Python 爬取抖音视频(小白版)
注:
_signature 参数 是拿js生成的 ,但是我试验了 ,并不好使,所以暂时没放上去。如何获取的等有时间加上。
由于第一次写博客,并且文笔真的不好,所以写的不好请见谅。
本次写的爬虫真的是很简单的,所以大神可以略过,小白可以看一下思路,代码就算了。
思路分析:
1. 抖音APP分享链接
2. 使用分享的连接找到视频地址
3. 请求视频地址并保存视频
一、抖音APP分享需要的链接

内容为: 在抖音,记录美好生活! http://v.douyin.com/x8vFm4/
二、打开链接 并找到视频接口
使用浏览器打开链接 并且打开调试模式,找到抖音请求的接口。
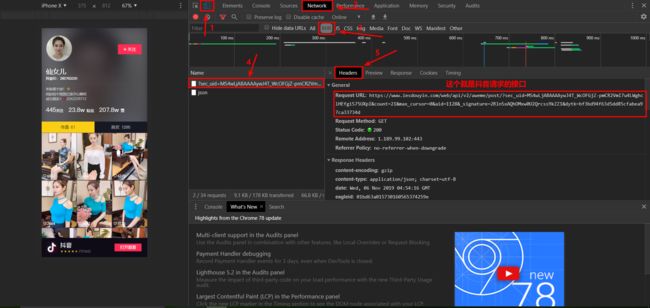
查看接口返回的数据
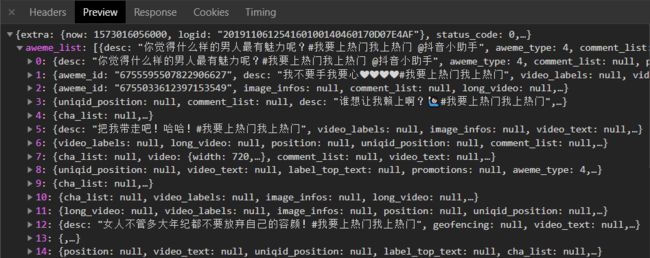
打开接口返回的json 其中 video 中的数据就是视频链接
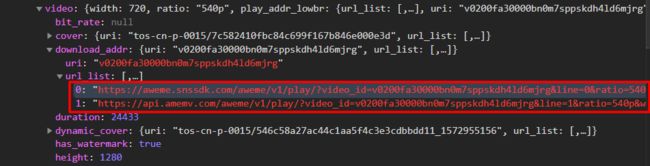
在浏览器打开视频链接,发现出现 HTTP ERROR 403,这是因为没有打开调试模式 模拟手机访问,抖音视频链接不允许在pc端打开。
打开调试模式,在刷新一下,视频就可以打开了。

三、分析接口
视频找到了接下来就简单了,先分析一下视频接口。我拿第一页视频的接口和第二页的视频接口做了下对比。
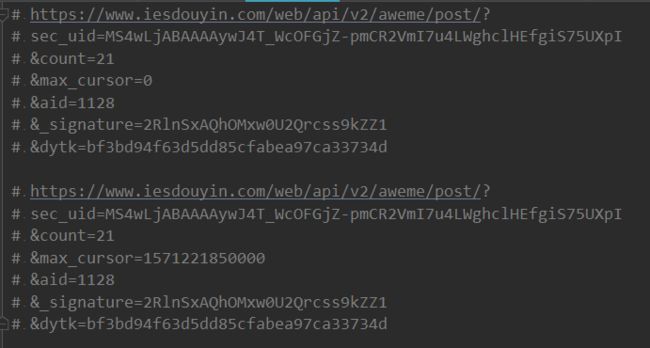
其中 sec_uid、count、aid、_signature、dytk都没有变,只有max_cursor变了 而且max_cursor的值应该是个时间戳。
![]()
转换一下 发现时间是之前的时间,那max_cursor肯定不会是失效时间了,既然不是失效时间就去之前的接口找一下。
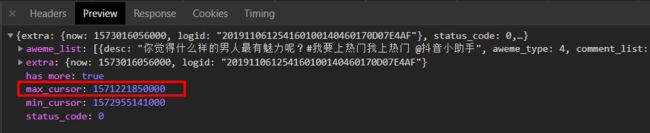
发现就在这个最明显的位置呢。。。 接下来参数都齐了,就可以写一个简单的爬虫了。
四、开始写爬虫
偷个懒 使用postman 生成一个简单的Python request请求代码
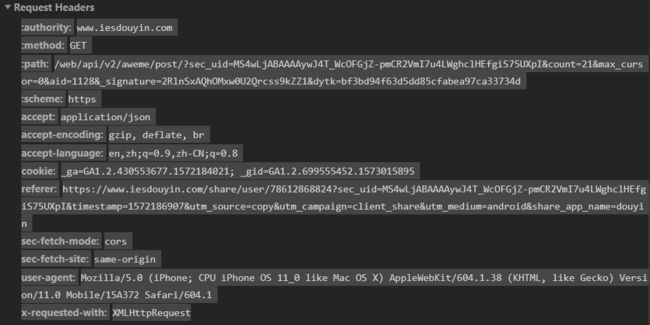
复制 Request Headers 中的全部内容
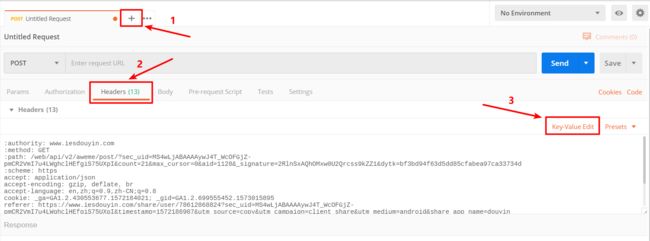
打开Postman 创建一个标签 > 选择Headers > 点击Key-Value Edit > 把内容粘贴进去
点击Code 选择Python Request 把生成的代码复制了
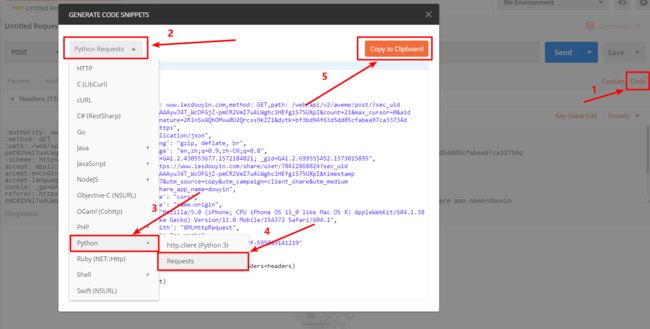
粘贴到PyCharm中 然后修改一下代码
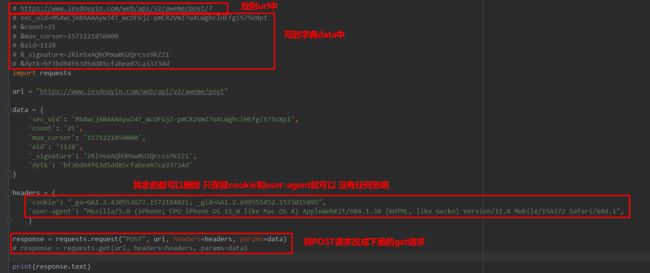
右键运行 发现返回一个空列表

