说我们再来一个比较具有代表性的题目!
1. 链接二叉树的Next节点
这个题目要求大家在拥有一个二叉树节点的左右节点指针之余,还要帮它找到它的next指针指向的节点。
大概是这样:
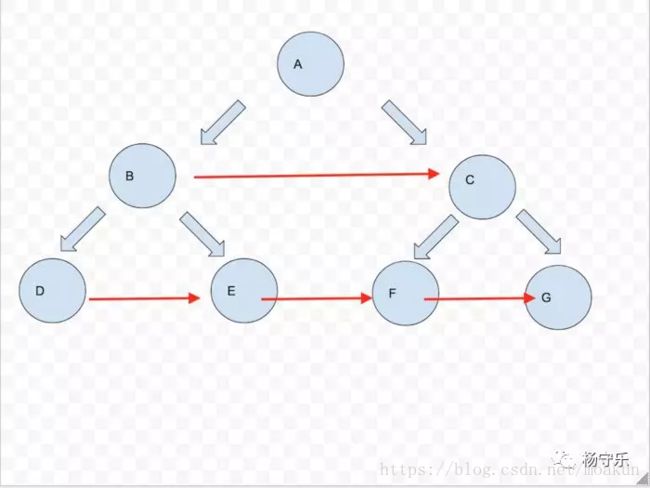
在上面这个图中,红色的箭头代表next指针的指向
逻辑很简单,每一个的节点的next指向同一层中的下一个节点,不过如果该节点是当前层的最后一个节点的话,不设置next,或者说next为空。
其实这个题目就是典型的层序遍历,使用队列就可以轻松解决,每次poll出来一个节点,判断是不是当前层的最后一个,如果不是,把其next设置成queue中的下一个节点就ok了。至于怎么判断当前节点是哪一层呢?我们有个小技巧,使用当前queue的size做for循环,且看代码
public void nextSibiling(TreeNode node){
if(node == null){
return;
}
Queue queue = new LinkedList();
queue.add(node);
//这个level没有实际用处,但是可以告诉大家怎么判断当前node是第几层。
int level = 0;
while(!queue.isEmpty()){
int size = queue.size();
//用这个for循环,可以保证for循环里面对queue不管加多少个子节点,我只处理当前层里面的节点
for(int i = 0;i //把当前第一个节点拿出来
TreeNode current = queue.poll();
//把子节点加到queue里面
if(current.left != null){
queue.add(current.left);
}
if(current.right != null){
queue.add(current.right);
}
if(i != size -1){
//peek只是获取当前队列中第一个节点,但是并不把它从队列中拿出来
current.next = queue.peek();
}
}
}
level++;
}
} “
四、总结
二叉树的知识点我就大概讲这些,下次的文章我会接着详细的讲深度优先和广度优先的算法。深度优先是一个非常非常宽泛而且难以完全掌握的知识点,我会用详细的篇幅来覆盖所有的深度优先的基本题型,包括对树,图的深度优先搜索,集合的回朔等等。
如果您觉得不错,请别忘了转发、分享、点赞让更多的人去学习, 您的举手之劳,就是对小乐最好的支持,非常感谢!
如何您想进技术群和大牛们交流,关注公众号在后台回复 “加群”,或者 “学习” 即可
来自:qing的世界
链接:https://www.jianshu.com/p/6f179f37ad79
著作权归作者所有。本文已获得授权。欢迎大家来投稿。
每日英文
Sometimes we want things to be different,we think maybe if we pretend that they are,fool people,that’s enough,but it never is.
有时候我们希望事情有所改变,觉得如果我们假装那是我们想要的,欺骗别人 ,那样就行了,但事实上不是。
乐乐有话说
时间是一把戳穿虚伪的刀,它验证了谎言,揭露了现实,淡化了承诺。
![]()