深度学习笔记(1)——神经网络详解及改进
神经网络
- 前言
- 正文
- step1 建立一个神经网络模型
- 一个常见的神经网络——完全连接前馈神经网络
- 本质
- 举例:手写识别
- step2 模型评估
- step3 最佳模型——梯度下降
- 反向传播($BP$)
- 我们取出一个神经元进行分析
- Forward Pass $\frac{\partial z}{\partial w}$:
- Backward Pass $\frac{\partial l}{\partial z}$:
- 利用keras建立神经网络
- 深度学习的技巧
- 在test上如何改进:
- 新的激活函数
- sigmoid缺点——梯度消失:
- ReLU:
- Maxout —— 让network自动学习的激活函数
- 更新学习速率
- RMSProp
- Momentum
- Adam
- 在train上改进(过拟合)
- Early Stopping
- Regularization
- Dropout
- 如何训练
- 解释
- 在testing上注意两件事情:
- 总结
前言
笔者一直在ipad上做手写笔记,最近突然想把笔记搬到博客上来,也就有了下面这些。因为本是给自己看的笔记,所以内容很简陋,只是提了一些要点。随缘更新。
正文
step1 建立一个神经网络模型
一个常见的神经网络——完全连接前馈神经网络
- 全连接:layer和layer之间两两连接
- 前馈传递方向由后向前,任意两层之间没有反馈
- 深度:许多隐含层

σ ( [ 1 − 2 − 1 1 ] [ 1 − 1 ] + [ 1 0 ] ) = [ 0.98 0.12 ] \sigma(\begin{bmatrix}1&-2 \\-1&1\end{bmatrix}\begin{bmatrix}1 \\-1\end{bmatrix}+\begin{bmatrix}1 \\0\end{bmatrix})=\begin{bmatrix}0.98 \\0.12\end{bmatrix} σ([1−1−21][1−1]+[10])=[0.980.12] 如此一层一层传递下去。
最普通的激活函数 σ ( z ) \sigma(z) σ(z)为sigmoid函数
f ( z ) = 1 1 + e − z f(z)=\frac{1}{1+e^{-z}} f(z)=1+e−z1
其图像为:
 当然,现在已经很少使用sigmoid函数做激活函数了。
当然,现在已经很少使用sigmoid函数做激活函数了。
本质
通过隐含层来代替原来的特征工程,这样最后一个隐含层输出的就是一组新的特征,然后通过一个多分类器(可以是 s o l f m a x solfmax solfmax函数)得到最后的输出 y y y。因为并不是每种数据都是结构化的,例如图片、语音这种,这类数据是非结构的,人们很难通过各种特征对其进行有效的特征处理,所以传统的机器学习在这种领域将不再适用。于是人们想出了这种通过一层层的隐含层对其进行强制拟合的模型,称之为神经网络。
举例:手写识别
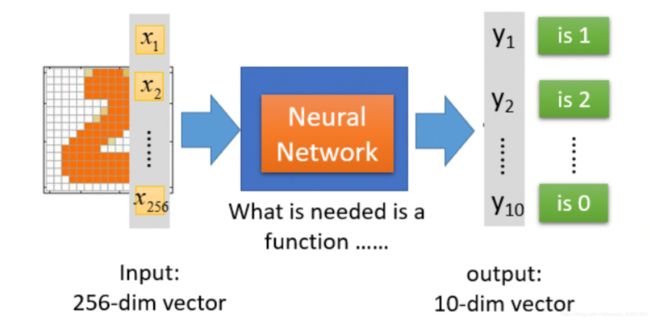
step2 模型评估
对于神经网络,我们采用交叉熵来对 y y y 和 y ^ \hat y y^ 的损失进行计算。(后期我将在生成模型和判别模型中对他进行详细的描述)
step3 最佳模型——梯度下降

b a c k p r o p a t i o n backpropation backpropation(反向传播,也就是所谓的 B P BP BP)在神经网络中是一种有效的方式计算 ∂ L ∂ w \frac{\partial{L}}{\partial w} ∂w∂L的方式,我们可以利用很多框架进行计算,如:TensorFlow,Pytorch。
反向传播( B P BP BP)
L ( θ ) L(\theta) L(θ)是总体损失函数, l n ( θ ) l^n(\theta) ln(θ)是单个样本产生的误差。
计算 L ( θ ) = ∑ n = 0 N l n ( θ ) L(\theta)= \sum_{n=0}^{N}l^n(\theta) L(θ)=∑n=0Nln(θ),只需要计算 ∂ L ( θ ) ∂ w = ∑ n = 1 N ∂ L ( θ ) ∂ w \frac{\partial L(\theta)}{\partial w}=\sum_{n=1}^{N}\frac{\partial L(\theta)}{\partial w} ∂w∂L(θ)=∑n=1N∂w∂L(θ)。
我们取出一个神经元进行分析
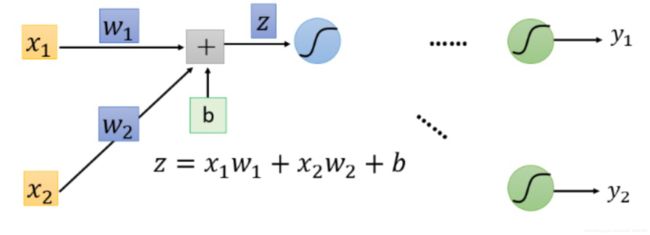
易得:
∂ l ∂ w = ∂ z ∂ w ∂ l ∂ z \frac{\partial l}{\partial w}=\frac{\partial z}{\partial w}\frac{\partial l}{\partial z} ∂w∂l=∂w∂z∂z∂l
Forward Pass ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z:
这里我可以很轻松看出 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z为上一隐含层输出的值。

