AutoML自动模型压缩再升级,MIT韩松团队利用强化学习全面超越手工调参
模型压缩是在计算资源有限、能耗预算紧张的移动设备上有效部署神经网络模型的关键技术。
在许多机器学习应用,例如机器人、自动驾驶和广告排名等,深度神经网络经常受到延迟、电力和模型大小预算的限制。已经有许多研究提出通过压缩模型来提高神经网络的硬件效率。
模型压缩技术的核心是确定每个层的压缩策略,因为它们具有不同的冗余,这通常需要手工试验和领域专业知识来探索模型大小、速度和准确性之间的大设计空间。这个设计空间非常大,人工探索法通常是次优的,而且手动进行模型压缩非常耗时。
为此,韩松团队提出了 AutoML 模型压缩(AutoML for Model Compression,简称 AMC),利用强化学习来提供模型压缩策略。

论文地址:
https://arxiv.org/pdf/1802.03494.pdf
负责这项研究的MIT助理教授韩松博士表示:
“算力换算法”是当今AutoML系列工作的热点话题,AMC则属于“算力换算力”:用training时候的算力换取inference时候的算力。模型在完成一次训练之后,可能要在云上或移动端部署成千上万次,所以inference的速度和功耗至关重要。
我们用AutoML做一次性投入来优化模型的硬件效率,然后在inference的时候可以得到事半功倍的效果。比如AMC将MobileNet inference时的计算量从569M MACs降低到285M MACs,在Pixel-1手机上的速度由8.1fps提高到14.6fps,仅有0.1%的top-1准确率损失。AMC采用了合适的搜索空间,对压缩策略的搜索仅需要4个GPU hours。
总结来讲,AMC用“Training算力”换取“Inference算力”的同时减少的对“人力“的依赖。最后,感谢Google Cloud AI对本项目的支持。
Google Cloud 研发总监李佳也表示:“AMC是我们在模型压缩方面的一点尝试,希望有了这类的技术,让更多的mobile和计算资源有限的应用变得可能。”
“Cloud AutoML 产品设计让机器学习的过程变得更简单,让即便没有机器学习经验的人也可以享受机器学习带来的益处。尽管AutoML有很大的进步,这仍是一项相对初期的技术,还有很多方面需要提高和创新。”李佳说。
用AI做模型压缩,完全不需要人工
研究人员的目标是自动查找任意网络的压缩策略,以实现比人为设计的基于规则的模型压缩方法更好的性能。
这项工作的创新性体现在:
1、AMC提出的learning-based model compression优于传统的rule-based model compression
2、资源有限的搜索
3、用于细粒度操作的连续行动空间
4、使用很少的 GPU 进行快速搜索(ImageNet 上 1 个 GPU,花费 4 小时)
