使用Movidius神经棒过程的问题记录和探索
索引
- 一、安装NCSDK
- 二、NCSDK的几个指令
- 1、mvNCCompile
- 2、mvNCProfile
- 3、mvNCCheck
- 三、输入输出Node名字
- 四、跑自己的caffe模型(有bug)
- 五、跑TensorFlow模型(以VGG16为例,调试成功)
- 保存ckpt的tf模型
- 把ckpt转化为pb的图
- 转化为Movidius可用图
- 2次不成功的总结
一、安装NCSDK
地址:https://github.com/movidius/ncsdk
安装步骤就跟着官方来,很简单
在make examples时,我出现了2代棒USB无法识别的问题:[Error 7] Toolkit Error: USB Failure. Code: Error opening devic
原因:英特尔说2代不支持NCSDK,大家得去用它新出的OpenVINO的SDK(REFRENCE)
二、NCSDK的几个指令
其实在/ncsdk/examples/中的makefile都有说明,在此总结
在编译自己的模型时,我们重点关注一下两个指令(其实也是一个)
1、mvNCCompile
这个是编译自己的模型并生成能够被神经棒识别的graph的重要指令
使用方法:
mvNCCompile model/path -in=input_node_name -on=output_node_name
重要的就是这三个参数,具体可以mvNCCompile -h查看,但是有些限制
(0)本身这个神经棒能做的运算就有局限,例如MobileNet就没办法跑因为有不支持的层
会抛错[Error 5] Toolkit Error: Stage Details Not Supported: IsVariableInitialized

(1)必须是单个输入和单个输出(可能3个也可以,还没试验,后期补充)
(2)必须是整个模型完整的输入输出,不能是中间层
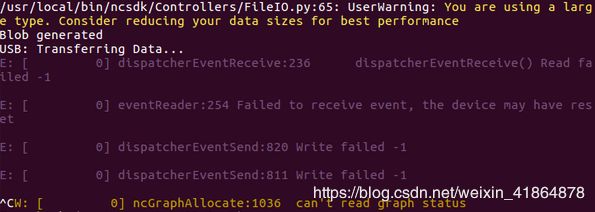
(3)模型大小有限制,我测试VGG16模型>500M抛出
/usr/local/bin/ncsdk/Controllers/FileIO.py:65: UserWarning: You are using a large type. Consider reducing your data sizes for best performance
并且影响后续的mvNCProfile抛错
2、mvNCProfile
是在complie的基础上生成评估的结果,和Compile用法相同
3、mvNCCheck
对比在CPU/GPU和神经棒上测试的结果对比,包括时长、accuracy等
三、输入输出Node名字
我是基于keras(tf后端)做的,一开始不知道命名方式,总是不能正确的给on赋值
目前我的解决方式是在保存模型的时候加一行
conf = sess.graph.get_operations()
print(conf)
然后把结果打印出来,然后再找输出节点的名字
但我总结规律,大概率是
output-layer-name/Operation-name
例如predictions/Softmax,reshape_2/Reshape
欢迎各位指正啊!
在编辑后又读了一篇博客有点新启发:节点名称,应包含name_scope 和 variable_scope命名空间,并用“/”隔开,如"InceptionV3/Logits/SpatialSqueeze"
四、跑自己的caffe模型(有bug)
硬件:Movidius一代棒
SDK:NCSDK
直接用prototxt文件进行profile编译
$ mvNCProfile layer3_deploy.prototxt -s 12
抛错[Error 25] Myriad Error: “Status.ERROR”.

