实战 | 利用Delta Lake使Spark SQL支持跨表CRUD操作

供稿 | eBay ADI-Carmel Team
作者 | 金澜涛
编辑 | 顾欣怡
本文7309字,预计阅读时间22分钟
导读
本文介绍eBay Carmel团队利用Delta Lake,使Spark SQL支持Teradata的Update/Delete语法。主要从源码角度介绍了CRUD操作的具体实现和优化,以及delta表的管理工作。希望对同业人员有所启发和帮助。
摘要
大数据处理技术朝传统数据库领域靠拢已经成为行业趋势,目前开源的大数据处理引擎,如Apache Spark、Apache Hadoop、Apache Flink等等都已经支持SQL接口,且SQL的使用往往占据主导地位。各个公司使用以上开源软件构建自己的ETL框架和OLAP技术,但在OLTP技术上,仍然是传统数据库的强项。其中的一个主要原因是传统数据库对ACID的支持。具有ACID能力的传统商用数据库基本都实现了完整的CRUD操作。而在大数据技术领域,由于缺少ACID的支持,基本只实现了C/R操作,对U/D操作很少涉及。
eBay数据仓库的部分基础设施是构建在商用数据产品Teradata之上的,近年来,随着公司整体朝开源技术迁移,数据仓库的基础设施已基本迁移到Apache Hadoop、Apache Spark平台。但要完全从Teradata上迁移下来,必须构建具有相同能力的SQL处理引擎。在Teradata上的分析型SQL,有超过5%的查询使用Update/Delete操作,目前Apache Spark并不具备这个能力。
本文介绍eBay Carmel团队利用Delta Lake,使Spark SQL支持Teradata的Update/Delete语法。对比标准SQL的Update/Delete语法,以及目前尚未正式发布的Apache Spark 3.0 提供的语法(不含实现),我们还实现了Teradata的扩展语法,可以进行跨表更新和删除的SQL操作。
1.
简介
Carmel Spark是Carmel团队基于Apache Spark进行魔改的SQL-on-Hadoop引擎。主要改善了交互式分析的使用体验,提供即席查询(ad-hoc)服务。Carmel Spark是“Teradata退出”项目的重要组成部分,在功能性和性能上,都做了大量开发和优化。例如全新的CBO、并发调度、物化视图、索引、临时表、Extended Adaptive Execution、Range Partition、列级访问权限控制,以及各类监控和管理功能等,目前已经在线上使用且满足业务需求。
但由于Apache Spark缺少ACID事务能力,并没有提供Update/Delete语法。去年年初,Databricks开源了存储层Delta Lake,为Apache Spark 提供可伸缩的 ACID 事务,提供事务管理、统一流批、元数据管理、版本回溯等数据库领域常见功能。一年过去了,Delta Lake的版本也更新到了0.5.0,但开源版本始终没有提供Update/Delete的SQL实现。目前只提供Dataframe API,用户需通过编写代码来对数据进行更新和删除等操作。此外,根据Apache Spark 3.0分支上提供的SQL语法接口,也只支持基本的单表Update/Delete操作,对于复杂的带有join语义的跨表操作,则完全不支持。而Teradata用户已经在广泛使用扩展的SQL语法对数据进行更新和删除操作。
基于Delta Lake存储层提供的ACID事务能力,Carmel Spark实现了Update/Delete的SQL语法,且该语法完全兼容Teradata的扩展语义,即能进行跨表的更新和删除。同时,我们拓展了delta表的数据分布,支持bucket delta表,并对其进行了bucket join等优化。此外,由于Carmel Spark集群部署是多租户的,所以同一套代码会长期运行在YARN的不同队列中。虽然Delta Lake存储层提供了良好的事务隔离性,但仍会出现重复操作的风险(非同一事务)。因此,我们使用delta表本身来治理delta表,即将所有delta表的元信息存储在一张delta表中,通过对该元数据表的增删改查操作,来对用户使用的所有delta表进行管理。
本文的组织结构如下:第二节介绍相关技术和产品;第三节阐述项目的整体架构和实现;第四节详细介绍如何利用Delta Lake使SparkSQL支持CRUD操作;第五节介绍delta表的bucket优化;第六节介绍delta表的自治和管理;最后两节分别谈一下未来的工作和对本文的总结。
2.
相关工作
2.1
Spark SQL
Apache Spark[1]是一款开源的分布式计算框架,诞生于2009年加州大学伯克利分校AMPLab的一个研究项目,于2013年捐赠给了Apache软件基金会。在处理结构化数据上,Spark提供了DataFrame API和Spark SQL模块。DataFrame API允许用户通过表、行和列的概念对数据进行操作。
同样,用户可以使用SQL来操作它们。Spark SQL模块将SQL查询转成一棵查询计划树(query plan tree)。给定一个原始SQL查询,该查询首先经词法分析和解析,转换为逻辑查询计划(logical plan)。该逻辑查询计划经过查询优化器,产生优化的查询计划(optimized plan)。最终,优化的查询计划被转换为物理计划(physical plan),物理计划会被转成job和task最终提交到集群上执行。
Apache Spark 3.0开始,SQL模块提供了Update/Delete的语法定义,定义在Antlr4的语法文件里,但并没有具体实现,而是交由第三方实现。如图1所示:

