1-3、Python数据结构:序列之列表和元组
1-3、Python数据结构:序列之列表和元组
文章目录
- 1-3、Python数据结构:序列之列表和元组
- 1、序列概念
- 2、通用的序列操作
- 2.1、索引
- 2.2、切片
- 2.2.1、绝妙的简写
- 2.2.2、更大的步长
- 2.3、序列相加
- 2.4、乘法
- 2.5、成员资格
- 3、列表:Python的主力
- 3.1、函数list
- 3.2、基本的列表操作
- 3.2.1、修改列表:给元素赋值
- 3.2.2、删除元素
- 3.2.3、给切片赋值
- 3.3、列表方法
- 3.3.1、append
- 3.3.2、clear
- 3.3.3、copy
- 3.3.4、count
- 3.3.5、extend
- 3.3.6、index
- 3.3.7、insert
- 3.3.8、pop
- 3.3.9、remove
- 3.3.10、reverse
- 3.3.11、sort
- 3.3.12、高级排序
- 4、元组:不可修改的序列
- 5、小结
数据结构是以某种方式(如通过编号)组合起来的数据元素(如数、字符乃至其他数据结构)集合。在Python中,最基本的数据结构为序列(sequence)。序列中的每个元素都有编号,即其位置或索引,其中第一个元素的索引为0,第二个元素的索引为1,依此类推。
1、序列概念
列表和元组的主要不同在于,列表是可以修改的,而元组不可以。这意味着列表适用于需要中途添加元素的情形,而元组适用于出于某种考虑需要禁止修改序列的情形。禁止修改序列通常出于技术方面的考虑,与Python的内部工作原理相关,这也是有些内置函数返回元组的原因所在。
在需要处理一系列值时,序列很有用。在数据库中,你可能使用序列来表示人,其中第一个元素为姓名,而第二个元素为年龄。如果使用列表来表示(所有元素都放在方括号内,并用逗号隔开),将类似于下面这样:
>>> edward = ['Edward Gumby', 42]
序列还可包含其他序列,因此可创建一个由数据库中所有人员组成的列表:
>>> edward = ['Edward Gumby', 42]
>>> john = ['John Smith', 50]
>>> database = [edward, john]
>>> database
[['Edward Gumby', 42], ['John Smith', 50]]
Python支持一种数据结构的基本概念,名为容器(container)。容器基本上就是可包含其
他对象的对象。两种主要的容器是序列(如列表和元组)和映射(如字典)。在序列中,
每个元素都有编号,而在映射中,每个元素都有名称(也叫键)。有一种既不是序列也不是映射的容器,它就是集合(set)。
2、通用的序列操作
有几种操作适用于所有序列,包括索引、切片、相加、相乘和成员资格检查。另外,Python还提供了一些内置函数,可用于确定序列的长度以及找出序列中最大和最小的元素。
2.1、索引
序列中的所有元素都有编号——从0开始递增。你可像下面这样使用编号来访问各个元素:
>>> greeting = 'Hello'
>>> greeting[0]
'H'
字符串就是由字符组成的序列。索引0指向第一个元素,这里为字母H。不同于其他一些语言,Python没有专门用于表示字符的类型,因此一个字符就是只包含一个元素的字符串。
这称为索引(indexing)。你可使用索引来获取元素。这种索引方式适用于所有序列。当你使用负数索引时,Python将从右(即从最后一个元素)开始往左数,因此1是最后一个元素的位置。
>>> greeting[-1]
'o'
对于字符串字面量(以及其他的序列字面量),可直接对其执行索引操作,无需先将其赋给变量。这与先赋给变量再对变量执行索引操作的效果是一样的。
>>> 'Hello'[1]
'e'
如果函数调用返回一个序列,可直接对其执行索引操作。例如,如果你只想获取用户输入的
年份的第4位,可像下面这样做:
>>> fourth = input('Year: ')[3]
Year: 2005
>>> fourth
'5'
代码清单2-1所示的示例程序要求你输入年、月(数1~12)、日(数1~31),再使用相应的
月份名等将日期打印出来。
#!/usr/bin/python3
months = [
'January',
'February',
'March',
'April',
'May',
'June',
'July',
'August',
'September',
'October',
'November',
'December'
]
endings = ['st', 'nd', 'rd'] + 17 * ['th'] \
+ ['st', 'nd', 'rd'] + 7 * ['th'] \
+ ['st']
year = input("Year: ")
month = input("Month(1-12): ")
day = input("Day(1-31): ")
month_number = int(month)
day_number = int(day)
