常用的一些算法模型评价指标
1. 基本概念
| FN | TP |
| TN | FP |
TP —— True Positive (真正, TP)被模型预测为正的正样本;可以称作判断为真的正确率
TN —— True Negative(真负 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
FP ——False Positive (假正, FP)被模型预测为正的负样本;可以称作误报率
FN—— False Negative(假负 , FN)被模型预测为负的正样本;可以称作漏报率
True Positive Rate(真正率 , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN)
正样本预测结果数 / 正样本实际数
True Negative Rate(真负率 , TNR)或特指度(specificity)
TNR = TN /(TN + FP)
负样本预测结果数 / 负样本实际数
False Positive Rate (假正率, FPR)
FPR = FP /(FP + TN)
被预测为正的负样本结果数 /负样本实际数
False Negative Rate(假负率 , FNR)
FNR = FN /(TP + FN)
被预测为负的正样本结果数 / 正样本实际数
Precision:P=TP/(TP+FP) 精准率(查准率)
Recall:R=TP/(TP+FN) 召回率(查全率 )
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数
F1-score:2/(1/P+1/R)
ROC/AUC:TPR=TP/(TP+FN), FPR=FP/(FP+TN)
Fβ=(1+β2)×P×Rβ2×P+R 其中β>1查全率有更大影响,0<β<1查准率有更大影响。β=1退化为F1
2. ROC、AUC和PRC
ROC(receiver operating characteristic curve)是曲线。也就是下图中的曲线。AUC也就是蓝色线与FPR围成的面积。一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中0.2到0.4可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。 
PRC, precision recall curve。和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。 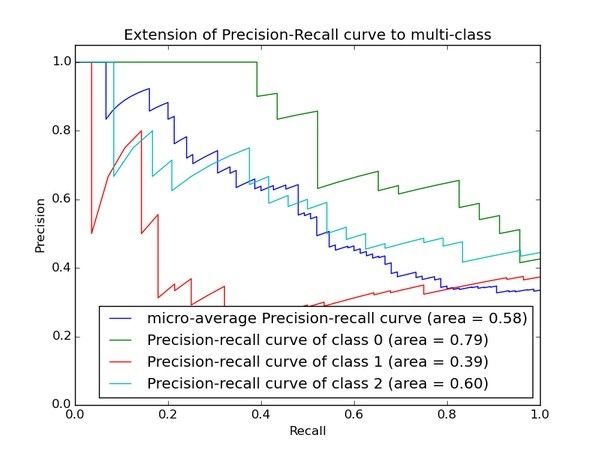
有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),那么选择模型还是要结合具体的使用场景。
下面是两个场景:
1. 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次,对了8次漏了2次。
2. 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
如果只能选一个指标的话,肯定是选PRC了。
3.注释
mark1:在一些应用中,对精准率(查准率)和召回率(查全率 )重视程度不同,如商品推荐系统中,为了尽可能少打扰用户,更希望推荐的内容确实是用户比较感兴趣的,此时精准率(查准率)比较重要;在逃犯信息检索系统中,更希望尽量可能少漏掉逃犯,此时召回率(查全率 )比较重要;
mark2:ROC比PRC效果好这个结论的切入点:
对于同一份数据不同的模型来说,由于ROC同时考虑了两个类别上的准确率,效果比PRC要好;PRC由于仅考虑正样本,如果分布失衡,容易造成某个模型的PRC很高,但其实是在样本量大的那个类别“带偏”了;
mark3:PRC比ROC效果好这个结论的切入点:
对于同一份数据同一个的模型来说(就只有一个模型,一个ROC,一个PRC),因为ROC对类分布不敏感,就容易造成一个看似比较高的AUC对应的分类效果实际上并不好;而PRC就会波动非常大,以一个很“激烈”的方式表现出效果的不好。
某个模型AUC本身值的大小其实是不重要的,重要的是跟其他模型在同一份数据集上的AUC的大小关系,相对较大的那个更好。而PRC由于波动剧烈,即使不同模型在不同数据集上,也能看出一定的效果。(但其实对建立在不同数据上的不同模型,或者仅仅对某一个模型,仅靠PRC或者AUC来决定哪个好哪个差,这种方法本身就是不正确的。)
转载自:http://blog.csdn.net/guhongpiaoyi/article/details/53289229
一、假正例和假负例
假正例(False Positive):预测为1,实际为0的样本
假负例(False Negative):预测为0,实际为1的样本
实际预测中,那些真正例(True Positive)和真负例(True Negative)都不会造成损失(cost)。
那么,我们假设一个假正例的损失是LFP,一个假负例的损失是LFN。
我们可以得到一个损失矩阵:
| |
y^=1 | y^=0 |
| y=1 | 0 | LFN |
| y=0 | LFP | 0 |
其中,y是真实值,y^是预测值。
那么,我们可以得到一个样本的后验期望损失:

![clip_image002[6]](http://img.e-com-net.com/image/info8/d1101c2b0a1748ac99707d30bd5db282.png "clip_image002[6]")
当![clip_image002[8]](http://img.e-com-net.com/image/info8/6a4af8c4dbe64743bb5c1ac553b1a0ee.png "clip_image002[8]") 的时候,我们会预测结果为y^1=1,此时
的时候,我们会预测结果为y^1=1,此时
![clip_image002[10]](http://img.e-com-net.com/image/info8/3981b4a1eb234e2e9b7ba14058dffe8a.png "clip_image002[10]")
假设,![clip_image002[12]](http://img.e-com-net.com/image/info8/09ef378957c64301b699dbb8a9f58ab9.png "clip_image002[12]") ,那么我们可以得到决策规则:
,那么我们可以得到决策规则:
![clip_image002[14]](http://img.e-com-net.com/image/info8/48e3e75b6b2d49a3a4236f0eed2798a3.png "clip_image002[14]")
其中,![clip_image002[16]](http://img.e-com-net.com/image/info8/b675ff5855104187abca7ad7d5af350a.png "clip_image002[16]") ,也就是我们的决策边界。
,也就是我们的决策边界。
例如,c=1时,我们对假正例和假负例同等对待,则可以得到我们的决策边界0.5。
二、ROC曲线
1.混淆矩阵(confusion matrix)
针对预测值和真实值之间的关系,我们可以将样本分为四个部分,分别是:
真正例(True Positive,TP):预测值和真实值都为1
假正例(False Positive,FP):预测值为1,真实值为0
真负例(True Negative,TN):预测值与真实值都为0
假负例(False Negative,FN):预测值为0,真实值为1
我们将这四种值用矩阵表示(图片引自《machine learning:A Probabilistic Perspective》):

上面的矩阵就是混淆矩阵。
2.ROC曲线
通过混淆矩阵,我们可以得到真正例率(True Positive Rate , TPR):

我们还可以得到假正例率(False Positive Rate , FPR):
![clip_image002[5]](http://img.e-com-net.com/image/info8/dfdcae11efda4b66822df9da7d2e1812.png "clip_image002[5]")
可以看到,TPR也就是我们所说的召回率,那么只要给定一个决策边界阈值![clip_image002[7]](http://img.e-com-net.com/image/info8/29cb5432e9d94c979b82b108034d02a2.png "clip_image002[7]") ,我们可以得到一个对应的TPR和FPR值,然而,我们不从这个思路来简单的得到TPR和FPR,而是反过来得到对应的
,我们可以得到一个对应的TPR和FPR值,然而,我们不从这个思路来简单的得到TPR和FPR,而是反过来得到对应的![clip_image002[9]](http://img.e-com-net.com/image/info8/97db2409c2024dd3a5c9980fbbf226bc.png "clip_image002[9]") ,我们检测大量的阈值
,我们检测大量的阈值![clip_image002[7]](http://img.e-com-net.com/image/info8/5bf73ab1ea3840f4b9553175faf8fe84.png "clip_image002[7]") ,从而可以得到一个TPR-FPR的相关图,如下图所示(图片引自《machine learning:A Probabilistic Perspective》):
,从而可以得到一个TPR-FPR的相关图,如下图所示(图片引自《machine learning:A Probabilistic Perspective》):

图中的红色曲线和蓝色曲线分别表示了两个不同的分类器的TPR-FPR曲线,曲线上的任意一点都对应了一个![clip_image002[9]](http://img.e-com-net.com/image/info8/2662400668814eac8923f1be66a88145.png "clip_image002[9]") 值。该曲线就是ROC曲线(receiver operating characteristic curve)。该曲线具有以下特征:
值。该曲线就是ROC曲线(receiver operating characteristic curve)。该曲线具有以下特征:
-
一定经过(0,0)点,此时
![clip_image002[13]](http://img.e-com-net.com/image/info8/ec55a77d9ffa4ecd92a91dd5418f10d1.png "clip_image002[13]") ,没有预测为P的值,TP和FP都为0
,没有预测为P的值,TP和FP都为0
-
一定经过(1,1)点,此时
![clip_image002[15]](http://img.e-com-net.com/image/info8/8a14a5ffe0774539a5c0f0012073af30.png "clip_image002[15]") ,全都预测为P
,全都预测为P
-
最完美的分类器(完全区分正负样例):(0,1)点,即没有FP,全是TP
-
曲线越是“凸”向左上角,说明分类器效果越好
-
随机预测会得到(0,0)和(1,1)的直线上的一个点
-
曲线上离(0,1)越近的点分类效果越好,对应着越合理的
![clip_image002[9]](http://img.e-com-net.com/image/info8/d025c20d68a849a88f0baffd9c9275d1.png "clip_image002[9]")
从图中可以看出,红色曲线所代表的分类器效果好于蓝色曲线所表示的分类器。
3.利用ROC的其他评估标准
- AUC(area under thecurve),也就是ROC曲线的下夹面积,越大说明分类器越好,最大值是1,图中的蓝色条纹区域面积就是蓝色曲线对应的 AUC
- EER(equal error rate),也就是FPR=FNR的值,由于FNR=1-TPR,可以画一条从(0,1)到(1,0)的直线,找到交点,图中的A、B两点。