图1 Spark 3.0 的Update/Delete语法
(点击可查看大图)
2.2
Teradata
Teradata[2]是Teradata Corp.开发的可横向扩展的关系型数据库管理系统,设计用于分析型查询,主要用于数据仓库领域,采用大规模并行处理(MPP)架构。Teradata对Update/Delete等语法支持非常完备,除了ANSI SQL: 2011定义的标准Update/Delete语法,Teradata还做了大量扩展,如跨表更新和删除。其所提供的丰富的语法也给我们迁移到Spark带来了挑战。图2所示为Teradata支持的更新和删除语法:
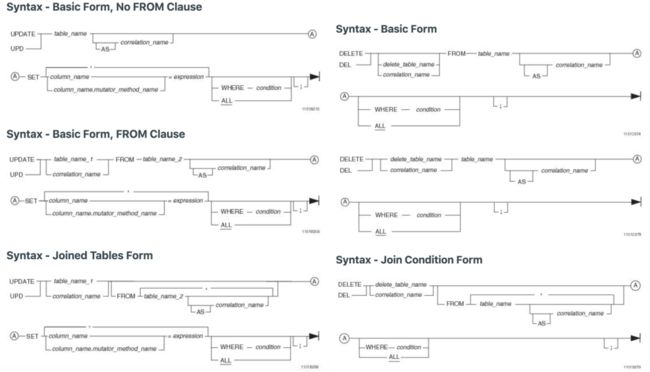
图2 Teradata的单表以及跨表Update/Delete语法(点击可查看大图)
2.3
Delta Lake
2018年初,Databricks开源了存储层Delta Lake[3],为Apache Spark 提供可伸缩的 ACID 事务,提供事务管理、统一流批、元数据管理、版本回溯等数据库领域常见功能。Delta Lake将其数据存储在Parquet文件中,并提供ACID事务。它使用名为Delta Log的事务日志来跟踪对表所做的所有更改。
与开源的Delta Lake相比,Databricks内部版本可以通过SQL来进行Update/Delete操作,而目前开源版本只支持DataFrame的API,只能通过Parquet[4]文件推断表的Schema信息,对Hive Metastore[5]的支持较弱,且不支持bucket表等等。Apache Iceberg[6]和Apache Hudi[7]虽然实现形式与Delta Lake不同,但在Update/Delete的SQL语法支持上,目前都不完善。表1给出了这三个系统的对比(截止2019年11月)。