#将表示月和日的数减1,这样才能得到正确的索引
month_number = months[month_number - 1]
ordinal = day + endings[day_number - 1]
print(month_number + ' ' + ordinal + ' ' + year)
然后结果如下:

2.2、切片
除使用索引来访问单个元素外,还可使用切片(slicing)来访问特定范围内的元素。为此,可使用两个索引,并用冒号分隔:
>>> tag = 'Python web site'
>>> tag[9:30]
'http://www.python.org'
>>> tag[32:-4]
'Python web site'
如你所见,切片适用于提取序列的一部分,其中的编号非常重要:第一个索引是包含的第一个元素的编号,但第二个索引是切片后余下的第一个元素的编号。请看下面的示例:
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> numbers[3:6] [4, 5, 6]
>>> numbers[0:1] [1]
简而言之,你提供两个索引来指定切片的边界,其中第一个索引指定的元素包含在切片内,但第二个索引指定的元素不包含在切片内。
2.2.1、绝妙的简写
假设你要访问前述数字列表中的最后三个元素,显然可以明确地指定这一点。
>>> numbers[7:10]
[8, 9, 10]
在这里,索引10指的是第11个元素:它并不存在,但确实是到达最后一个元素后再前进一步所处的位置。明白了吗?如果要从列表末尾开始数,可使用负数索引。
>>> numbers[-3:-1]
[8, 9]
然而,这样好像无法包含最后一个元素。如果使用索引0,即到达列表末尾后再前进一步所处的位置,结果将如何呢?
>>> numbers[-3:0]
[]
结果并不是你想要的。事实上,执行切片操作时,如果第一个索引指定的元素位于第二个索引指定的元素后面(在这里,倒数第3个元素位于第1个元素后面),结果就为空序列。好在你能使用一种简写:如果切片结束于序列末尾,可省略第二个索引。
>>> numbers[-3:]
[8, 9, 10]
同样,如果切片始于序列开头,可省略第一个索引。
>>> numbers[:3]
[1, 2, 3]
实际上,要复制整个序列,可将两个索引都省略。
>>> numbers[:]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
代码清单2-2是一个小程序,它提示用户输入一个URL,并从中提取域名。(这里假定输入的URL类似于http://www.somedomainname.com。)
url = input('Please enter the URL:')
domain = url[11:-4]
print("Domain name: " + domain)
这个程序的运行情况类似于下面这样:
Please enter the URL: http://www.python.org
Domain name: python

2.2.2、更大的步长
执行切片操作时,你显式或隐式地指定起点和终点,但通常省略另一个参数,即步长。在普通切片中,步长为1。这意味着从一个元素移到下一个元素,因此切片包含起点和终点之间的所有元素。
>>> numbers[0:10:1]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
在这个示例中,指定了另一个数。你可能猜到了,这显式地指定了步长。如果指定的步长大于1,将跳过一些元素。例如,步长为2时,将从起点和终点之间每隔一个元素提取一个元素。
>>> numbers[0:10:2]
[1, 3, 5, 7, 9]
numbers[3:6:3]
[4]
显式地指定步长时,也可使用前述简写。例如,要从序列中每隔3个元素提取1个,只需提供步长4即可。
>>> numbers[::4]
[1, 5, 9]
当然,步长不能为0,否则无法向前移动,但可以为负数,即从右向左提取元素。
>>> numbers[8:3:-1]
[9, 8, 7, 6, 5]
>>> numbers[10:0:-2]
[10, 8, 6, 4, 2]
>>> numbers[0:10:-2]
[]
>>> numbers[::-2]
[10, 8, 6, 4, 2]
>>> numbers[5::-2]
[6, 4, 2]
>>> numbers[:5:-2]
[10, 8]
在这种情况下,要正确地提取颇费思量。如你所见,第一个索引依然包含在内,而第二个索引不包含在内。步长为负数时,第一个索引必须比第二个索引大。可能有点令人迷惑的是,当你省略起始和结束索引时,Python竟然执行了正确的操作:步长为正数时,它从起点移到终点,而步长为负数时,它从终点移到起点。
2.3、序列相加
可使用加法运算符来拼接序列。
>>> [1, 2, 3] + [4, 5, 6]
[1, 2, 3, 4, 5, 6]
>>> 'Hello,' + 'world!'