这个没研究明白什么问题 只能通过循环来获取,在修改一下代码
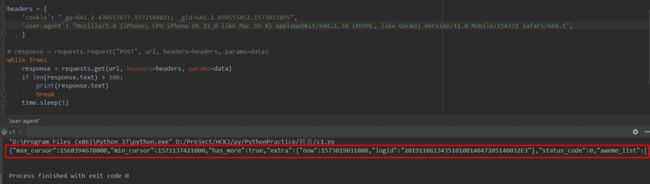
成功返回数据,可以开始解析json了。
由于比较简单 就直接上代码了。
# https://www.iesdouyin.com/web/api/v2/aweme/post/?
# sec_uid=MS4wLjABAAAAywJ4T_WcOFGjZ-pmCR2VmI7u4LWghclHEfgiS75UXpI
# &count=21
# &max_cursor=0
# &aid=1128
# &_signature=2RlnSxAQhOMxw0U2Qrcss9kZZ1
# &dytk=bf3bd94f63d5dd85cfabea97ca33734d
# https://www.iesdouyin.com/web/api/v2/aweme/post/?
# sec_uid=MS4wLjABAAAAywJ4T_WcOFGjZ-pmCR2VmI7u4LWghclHEfgiS75UXpI
# &count=21
# &max_cursor=1571221850000
# &aid=1128
# &_signature=2RlnSxAQhOMxw0U2Qrcss9kZZ1
# &dytk=bf3bd94f63d5dd85cfabea97ca33734d
import requests
import time
import json
import re
url = "https://www.iesdouyin.com/web/api/v2/aweme/post"
data = {
'sec_uid': 'MS4wLjABAAAAywJ4T_WcOFGjZ-pmCR2VmI7u4LWghclHEfgiS75UXpI',
'count': '21',
'max_cursor': '1571221850000',
'aid': '1128',
'_signature': '2RlnSxAQhOMxw0U2Qrcss9kZZ1',
'dytk': 'bf3bd94f63d5dd85cfabea97ca33734d'
}
headers = {
'cookie': "_ga=GA1.2.430553677.1572184021; _gid=GA1.2.699555452.1573015895",
'user-agent': "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
}
# response = requests.request("POST", url, headers=headers, params=data)
while True:
response = requests.get(url, headers=headers, params=data)
if len(response.text) > 100:
str_json = json.loads(response.text)
for aweme in str_json['aweme_list']:
r = requests.get(aweme['video']['download_addr']['url_list'][0], stream=True, headers=headers)
fileName = re.findall(r"(.+?)#", aweme['desc'])
if r.status_code != 200:
print("【%s】 下载失败!" % fileName)
continue
if len(fileName) > 1:
fileName = str(fileName[0])
else:
fileName = str(aweme['aweme_id'])
with open(fileName + '.mp4', "wb") as mp4:
r = r.content
mp4.write(r)
print("【%s】 下载成功!" % fileName)
if not str_json['has_more']:
print('已全部下载完毕,关闭下载!')
break
data['max_cursor'] = str_json['max_cursor']
time.sleep(1)