目标:自动化压缩流程,完全无需人工。利用 AI 进行模型压缩,自动化,速度更快,而且性能更高。
这种基于学习的压缩策略优于传统的基于规则的压缩策略,具有更高的压缩比,在更好地保持准确性的同时节省了人力。
在 4×FLOP 降低的情况下,我们在 ImageNet 上对 VGG-16 模型进行压缩,实现了比手工模型压缩策略高 2.7%的精度。
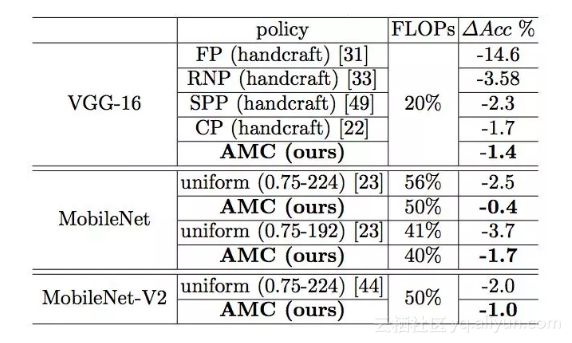
我们将这种自动化压缩 pipeline 应用于 MobileNet,在 Android 手机上测到 1.81 倍的推断延迟加速,在 Titan XP GPU 上实现了 1.43 倍的加速,ImageNet Top-1 精度仅下降了 0.1%。
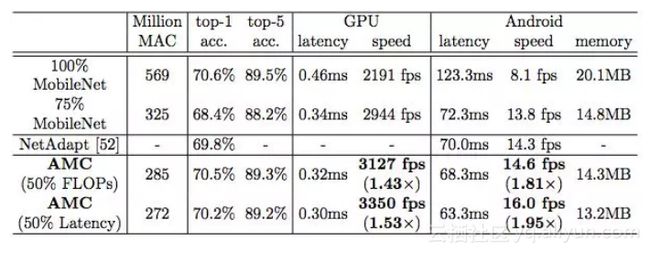
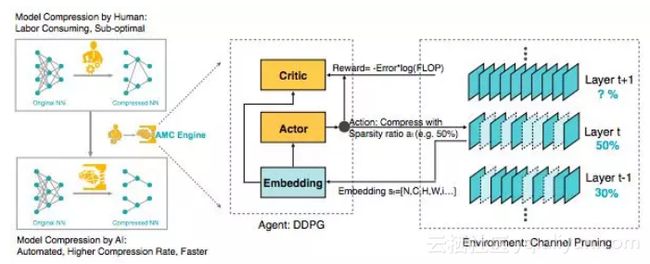
图 1:AutoML 模型压缩(AMC)引擎的概览。左边:AMC 取代人工,将模型压缩过程完全自动化,同时比人类表现更好。右边:将 AMC 视为一个强化学习为题。
以前的研究提出了许多基于规则的模型压缩启发式方法。但是,由于深层神经网络中的层不是独立的,这些基于规则的剪枝策略并非是最优的,而且不能从一个模型转移到另一个模型。随着神经网络结构的快速发展,我们需要一种自动化的方法来压缩它们,以提高工程师的效率。
AutoML for Model Compression(AMC)利用强化学习来自动对设计空间进行采样,提高模型压缩质量。图 1 展示了 AMC 引擎的概览。在压缩网络是,ACM 引擎通过基于学习的策略来自动执行这个过程,而不是依赖于基于规则的策略和工程师。
我们观察到压缩模型的精度对每层的稀疏性非常敏感,需要细粒度的动作空间。因此,我们不是在一个离散的空间上搜索,而是通过 DDPG agent 提出连续压缩比控制策略,通过反复试验来学习:在精度损失时惩罚,在模型缩小和加速时鼓励。actor-critic 的结构也有助于减少差异,促进更稳定的训练。
针对不同的场景,我们提出了两种压缩策略搜索协议:
● 对于 latency-critical 的 AI 应用(例如,手机 APP,自动驾驶汽车和广告排名),我们建议采用资源受限的压缩(resource-constrained compression),在最大硬件资源(例如,FLOP,延迟和模型大小)下实现最佳精度 );● 对于 quality-critical 的 AI 应用(例如 Google Photos),我们提出精度保证的压缩(accuracy-guaranteed compression),在实现最小尺寸模型的同时不损失精度。
DDPG Agent