'Hello, world!'
>>> [1, 2, 3] + 'world!'
Traceback (innermost last):
File "" , line 1, in ?
[1, 2, 3] + 'world!'
TypeError: can only concatenate list (not "string") to list
从错误消息可知,不能拼接列表和字符串,虽然它们都是序列。一般而言,不能拼接不同类型的序列。
2.4、乘法
将序列与数x相乘时,将重复这个序列x次来创建一个新序列:
>>> 'python' * 5
'pythonpythonpythonpythonpython'
>>> [42] * 10
[42, 42, 42, 42, 42, 42, 42, 42, 42, 42]
None、空列表和初始化
空列表是使用不包含任何内容的两个方括号([])表示的。如果要创建一个可包含10个元素的列表,但没有任何有用的内容,可像前面那样使用[42]*10。但更准确的做法是使用[0]*10,这将创建一个包含10个零的列表。然而,在有些情况下,你可能想使用表示“什么都没有”的值,如表示还没有在列表中添加任何内容。在这种情况下,可使用None。在Python中,None表示什么都没有。因此,要将列表的长度初始化为10,可像下面这样做:
>>> sequence = [None] * 10
>>> sequence
[None, None, None, None, None, None, None, None, None, None]
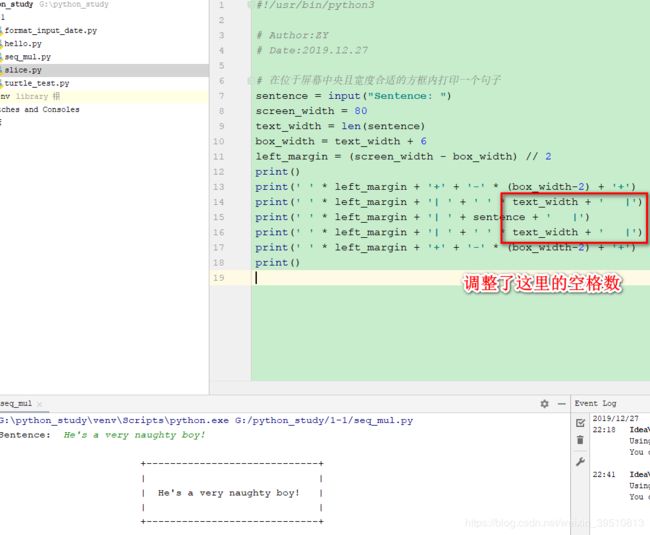
代码清单2-3所示的程序在屏幕上打印一个由字符组成的方框。这个方框位于屏幕中央,宽
度取决于用户提供的句子的长度。这些代码看似很复杂,但基本上只使用了算术运算:计算需要多少个空格、短划线等,以便将内容显示到正确的位置。
# 在位于屏幕中央且宽度合适的方框内打印一个句子
sentence = input("Sentence: ")
screen_width = 80
text_width = len(sentence)
box_width = text_width + 6
left_margin = (screen_width - box_width) // 2
print()
print(' ' * left_margin + '+' + '-' * (box_width-2) + '+')
print(' ' * left_margin + '| ' + ' ' * text_width + ' |')
print(' ' * left_margin + '| ' + sentence + ' |')
print(' ' * left_margin + '| ' + ' ' * text_width + ' |')
print(' ' * left_margin + '+' + '-' * (box_width-2) + '+')
print()
2.5、成员资格
要检查特定的值是否包含在序列中,可使用运算符in。这个运算符与前面讨论的运算符(如乘法或加法运算符)稍有不同。它检查是否满足指定的条件,并返回相应的值:满足时返回True,不满足时返回False。这样的运算符称为布尔运算符,而前述真值称为布尔值。
下面是一些in运算符的使用示例:
>>> permissions = 'rw'
>>> 'w' in permissions
True
>>> 'x' in permissions
False
>>> users = ['mlh', 'foo', 'bar']
>>> input('Enter your user name: ') in users
Enter your user name: mlh
True
>>> subject = '$$$ Get rich now!!! $$$'
>>> '$$$' in subject
True