这个问题的原因我还没找到,欢迎大家一起讨论探究
五、跑TensorFlow模型(以VGG16为例,调试成功)
硬件:Movidius二代棒
SDK:OpenVINO
保存ckpt的tf模型
import tensorflow as tf
from keras import backend as K
from keras.applications import VGG16
mn = VGG16()
config = mn.get_config() #用于打印模型结构,作为output_node_name输入,可以注释掉
print(config)
saver = tf.train.Saver()
sess = K.get_session()
saver.save(sess,"./output/VGG16") #这里设置成自己的输出路径和输出名
我这里直接调用了keras自带的VGG16的模型,没有修改
输出文件有四个

打印出的节点名称
这个不重要,但是我是每次从这个里面自己找到输出节点的名字……(这个方法很麻烦,如果有更好的规律可以总结还请告诉我一声一起讨论鸭)
比如这里的最后一层的configuration是{'class_name': 'Dense', 'name': 'predictions', 'inbound_nodes': [[['fc2', 0, 0, {}]]], 'config': {'kernel_regularizer': None, 'kernel_constraint': None, 'bias_initializer': {'class_name': 'Zeros', 'config': {}}, 'bias_regularizer': None, 'kernel_initializer': {'class_name': 'VarianceScaling', 'config': {'scale': 1.0, 'seed': None, 'distribution': 'uniform', 'mode': 'fan_avg'}}, 'units': 1000, 'name': 'predictions', 'trainable': True, 'activity_regularizer': None, 'bias_constraint': None, 'activation': 'softmax', 'use_bias': True}}], 'name': 'vgg16', 'output_layers': [['predictions', 0, 0]]}
所以输出节点为predictions/Softmax
把ckpt转化为pb的图
def freeze_graph(input_checkpoint,output_graph, output_node_names):
'''
:param input_checkpoint:
:param output_graph:
:return:
'''
# checkpoint = tf.train.get_checkpoint_state(model_folder)
# input_checkpoint = checkpoint.model_checkpoint_path
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=True)
with tf.Session() as sess:
saver.restore(sess, input_checkpoint)
output_graph_def = graph_util.convert_variables_to_constants(
sess=sess,
input_graph_def=sess.graph_def,# :sess.graph_def
output_node_names=output_node_names.split(","))#
with tf.gfile.GFile(output_graph, "wb") as f:
f.write(output_graph_def.SerializeToString())
print("%d ops in the final graph." % len(output_graph_def.node))
参考这个博客,我自己做了修改,资源放在https://download.csdn.net/download/weixin_41864878/10847990
调用方法
python freeze_graph.py -c ./output/VGG16 -o ./output/VGG16_freeze.pb -n predictions/Softmax
#首先键入.meta文件的保存路径,注意不要.meta的后缀
#第二键入输出路径和文件名
#第三键入输出节点名称
#可用python freeze_graph.py -h查看
这样调用起来比较灵活
转化为Movidius可用图
最后一步是最简单的一步,官网有详细说明,不过也是最容易有bug的一步
python /path/to/deployment_tools/model_optimizer/mo_tf.py --input_model ./output/VGG16_freeze.pb
#这里就是调用SDK给出的转换代码,输入自己的.pb图
但是呢,很不幸的是我报错了
[ ERROR ] Shape [ -1 224 224 3] is not fully defined for output 0 of “input_1”. Use --input_shape with positive integers to override model input shapes.
[ ERROR ] Cannot infer shapes or values for node “input_1”.
[ ERROR ] Not all output shapes were inferred or fully defined for node “input_1”.
For more information please refer to Model Optimizer FAQ (/deployment_tools/documentation/docs/MO_FAQ.html), question #40.
[ ERROR ]
[ ERROR ] It can happen due to bug in custom shape infer function.
[ ERROR ] Or because the node inputs have incorrect values/shapes.
[ ERROR ] Or because input shapes are incorrect (embedded to the model or passed via --input_shape).
[ ERROR ] Run Model Optimizer with --log_level=DEBUG for more information.
[ ERROR ] Stopped shape/value propagation at “input_1” node.