● DDPG Agent 用于连续动作空间(0-1)● 输入每层的状态嵌入,输出稀疏比
压缩方法研究
● 用于模型大小压缩的细粒度剪枝( Fine-grained Pruning)● 粗粒度 / 通道剪枝,以加快推理速度
搜索协议
● 资源受限压缩,以达到理想的压缩比,同时获得尽可能高的性能。● 精度保证压缩,在保持最小模型尺寸的同时,完全保持原始精度。
为了保证压缩的准确性,我们定义了一个精度和硬件资源的奖励函数。有了这个奖励函数,就能在不损害模型精度的情况下探索压缩的极限。
● 对于资源受限的压缩,只需使用 Rerr = -Error● 对于精度保证的压缩,要考虑精度和资源(如 FLOPs):RFLOPs = -Error∙log(FLOPs)

实验和结果:全面超越手工调参
为了证明其广泛性和普遍适用性,我们在多个神经网络上评估 AMC 引擎,包括 VGG,ResNet 和 MobileNet,我们还测试了压缩模型从分类到目标检测的泛化能力。
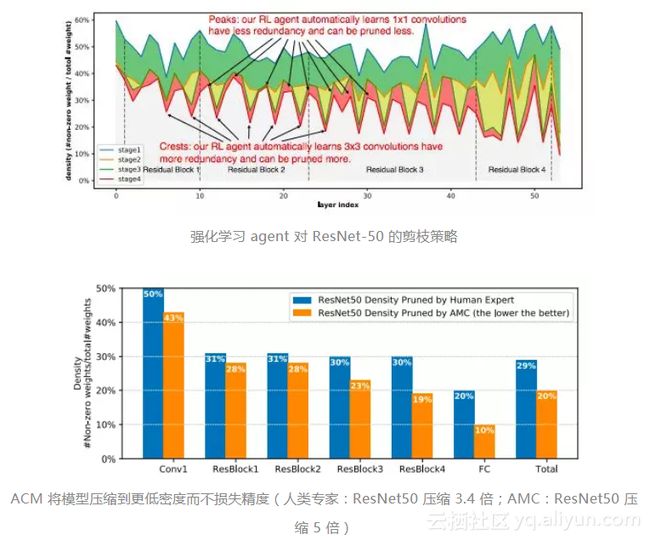
大量实验表明,AMC 提供的性能优于手工调优的启发式策略。对于 ResNet-50,我们将专家调优的压缩比从 3.4 倍提高到 5 倍,而没有降低精度。
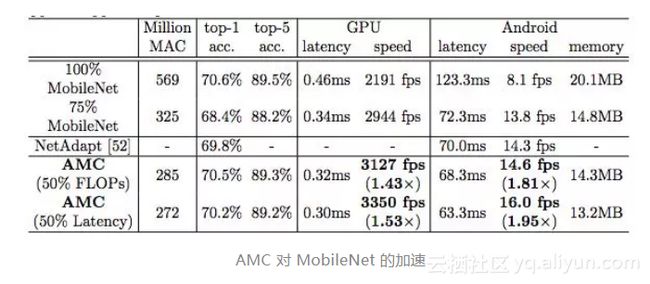
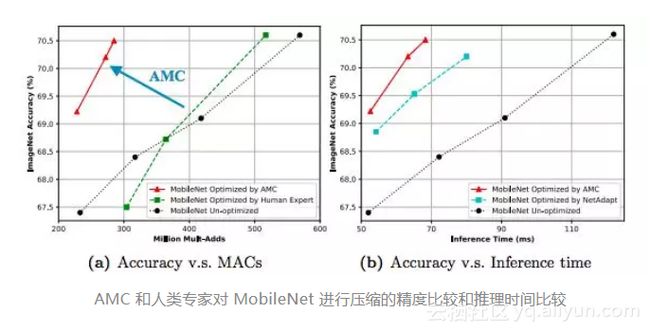
此外,我们将 MobileNet 的 FLOP 降低了 2 倍,达到了 70.2%的 Top-1 最高精度,这比 0.75 MobileNet 的 Pareto 曲线要好,并且在 Titan XP 实现了 1.53 倍的加速,在一部 Android 手机实现 1.95 的加速。
传统的模型压缩技术使用手工的特征,需要领域专家来探索一个大的设计空间,并在模型的大小、速度和精度之间进行权衡,但结果通常不是最优的,而且很耗费人力。
本文提出AutoML模型压缩(AMC),利用增强学习自动搜索设计空间,大大提高了模型压缩质量。我们还设计了两种新的奖励方案来执行资源受限压缩和精度保证压缩。
在Cifar和ImageNet上采用AMC方法对MobileNet、MobileNet- v2、ResNet和VGG等模型进行压缩,取得了令人信服的结果。压缩模型可以很好滴从分类任务推广到检测任务。在谷歌Pixel 1手机上,我们将MobileNet的推理速度从8.1 fps提升到16.0 fps。AMC促进了移动设备上的高效深度神经网络设计。
原文发布时间为:2018-09-12
本文作者:肖琴、闻菲
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”。
原文链接:AutoML自动模型压缩再升级,MIT韩松团队利用强化学习全面超越手工调参