开头两个示例使用成员资格测试分别检查’w’和’x’是否包含在字符串变量permissions中。在UNIX系统中,可在脚本中使用这两行代码来检查对文件的写入和执行权限。接下来的示例检查提供的用户名mlh是否包含在用户列表中,这在程序需要执行特定的安全策略时很有用(在这种情况下,可能还需检查密码)。最后一个示例检查字符串变量subject是否包含字符串’$$$’,这可用于垃圾邮件过滤器中。
相比于其他示例,检查字符串是否包含’$$$'的示例稍有不同。一般而言,运算符in检查指定的对象是否是序列(或其他集合)的成员(即其中的一个元素),但对字符串来说,只有它包含的字符才是其成员或元素,因此下面的代码完全合理:
>>> 'P' in 'Python'
True
事实上,在较早的Python版本中,只能对字符串执行这种成员资格检查——确定指定的字符是否包含在字符串中,但现在可使用运算符in来检查指定的字符串是否为另一个字符串的子串。
# 检查用户名和PIN码
database = [
['albert', '1234'],
['dilbert', '4242'],
['smith', '7524'],
['jones', '9843']
]
username = input('User name: ')
pin = input('PIN code: ')
if [username, pin] in database: print('Access granted')

3、列表:Python的主力
3.1、函数list
鉴于不能像修改列表那样修改字符串,因此在有些情况下使用字符串来创建列表很有帮助。
为此,可使用函数list。
>>> list('Hello')
['H', 'e', 'l', 'l', 'o']
请注意,可将任何序列(而不仅仅是字符串)作为list的参数。
提示 要将字符列表(如前述代码中的字符列表)转换为字符串,可使用下面的表达式:
''.join(somelist)
3.2、基本的列表操作
可对列表执行所有的标准序列操作,如索引、切片、拼接和相乘,但列表的有趣之处在于它是可以修改的。本节将介绍一些修改列表的方式:给元素赋值、删除元素、给切片赋值以及使用列表的方法。(请注意,并非所有列表方法都会修改列表。)
3.2.1、修改列表:给元素赋值
修改列表很容易,只需使用第1章介绍的普通赋值语句即可,但不是使用类似于x = 2这样的赋值语句,而是使用索引表示法给特定位置的元素赋值,如x[1] = 2。
>>> x = [1, 1, 1]
>>> x[1] = 2
>>> x
[1, 2, 1]
——————————
① 它实际上是一个类,而不是函数,但眼下,这种差别并不重要。
注意 不能给不存在的元素赋值,因此如果列表的长度为2,就不能给索引为100的元素赋值。
要这样做,列表的长度至少为101。请参阅本章前面的“None、空列表和初始化”一节。
3.2.2、删除元素
从列表中删除元素也很容易,只需使用del语句即可。
>>> names = ['Alice', 'Beth', 'Cecil', 'Dee-Dee', 'Earl']
>>> del names[2]
>>> names
['Alice', 'Beth', 'Dee-Dee', 'Earl']
注意到Cecil彻底消失了,而列表的长度也从5变成了4。除用于删除列表元素外,del语句还可用于删除其他东西。
3.2.3、给切片赋值
切片是一项极其强大的功能,而能够给切片赋值让这项功能显得更加强大。
>>> name = list('Perl')
>>> name
['P', 'e', 'r', 'l']
>>> name[2:] = list('ar')
>>> name
['P', 'e', 'a', 'r']
从上述代码可知,可同时给多个元素赋值。你可能认为,这有什么大不了的,分别给每个元素赋值不是一样的吗?确实如此,但通过使用切片赋值,可将切片替换为长度与其不同的序列。
>>> name = list('Perl')