For more information please refer to Model Optimizer FAQ (/deployment_tools/documentation/docs/MO_FAQ.html), question #38.
emmmm,还好它给出了解决方法,于是换成
python /opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py --input_model ./output/VGG16_freeze.pb --input_shape [1,224,224,3]
成功啦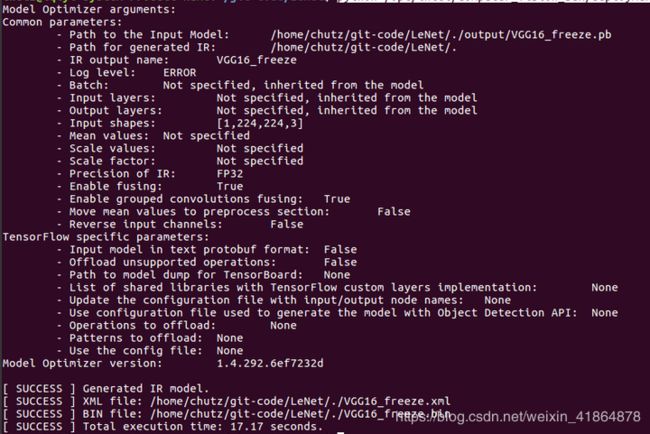
2次不成功的总结
(1)官网其实也给出了使用checkpoint来进行转化的说明,可是我用会爆这个错
[ WARNING ] The value for the --input_model command line parameter
ends with “.ckpt” or “.meta” extension. It means that the model is not
frozen. To load non frozen model to Model Optimizer run:
- For “*.ckpt” file:
- if inference graph is in binary format python3 mo_tf.py --input_model “path/to/inference_graph.pb” --input_checkpoint “path/to/*.ckpt”
- if inference graph is in text format python3 mo_tf.py --input_model “path/to/inference_graph.pbtxt” --input_model_is_text
–input_checkpoint “path/to/*.ckpt”
- For “.meta" file: python3 mo_tf.py --input_meta_graph "path/to/.meta”
[libprotobuf ERROR
google/protobuf/wire_format_lite.cc:629] String field
‘tensorflow.NodeDef.op’ contains invalid UTF-8 data when parsing a
protocol buffer. Use the ‘bytes’ type if you intend to send raw bytes.
[ FRAMEWORK ERROR ] Cannot load input model: TensorFlow cannot read
the model file: “/home/chutz/git-code/LeNet/./output/MobileNet.meta”
is incorrect TensorFlow model file. The file should contain one of
the following TensorFlow graphs:
1. frozen graph in text or binary format
2. inference graph for freezing with checkpoint (–input_checkpoint) in text or binary format
3. meta graphMake sure that --input_model_is_text is provided for a model in text
format. By default, a model is interpreted in binary format. Framework
error details: Error parsing message. For more information please
refer to Model Optimizer FAQ
(/deployment_tools/documentation/docs/MO_FAQ.html),
question #43.
所以就放弃了用checkpoint
(2)用keras提供的MobileNet()失败
错误显示是因为Movidius目前不支持某些操作,但是intel官网是有mobilenet的模型提供的,所以按道理来说,运行这个网络是没问题的,所以后续我会看一下这两个模型的区别再来研究一下
[ ERROR ] List of operations that cannot be converted to IE IR:
[ ERROR ] Exp (1)
[ ERROR ] act_softmax/Exp
[ ERROR ] Max (1)
[ ERROR ] act_softmax/Max
[ ERROR ] Sum (1)
[ ERROR ] act_softmax/Sum
[ ERROR ] Part of the nodes was not translated to IE. Stopped.
For more information please refer to Model Optimizer FAQ (/deployment_tools/documentation/docs/MO_FAQ.html), question #24.
官网模型运行结果成功

不过这个转换之后所给出的信息我还没有仔细研究,之后会持续更新~~也希望有一起做这个的小伙伴能给出你们的问题或者意见,共同进步鸭
参考文献
https://blog.csdn.net/weixin_42259631/article/details/82414152
https://blog.csdn.net/bobpeter84/article/details/82685310