表1 三个ACID库的简单对比
(点击可查看大图)
3.
项目概述
有了Delta Lake在存储层提供ACID事务保障,我们的主要工作就是利用Delta Lake,在我们的Spark版本上实现和Teradata相同的Update/Delete功能。要达到这个目标,有以下任务有待完成:
1. Delta Lake目前只支持Apache Spark 2.4+版本,而Carmel团队使用的Spark版本是基于2.3版本的,所以我们改了Delta Lake的部分实现并为我们的Spark版本打了一些补丁。
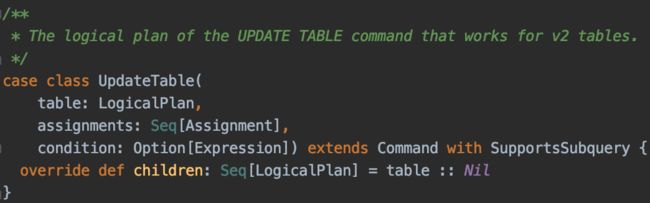
2. Spark 3.0中虽然没有Update/Delete语法的具体实现,但仍然在Catalyst[8]中加入了相关的逻辑计划节点。不过这些新增的接口都是基于DataSourceV2的,我们需要将这部分代码在DataSourceV1上进行重写:
(点击可查看大图)
3. Teradata支持跨表的Update/Delete语法,目前Delta Lake和Spark都不支持,我们需要自己实现带join的跨表连接更新和删除操作。
4. Delta Lake目前对Catalog[9]的访问还不成熟,delta表的schema是通过Parquet文件推断出来的,通过Catalog访问Hive Metastore是使用SQL访问delta表的重要一环。
5. 由于上述原因,delta表无法识别bucket信息,更没有考虑读写bucket表时的分布(distribution)。
6. 在以上3,4,5步骤完成之后,还要对跨表操作进行优化,这里将主要介绍bucket join的优化。
7. 开源版本的Delta Lake缺少一定的管理机制,需要实现一些自动化管理功能,如自动清理和合并文件等。
4.
CRUD的实现
4.1
前置工作
首先,要在我们的Spark 2.3内部版本中使用Delta Lake,就需要从社区打一些补丁。这里重点说一下SPARK-28303。
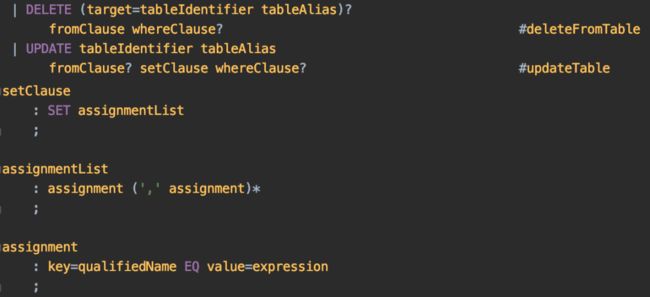
SPARK-28303引入了基于DataSource V2的DELETE / UPDATE / MERGE语法。由于Spark 2.3不支持DataSource V2,因此我们需要将此功能移植到V1版本,在ddl.scala中增加了UpdateTableStatement和DeleteFrom Statement。Antlr4[10]的语法结构如下所示:
(点击可查看大图)
4.2
实现单表更新
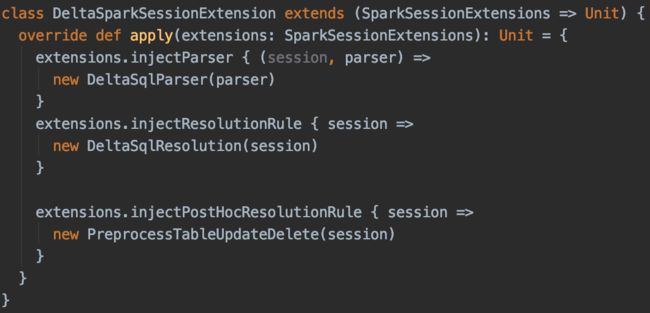
Delta Lake目前不支持Update/Delete SQL的解析,我们增加了两个类:DeltaSqlResolution和PreprocessTableUpdateDelete,通过SparkSessionExtensions注入到Analyzer:
(点击可查看大图)
DeltaSqlResolution主要是用于解析condition和assignments表达式:
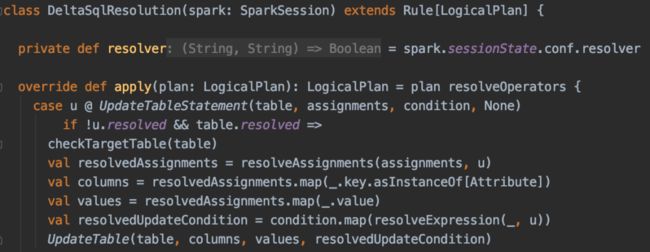
(点击可查看大图)
再由PreprocessTableUpdateDelete生成RunnableCommand。如果是delta表的话,这里可以从LogicalRelation中拿出delta表的TahoeFileIndex(在DataSource.scala的resolveRelation中添加的),如果是非delta表,则会抛出AnalysisException。
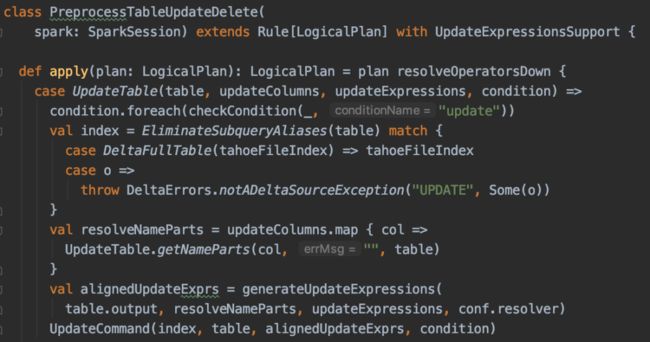
(点击可查看大图)
UpdateCommand是Delta Lake自带的类,我们对其改动不多,主要改了如下几个地方:
一个是鉴于目前Update操作不会更新表的统计信息(Statistics),造成delta表在进行join等操作时无法正确判断是走SortMergeJoin还是BroadcastJoin,我们增加了catalog的访问使delta表的CRUD操作都能更新表的统计信息。
第二个改动是增加了update/delete的row级别metrics信息。Delta Lake已经发布的0.5.0版本update和delete缺少row级别的metrics。社区最新的代码已经做了添加,但当更新或删除单个partition或全表时仍旧是缺少的,而我们的实现在无论何种情况下都做了收集。
4.3
实现跨表更新
目前Spark3.0定义的Update/Delete语法不支持跨表操作,而跨表更新和删除操作却十分普遍,比如更新目标表中具有(在inner join情况下)或可能没有(在left outer join情况下)另一个表匹配行的行。
许多数据库都提供跨表更新和删除的语法。下面给出了几种常用数据库的跨表更新的例子。
MYSQL[11]跨表更新:

Teradata的跨表更新:

PostgreSQL[12]的跨表更新:

Teradata的语法和PostgreSQL的基本一致,只是FROM子句和SET子句顺序调换了一下,而MYSQL支持在一条SQL里同时更新多张表。Carmel Spark目前参考的是Teradata的语法,同时在DeltaSqlResolution中增加了带join的解析:

(点击可查看大图)
和单表Update一样,首先对condition和SET子句进行解析。不同的是,除了被更新的target是一个LogicalRelation以外,这里的source可以是一个LogicalRelation,也可以是多张表连接在一起的join plan。
我们从WHERE条件的condition中分离出哪些是target和source之间的join criteria,哪些是source中自身的join criteria(source可以是多表join的plan),以及哪些是分别作用在target或source上的普通Filter。同样地,再由PreprocessTableUpdateDelete生成Runnable Command:
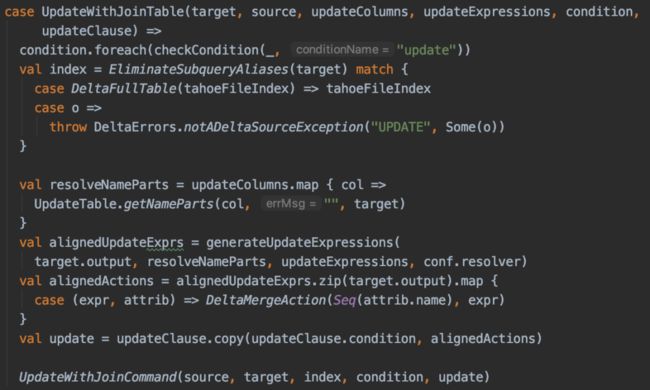
(点击可查看大图)
上述代码中,跨表更新和单表更新的区别是多构建了一个DeltaMergeAction。可见跨表更新的实现参考了MergeInto。
UpdateWithJoinCommand是跨表更新的主要执行类,一共分为三步:
1. 通过将需要被更新的target表和source(可以是一个带join的plan)进行内连接(inner join)找出所有会被更新的行所涉及的文件,标记为removeFiles。这一步还能简化后续的步骤,例如不涉及任何文件或者只涉及partition目录时,不用全表执行第2步。
2. 将target和source使用左外连接(left outer join),对于join条件匹配的行,使用build side iterator的数据(右表),不匹配的行使用stream side iterator的数据(左表)。将数据写出到target表,写出的数据文件标记为addedFiles。
3. 将1中removeFiles和2中的addedFiles写入transaction log中,即delta log。
删除操作和更新操作基本类似,可以视为更新操作的简化版,这里就不展开了。
4.4
实现SELECT/INSERT
对delta表的读操作(SELECT)实际上是对delta表的解析。Delta表是DataSource表的一种。在FindDataSourceTable这条rule中,通过resolveRelation方法对delta表进行特殊处理:

(点击可查看大图)
这里我们把catalogTable对象传入到DeltaDataSource的createRelation方法里。补充一点,之所以这个case可以匹配到DeltaDataSource,是因为我们在ConvertToDelta Command里,通过alterTable,把provider从parquet改成了delta:

(点击可查看大图)
回到createRelation。通过传入的catalogTable对象,我们在DeltaLog.scala里将表的信息填到HadoopFsRelation里面:

(点击可查看大图)
Delta表的INSERT操作也很简单。在DataSourceStrategy中添加InsertIntoData SourceCommand:

(点击可查看大图)
普通delta表的insert我们没有进行修改,这里就不展开了,下一节讲bucket表的insert时再详细阐述这部分的改动。
4.5
创建Delta表
创建delta表(CREATE操作)目前完全复用了普通Parquet表的CREATE,只是需要在建完表后执行CONVERT TO DELTA命令。我们简单做了一些修改,使其可以CONVERT一张空的Parquet表,目前社区版是不支持的。其他的修改主要是针对管理上的,在第六节会详细介绍。
到此,CRUD功能的SQL实现已经基本完成。在这一节里,我们引入了跨表更新操作,但是跨表更新涉及到join算子,这在大表之间进行更新操作时会有性能问题。在下一节中会介绍如何针对bucket表进行优化。
5.
Bucket优化
跨表更新操作中,会有多次连接算子,当进行连接操作的表是上TB数据量的大表时,整个更新操作就会变得非常慢。甚至,大量数据的SortMergeJoin可能抛出OutOfMemory。事实上,在我们实际的业务场景中,就存在着大量的大表更新。例如被更新的表往往是一张几个TB的大表,然后和另一张或几张中型表进行连接操作。为了优化这类SQL,最容易想到的方法是通过bucket join来避免大表数据的shuffle。现实中,我们用户的许多大表也的确做了分桶(bucket)。
然而目前delta表并不支持分桶表,相关代码的BucketSpec都被默认填了None,对更新和删除的操作也没有考虑数据的分布(Distribution)。那么该如何实现bucket表的数据分布呢?
5.1
创建delta bucket表和读取
首先和Parquet表一样,我们需要在建表时指定分桶字段。形如:CLUSTERED BY (col*) [SORTED BY (col*) ] INTO number BUCKETS。
在4.3小节中我们提到了在ResolveRelation时将CatalogTable对象传入了HadoopFsRelation。有了这个CatalogTable对象,就可以帮我们在后续的各类操作中识别bucket表了。
5.2
插入数据到delta bucket表
上一步只是告诉Spark,这是一张bucket表,真正写入数据的时候发现数据并没有分桶分布。这是因为Insert操作在delta表上是走InsertIntoDataSource -> InsertIntoDataSourceCommand的,而不是通过DataWritingCommand,所以也就走不到ensureDistributionAndOrdering的逻辑。以下代码是社区版InsertIntoDataSourceCommand的实现:
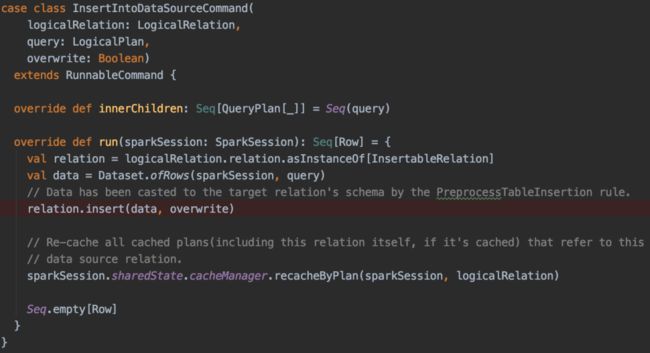
(点击可查看大图)
如上代码所示,它的实现非常简单,将需要insert的逻辑计划“query”封装成一个data frame,然后传入到实现类的insert方法里。在Delta Lake中这个data frame会被传入到TransactionalWrite的writeFiles方法中。最终从这个data frame中取出physical plan并传入DataFormatWriter的write方法。之后就是真正的生成job并分发执行了。
从整个流程可以看出,从一开始的逻辑计划对象“query”到最后的物理计划,并没有机会进行数据分布的实现。所以不管在建表时是否指定分桶,插入数据时都不会满足数据分布。
鉴于目前DataSource并没有考虑数据分布的问题,我们在resolution阶段就需要进行处理。大体就是在Catalyst里增加一个InsertIntoDataSource的逻辑计划节点和一个InsertIntoDataSourceExec的物理计划节点。在InsertIntoDataSourceExec这个物理计划中实现了requiredChildDistribution和requiredChildOrdering方法(代码可以参考InsertIntoHadoopFsRelationCommand的requiredDistribution和requiredOrdering方法)。
这里说一下整体流程。首先,DataSourceStrategy原本是匹配到了InsertIntoTable就会将逻辑计划“query”原封不动地传入InsertIntoDataSource Command。我们现在做出如下改变:增加一个新的逻辑计划节点InsertIntoDataSource,为其添加partition,bucket等信息,并将“query”作为该新节点的child:

(点击可查看大图)
然后在SparkStrategy.scala的BasicOperators里将InsertIntoDataSource节点转成物理计划节点InsertIntoDataSourceExec,通过planLater(i.query)得到物理计划作为该物理节点的child。这样InsertIntoDataSourceExec的requiredChildDistribution和requiredChildOrdering方法就可以对数据进行分布了:
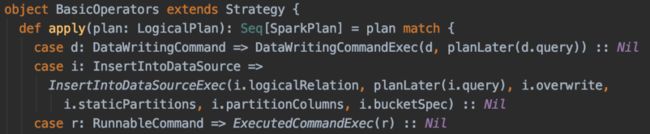
(点击可查看大图)
5.3
在跨表更新或删除操作中利用bucket join
到目前为止,对delta表的改造已经使其具有了bucketSpec字段和数据分布的特性。在跨表更新或删除时,无论是inner join还是left outer join,只要target和source都是bucket表且满足bucket join条件,就能走bucket join而不是SortMergeJoin。这就解决了大表之间join产生大量shuffle带来的性能问题。
下面这个例子是跨表更新一张3.9TB的表,source则是一张5.2TB的表。图3所示是left outer join阶段,右表虽然有一个Filter,但是仍然不满足broadcast join阈值,这个更新操作在非bucket join的情况下,会造成大量Executor OOM,最终导致job失败。通过引入bucket join,该job在2分钟左右就能顺利完成。从图3可以看到在SortMergeJoin的前后,已经没有ShuffleExchange了。
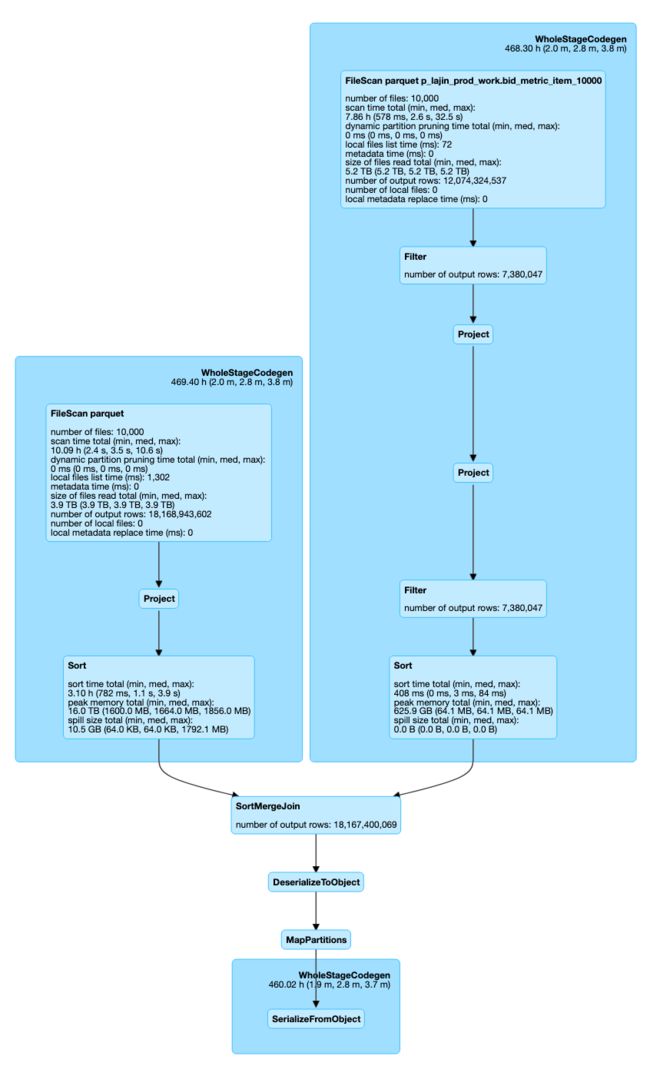
图3 跨表更新中利用bucket join避免shuffle
(点击可查看大图)
但是,这里仍然可能存在问题,因为被更新的表仍然是一张bucket表,而图3的输出没有考虑数据的分布。对于bucket表尚不满足数据分布的情况,我们需要在SortMergeJoin之后增加一轮HashRepartition,以保证最终的结果输出符合被更新表的数据分布特性:


(点击可查看大图)
6.
Delta的自治和管理
介绍完CRUD的功能和相关优化,这一节讲一下我们是如何管理delta表的,主要包括:如何统计delta的使用情况,如何自动进行文件清理,如何管理TimeTraval[13]等。
在这之前我们需要简单介绍一下eBay Carmel Spark的基本架构。eBay的Carmel Spark平台是计算存储分离的。数据存储有一个专门的Hadoop集群(Apollo),Carmel Spark集群(Hermes)主要是由大内存加SSD的计算节点组成,通过YARN[14]进行调度。除了本地SSD以外,也有一部分存储容量搭建了一个小容量的HDFS,主要是拿来做Relation Cache和物化视图,这部分以后有机会另起一篇文章进行介绍。
我们使用Spark Thriftserver来提供JDBC和ODBC服务,但所有的Thriftserver并不是固定在某个机器上的,而是通过YARN进行调度,通过cluster mode将Spark Thriftserver提交到集群内部。同时,根据Budget Group对YARN集群分queue,不同的Budget Group有一个YARN的queue,例如广告部门有一个queue,数据部门有一个queue,每个queue可以有多个Spark Thriftserver。Carmel Spark对scheduler模块做过大量并发优化,经过压测,一个Driver调度起来的任务能把200台物理机的所有CPU压满。所以Driver调度并不是瓶颈,目前最大的一个queue仅使用一个Thriftserver就可以调度近7000个executors。
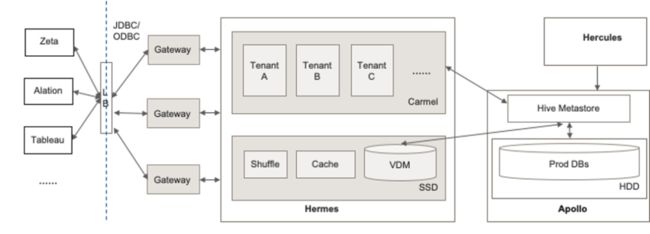
图4 Carmel Spark集群部署
(点击可查看大图)
目前有多少个queue,就有多少个Thriftserver,也就有多少个Application。但不同的Thriftserver仍然共享了一些组件,例如HDFS,Hive Metastore等。这就要求我们对所有的queue做一些管理。例如在物化视图功能中,当对一张基础表构建物化视图后,所有的queue都需要在内存里构建一些逻辑计划树。delta表的管理也类似,不过相比物化视图简单的多。例如我们要对所有的delta表进行自动化的文件清理工作,一种方式是起一个后台线程遍历Hive Metastore的所有表,对provider是delta的表进行处理。这样的好处是不需要跨Thriftserver进行任何消息的同步,坏处自然是不断遍历Hive Metastore带来的压力(多集群公用的Hive Metastore压力已经比较大了)。所以我们使用了一种更加直观的方式进行管理,即用delta表来管理delta表。
我们创建了一张名为carmel_system.carmel_ delta_meta的表,记录了如表名、owner、deltalog路径、是否自动清理、清理周期等元信息,并将其CONVERT成一张delta表。所以carmel_delta_meta表的第一条记录就是自己的信息。然后我们提供了一套操作这张表的API,以调用静态方法的方式放在DeltaTableMetadata类的半生对象中:
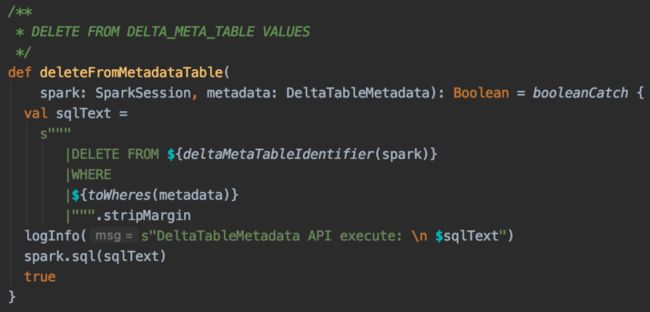
如下所示,当用户对一张表执行CONVERT TO DELTA命令时,会生成一个事件,通过DeltaTableListener捕获后将该delta表的元信息写入carmel_delta_meta,当用户删除delta表时,DropTableEvent同样可以触发上图的删除操作API,从carmel_delta_meta删除这条记录:
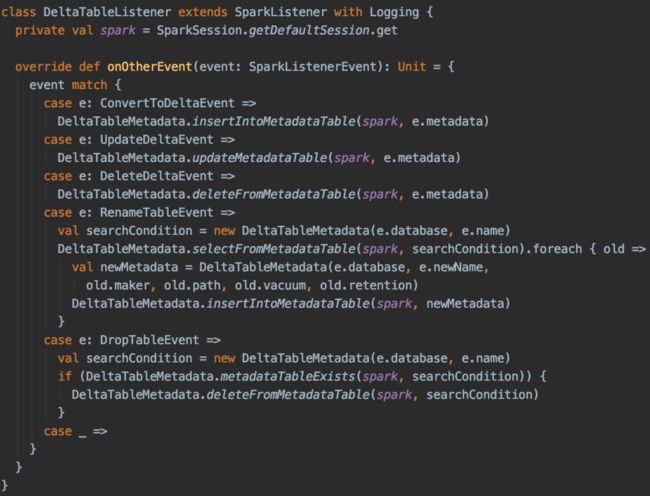
(点击可查看大图)
另外在YARN的保留队列(reserved queue只允许管理员权限连接)里启动一个DeltaValidate线程,通过读取carmel_delta_meta中的数据进行验证,触发如删除记录等操作。同时,如果用户在CONVERT TO DELTA时指定了Vacuum保留时间:
![]()
或是一开始没有指定保留时间,后续通过命令VACUUM AUTO RUN进行修改:
![]()
DeltaValidate线程会自动生成Vacuum任务,并丢到Vacuum线程池调度执行。这里就不贴代码了。整个架构如图5所示:

图5 delta表的自治管理
(点击可查看大图)
此外,我们还增加了TimeTravel的SQL语义,用户可以通过在SELECT命令里增加AT关键字,单次读取delta表某个version的快照。也可以通过ROLLBACK命令永久回到某个版本:

(点击可查看大图)
通过carmel_delta_meta中记录的一些表的血缘信息,可以实现delta表的及联回滚。在某个delta表rollback后,触发器根据carmel_delta_meta的血缘信息,自动回滚其他相关表(这需要事先定义在carmel_delta_meta的rollback依赖树和触发器条件,该功能目前还未上线)。
上面介绍了通过delta表来管理delta表的方式,这一方法能很好地帮我们解耦队列同步和外部系统依赖的问题,既方便灵活,又快捷安全。
7.
未来的工作
7.1
持续的性能优化
Carmel Spark项目经过两年的技术迭代,已经具备非常多的功能和优化,例如Range Partation、Optimized Bucket Join、Broadcast/Local Cache、Extended Adaptive Execution、Parquet File Index、Materialized View、ACL、Volcano CBO、Adaptive Runtime Filter、Mutiple Files Scan等,如何让新的功能如CRUD复用以上优化和特性,也变得越来越富有挑战了。例如我在测试时发现Broadcast Cache和Mutiple Files Scan两个功能在和CRUD功能集成时存在bug,又或者目前的Volcano CBO和Parquet File Index还不能应用在delta表上等。
此外,在跨表更新操作上,大表连接的优化目前只针对bucket表,但是当两张非bucket表进行连接时,性能仍然不够好。这里就有多个优化点,比如Adaptive Runtime Filter,就是Join Pushdown,可以将join表的min/max或者join key的bloomfilter推到两边进行过滤,以减少参与连接的记录数,目前只完成了在inner join下的部分功能。
7.2
更完备的语义
除了性能的优化,Carmel Spark作为Teradata战略代替品,需要尽可能兼容Teradata的语义,后续如果有用户需要MERGE INTO或者UPSERT操作,这部分还要继续扩展。此外,目前UPDATE和DELETE的WHERE条件还不支持子查询,CONVERT TO DELTA不支持Parquet Format的Hive表,这些都将是后续的工作。
7.3
高度自治的管理
第6节最后提到过的及联回滚功能,以及对delta表的审计和监控都属于平台管理的范畴。这些有的已经具备成熟的解决方案,如我们已经有完全和Teradata对标的列级访问权限控制和审计功能。有的还在不断完善,如用于File Index和Materialized View的Hive Metastore同步机制还没有上线,目前用的还是过渡方案。这部分不止针对delta表,有些还可以应用于整个Carmel Spark。
8.
实施和总结
8.1
技术之外
最后简单说一下项目的情况。这个项目找到我的时候是在2019年的10月底,我刚上线完Spark临时表功能,物化视图项目也还陆陆续续有一些bug fix的工作要做,所以真正开始投入去做应该是在11月中旬。CRUD功能目标上线时间是在2020年的2月份,不像物化视图这类优化型项目,功能型项目承诺上线时间的要求往往更高一些。加之期间还有春节假期,oncall和各种bug fix的工作,对于该项目来说排期还是比较紧的。
此外,我们对Delta Lake的成熟度和性能也比较担忧(现实也验证了Delta Lake的开源版本在SQL成熟度上的确不足)。实践中发现除了ACID这个核心功能不用操心以外,基本上都要二次开发。最后和我们使用的基于社区2.3版本进行魔改的Carmel Spark的集成相比,也存在许多挑战。
再说一下为什么选择Delta Lake。目前来看,除了Delta Lake之外,Apache Hudi和Apache Iceberg也能完成ACID的功能。当时选择Delta Lake一是因为它是Databricks的产品,在Databricks内部版本比较成熟,长期来看其开源版本也会和Apache Spark更加紧密。二是当时公司内部还有一个准实时数仓的项目,立项也是使用Delta Lake。考虑到尽可能保持技术栈一致,我们选择了Delta Lake,而且单从这个项目上Apache Hudi和Apache Iceberg并没有特别的优势。
最后说一下用户支持,其实做一个项目最复杂也是最耗时的并不是编码阶段,而是上线后接受用户的考验。该功能的第一批用户是来自eBay瑞士的财务部门分析师团队,因为不在同一个时区,春节假期里几乎每晚都会通过Zoom和我沟通。这种在用户和开发者之间的持续交流,使得一些隐藏的问题即时浮现出来,用户也得到了较好的使用体验。我们的Carmel Spark每周都会有半个小时的例行发布窗口,用户遇到的bug几乎都在下次发布窗口时得到了修复。在这一周中,我们也会找出workaround方式,帮助用户进度的推进。目前该功能已经在所有队列上启用,越来越多的用户开始参与试用。
8.2
总结
本文从源码角度讲解如何利用Delta Lake使老版本的Spark SQL支持跨表的CRUD操作,以及我们所做的优化和管理工作。最后,简单介绍了未来的工作方向以及项目实施上的一些感悟,希望能对阅读者有所帮助。
参考文献
[1] https://spark.apache.org/
[2] https://www.teradata.com/
[3] https://delta.io/
[4] https://parquet.apache.org/
[5] https://hive.apache.org/
[6] https://iceberg.apache.org/
[7] https://hudi.apache.org/
[8]https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
[9]http://blog.madhukaraphatak.com/introduction-to-spark-two-part-4/
[10] https://www.antlr.org/
[11] https://www.mysql.com/
[12] https://www.postgresql.org/
[13]https://databricks.com/blog/2019/02/04/introducing-delta-time-travel-for-large-scale-data-lakes.html
[14]https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