>>> name[1:] = list('ython')
>>> name
['P', 'y', 't', 'h', 'o', 'n']
使用切片赋值还可在不替换原有元素的情况下插入新元素。
>>> numbers = [1, 5]
>>> numbers[1:1] = [2, 3, 4]
>>> numbers
[1, 2, 3, 4, 5]
在这里,我“替换”了一个空切片,相当于插入了一个序列。你可采取相反的措施来删除切片。
>>> numbers
[1, 2, 3, 4, 5]
>>> numbers[1:4] = []
>>> numbers
[1, 5]
你可能猜到了,上述代码与del numbers[1:4]等效。现在,你可自己尝试执行步长不为1(乃至为负)的切片赋值了。
3.3、列表方法
方法是与对象(列表、数、字符串等)联系紧密的函数。通常,像下面这样调用方法:
object.method(arguments)
方法调用与函数调用很像,只是在方法名前加上了对象和句点(第7章将详细阐述方法到底是什么)。列表包含多个可用来查看或修改其内容的方法。
3.3.1、append
方法append用于将一个对象附加到列表末尾。
>>> lst = [1, 2, 3]
>>> lst.append(4)
>>> lst
[1, 2, 3, 4]
你可能心存疑虑,为何给列表取lst这样糟糕的名字,而不称之为list呢?我原本是可以这样做的,但你可能还记得,list是一个内置函数①,如果我将前述列表命名为list,就无法调用这个函数。在特定的应用程序中,通常可给列表选择更好的名称。诸如lst等名称确实不能提供任何信息。因此,如果列表为价格列表,可能应该将其命名为prices、prices_of_eggs或pricesOfEggs。另外请注意,与其他几个类似的方法一样,append也就地修改列表。这意味着它不会返回修改后的新列表,而是直接修改旧列表。这通常正是你想要的,但有时会带来麻烦。我将在本章后面介绍sort时再回过头来讨论这一点。
3.3.2、clear
方法clear就地清空列表的内容。
>>> lst = [1, 2, 3]
>>> lst.clear()
>>> lst
[]
这类似于切片赋值语句lst[:] = []。
3.3.3、copy
方法 copy 复制列表。前面说过,常规复制只是将另一个名称关联到列表。
>>> a = [1, 2, 3]
>>> b = a
>>> b[1] = 4
>>> a
[1, 4, 3]
要让a和b指向不同的列表,就必须将b关联到a的副本。
——————————
① 实际上,从Python 2.2起,list就是类型,而不是函数了(tuple和str亦如此)。
>>> a = [1, 2, 3]
>>> b = a.copy()
>>> b[1] = 4
>>> a
[1, 2, 3]
这类似于使用a[:]或list(a),它们也都复制a。
3.3.4、count
方法count计算指定的元素在列表中出现了多少次。
>>> ['to', 'be', 'or', 'not', 'to', 'be'].count('to')
2
>>> x = [[1, 2], 1, 1, [2, 1, [1, 2]]]
>>> x.count(1)
2
>>> x.count([1, 2])
1
3.3.5、extend
方法extend让你能够同时将多个值附加到列表末尾,为此可将这些值组成的序列作为参数提供给方法extend。换而言之,你可使用一个列表来扩展另一个列表。
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a.extend(b)
>>> a
[1, 2, 3, 4, 5, 6]
这可能看起来类似于拼接,但存在一个重要差别,那就是将修改被扩展的序列(这里是a)。
在常规拼接中,情况是返回一个全新的序列。
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a + b
[1, 2, 3, 4, 5, 6]
>>> a
[1, 2, 3]
如你所见,拼接出来的列表与前一个示例扩展得到的列表完全相同,但在这里a并没有被修改。鉴于常规拼接必须使用a和b的副本创建一个新列表,因此如果你要获得类似于下面的效果,拼接的效率将比extend低:
>>> a = a + b
另外,拼接操作并非就地执行的,即它不会修改原来的列表。要获得与extend相同的效果,
可将列表赋给切片,如下所示:
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a[len(a):] = b
>>> a
[1, 2, 3, 4, 5, 6]
这虽然可行,但可读性不是很高。
3.3.6、index
方法index在列表中查找指定值第一次出现的索引。
>>> knights = ['We', 'are', 'the', 'knights', 'who', 'say', 'ni']
>>> knights.index('who')
4
>>> knights.index('herring')
Traceback (innermost last):
File "" , line 1, in ?
knights.index('herring')
ValueError: list.index(x): x not in list
搜索单词’who’时,发现它位于索引4处。
>>> knights[4]
'who'
然而,搜索’herring’时引发了异常,因为根本就没有找到这个单词。
3.3.7、insert
方法insert用于将一个对象插入列表。
>>> numbers = [1, 2, 3, 5, 6, 7]
>>> numbers.insert(3, 'four')
>>> numbers
[1, 2, 3, 'four', 5, 6, 7]
与extend一样,也可使用切片赋值来获得与insert一样的效果。
>>> numbers = [1, 2, 3, 5, 6, 7]
>>> numbers[3:3] = ['four']
>>> numbers
[1, 2, 3, 'four', 5, 6, 7]
这虽巧妙,但可读性根本无法与使用insert媲美。
3.3.8、pop
方法pop从列表中删除一个元素(末尾为最后一个元素),并返回这一元素。
>>> x = [1, 2, 3]
>>> x.pop()
3
>>> x
[1, 2]
>>> x.pop(0)
1
>>> x
[2]
注意 pop是唯一既修改列表又返回一个非None值的列表方法。
使用pop可实现一种常见的数据结构——栈(stack)。栈就像一叠盘子,你可在上面添加盘子,还可从上面取走盘子。最后加入的盘子最先取走,这被为后进先出(LIFO)。
push和pop是大家普遍接受的两种栈操作(加入和取走)的名称。Python没有提供push,但可使用append来替代。方法pop和append的效果相反,因此将刚弹出的值压入(或附加)后,得到的栈将与原来相同。
>>> x = [1, 2, 3]
>>> x.append(x.pop())
>>> x
[1, 2, 3]
提示 要创建先进先出(FIFO)的队列,可使用insert(0, …)代替append。另外,也可继续使用append,但用pop(0)替代pop()。一种更佳的解决方案是,使用模块collections中的deque。
3.3.9、remove
方法remove用于删除第一个为指定值的元素。
>>> x = ['to', 'be', 'or', 'not', 'to', 'be']
>>> x.remove('be')
>>> x
['to', 'or', 'not', 'to', 'be']
>>> x.remove('bee')
Traceback (innermost last):
File "" , line 1, in ?
x.remove('bee')
ValueError: list.remove(x): x not in list
如你所见,这只删除了为指定值的第一个元素,无法删除列表中其他为指定值的元素(这里是字符串’bee’)。
请注意,remove是就地修改且不返回值的方法之一。不同于pop的是,它修改列表,但不返回任何值。
3.3.10、reverse
方法reverse按相反的顺序排列列表中的元素(我想你对此应该不会感到惊讶)。
>>> x = [1, 2, 3]
>>> x.reverse()
>>> x
[3, 2, 1]
注意到reverse修改列表,但不返回任何值(与remove和sort等方法一样)。
提示 如果要按相反的顺序迭代序列,可使用函数reversed。这个函数不返回列表,而是返回一个迭代器(迭代器将在第9章详细介绍)。你可使用list将返回的对象转换为列表。
>>> x = [1, 2, 3]
>>> list(reversed(x))
[3, 2, 1]
3.3.11、sort
方法sort用于对列表就地排序①。就地排序意味着对原来的列表进行修改,使其元素按顺序排列,而不是返回排序后的列表的副本。
>>> x = [4, 6, 2, 1, 7, 9]
>>> x.sort()
>>> x
[1, 2, 4, 6, 7, 9]
前面介绍了多个修改列表而不返回任何值的方法,在大多数情况下,这种行为都相当自然(例如,对append来说就如此)。需要强调sort的行为也是这样的,因为这种行为给很多人都带来了困惑。在需要排序后的列表副本并保留原始列表不变时,通常会遭遇这种困惑。为实现这种目标,一种直观(但错误)的方式是像下面这样做:
>>> x = [4, 6, 2, 1, 7, 9]
>>> y = x.sort() # Don't do this!
>>> print(y)
None
鉴于sort修改x且不返回任何值,最终的结果是x是经过排序的,而y包含None。为实现前述目标,正确的方式之一是先将y关联到x的副本,再对y进行排序,如下所示:
>>> x = [4, 6, 2, 1, 7, 9]
>>> y = x.copy()
>>> y.sort()
>>> x
[4, 6, 2, 1, 7, 9]
>>> y
[1, 2, 4, 6, 7, 9]
只是将x赋给y是不可行的,因为这样x和y将指向同一个列表。为获取排序后的列表的副本,
另一种方式是使用函数sorted。
>>> x = [4, 6, 2, 1, 7, 9]
>>> y = sorted(x)
>>> x
[4, 6, 2, 1, 7, 9]
>>> y
[1, 2, 4, 6, 7, 9]
实际上,这个函数可用于任何序列,但总是返回一个列表②。
>>> sorted('Python')
['P', 'h', 'n', 'o', 't', 'y']
如果要将元素按相反的顺序排列,可先使用sort(或sorted),再调用方法reverse,也可使
用参数reverse,这将在下一小节介绍。
——————————
① 多说一句,从Python 2.3起,方法sort使用的是稳定的排序算法。
② 实际上,函数sorted可用于任何可迭代的对象。可迭代的对象将在第9章详细介绍。
3.3.12、高级排序
方法sort接受两个可选参数:key和reverse。这两个参数通常是按名称指定的,称为关键字参数,将在第6章详细讨论。参数key类似于参数cmp:你将其设置为一个用于排序的函数。然而,不会直接使用这个函数来判断一个元素是否比另一个元素小,而是使用它来为每个元素创建一个键,再根据这些键对元素进行排序。因此,要根据长度对元素进行排序,可将参数key设置为函数len。
>>> x = ['aardvark', 'abalone', 'acme', 'add', 'aerate']
>>> x.sort(key=len)
>>> x
['add', 'acme', 'aerate', 'abalone', 'aardvark']
对于另一个关键字参数reverse,只需将其指定为一个真值,以指出是否要按相反的顺序对列表进行排序。
>>> x = [4, 6, 2, 1, 7, 9]
>>> x.sort(reverse=True)
>>> x
[9, 7, 6, 4, 2, 1]
函数sorted也接受参数key和reverse。在很多情况下,将参数key设置为一个自定义函数很有用。第6章将介绍如何创建自定义函数。提示 如果你想更深入地了解排序,可以参阅文章“Sorting Mini-HOW TO”:https://wiki.python.org/moin/HowTo/Sorting
4、元组:不可修改的序列
与列表一样,元组也是序列,唯一的差别在于元组是不能修改的(你可能注意到了,字符串也不能修改)。元组语法很简单,只要将一些值用逗号分隔,就能自动创建一个元组。
>>> 1, 2, 3
(1, 2, 3)
如你所见,元组还可用圆括号括起(这也是通常采用的做法)。
>>> (1, 2, 3)
(1, 2, 3)
空元组用两个不包含任何内容的圆括号表示。
>>> ()
()
你可能会问,如何表示只包含一个值的元组呢?这有点特殊:虽然只有一个值,也必须在它后面加上逗号。
>>> 42
42
>>> 42,
(42,)
>>> (42,)
(42,)
最后两个示例创建的元组长度为1,而第一个示例根本没有创建元组。逗号至关重要,仅将值用圆括号括起不管用:(42)与42完全等效。但仅仅加上一个逗号,就能完全改变表达式的值。
>>> 3 * (40 + 2)
126
>>> 3 * (40 + 2,)
(42, 42, 42)
函数tuple的工作原理与list很像:它将一个序列作为参数,并将其转换为元组①。如果参数已经是元组,就原封不动地返回它。
>>> tuple([1, 2, 3])
(1, 2, 3)
>>> tuple('abc')
('a', 'b', 'c')
>>> tuple((1, 2, 3))
(1, 2, 3)
你可能意识到了,元组并不太复杂,而且除创建和访问其元素外,可对元组执行的操作不多。
元组的创建及其元素的访问方式与其他序列相同。
>>> x = 1, 2, 3
>>> x[1]
2
>>> x[0:2]
(1, 2)
元组的切片也是元组,就像列表的切片也是列表一样。为何要熟悉元组呢?原因有以下两个。
- 它们用作映射中的键(以及集合的成员),而列表不行。映射将在第4章详细介绍。
- 有些内置函数和方法返回元组,这意味着必须跟它们打交道。只要不尝试修改元组,与元组“打交道”通常意味着像处理列表一样处理它们(需要使用元组没有的index和count等方法时例外)。
一般而言,使用列表足以满足对序列的需求。
5、小结
下面来回顾一下本章介绍的一些最重要的概念。
- 序列:序列是一种数据结构,其中的元素带编号(编号从0开始)。列表、字符串和元组都属于序列,其中列表是可变的(你可修改其内容),而元组和字符串是不可变的(一旦创建,内容就是固定的)。要访问序列的一部分,可使用切片操作:提供两个指定切片起始和结束位置的索引。要修改列表,可给其元素赋值,也可使用赋值语句给切片赋值。
① 与list一样,tuple实际上也不是函数,而是类型。而且同样,目前你完全可以不考虑这一点。 - 成员资格:要确定特定的值是否包含在序列(或其他容器)中,可使用运算符in。将运算符in用于字符串时情况比较特殊——这样可查找子串。
- 方法:一些内置类型(如列表和字符串,但不包括元组)提供了很多有用的方法。方法有点像函数,只是与特定的值相关联。方法是面向对象编程的一个重要方面。
| 函 数 | 描 述 |
|---|---|
| len(seq) | 返回序列的长度 |
| list(seq) | 将序列转换为列表 |
| max(args) | 返回序列或一组参数中的最大值 |
| min(args) | 返回序列和一组参数中的最小值 |
| reversed(seq) | 让你能够反向迭代序列 |
| sorted(seq) | 返回一个有序列表,其中包含指定序列中的所有元素 |
| tuple(seq) | 将序列转换为元组 |