Backward Pass ∂ l ∂ z \frac{\partial l}{\partial z} ∂z∂l:

∂ l ∂ z = ∂ a ∂ z ∂ l ∂ a = ∂ a ∂ z [ ∂ z ′ ∂ a ∂ l ∂ z + ∂ z ′ ′ ∂ a ∂ l ∂ z ′ ′ ] = σ ′ ( z ) [ w 3 ∂ l ∂ z ′ + w 4 ∂ l ∂ z ′ ′ ] \frac{\partial l}{\partial z}=\frac{\partial a}{\partial z}\frac{\partial l}{\partial a} = \frac{\partial a}{\partial z}[\frac{\partial z'}{\partial a}\frac{\partial l}{\partial z}+\frac{\partial z''}{\partial a}\frac{\partial l}{\partial z''}] = \sigma'(z)[w_3 \frac{\partial l}{\partial z'} + w_4 \frac{\partial l}{\partial z''}] ∂z∂l=∂z∂a∂a∂l=∂z∂a[∂a∂z′∂z∂l+∂a∂z′′∂z′′∂l]=σ′(z)[w3∂z′∂l+w4∂z′′∂l]
这时候我们会觉得每计算一次梯度相当麻烦,每个参数的梯度都需要层层往后计算,计算量大到无法想象。实际上进行Backward Pass和向前传播的计算量差不多,我们只需将我们的思维逆转一下,从最后一层往前计算,也能计算出所有参数的梯度,这时的计算量是线性的,这就是 B P BP BP 的思想(个人为很类似于算法中的动态规划)。

利用keras建立神经网络
建立神经网络的过程,别人以为你在搞什么特别深奥高大上的东西,其实你只是在搭积木一样一层一层叠隐含层而已=。=
import keras
from keras.models import Sequential
from keras.layers import Dense
model = Sequential() # 建立一个模型
# 搭建网络
'''@param
Dense: Fully connect layer
input_dim: 输入层
units: 神经元
activation: 激活函数
'''
model.add(Dense(input_dim=10, units=500, activation='sigmoid')) # 建立一个神经网络
# 再加一个隐含层
model.add(Dense(units=500, activation='sigmoid'))
# 输出层
model.add(Dense(units=10, activation='softmax')) # 输出向量长度为10,激活函数为softmax
# loss function
model.compile(loss='categotial_crossentropy', # 损失函数:交叉熵
optimizer='adam', # 优化器(都是梯度下降)
metrics=['accuracy'] # 指标
)
# batch_size: 将训练集随机分为分为几个batch,每次计算随机的一个
# 所有batch都计算一次,一个epoch结束
model.fit(x_train, y_train, batch_size=100, epochs=20)
# case1: 测试集正确率
score = model.evaluate(x_test, y_test)
print('Total loss on Test Set:', score[0])
print('Accuracy of Testing Set:', score[1])
# case 2:模型预测
result = model.predict(x_test)
深度学习的技巧
在test上如何改进:
新的激活函数
sigmoid缺点——梯度消失:
有时神经网络层数越深,结果越差,原因可能是梯度消失,比较靠近input的几层梯度很小,靠近output的几层梯度较大,在前几层还未怎么更新参数时,后几层已经收敛。因为每经过一个sigmoid, Δ w \Delta w Δw的影响就会被消弱。
ReLU:

- 当 input > 0 时,output = input
- 当 input < 0 时,output = 0
在input < 0 时,相当于该节点被移除,整个网络就是 a thinner linear network,如果时线性的话,梯度不会递减。
你可能会说这个线性模型如何处理那些复杂的非线性模型,毕竟不是所有问题都和线性一样美好,你要注意了我们这是deep learning,关键在于这个“deep”,这是一个有着数层几千个神经元的网络,它们叠加的效果就是一个非线性的模型,是一个很复杂的function。对于ReLU activation function的神经网络,只是在小范围内是线性的,在总体上还是非线性的。
好处:
- 比sigmoid处理起来快
- 无穷多的sigmoid叠加起来的结果(不同的bias)
- 可以处理梯度消失
变种:
-
Leaky ReLU

-
Parametric ReLU
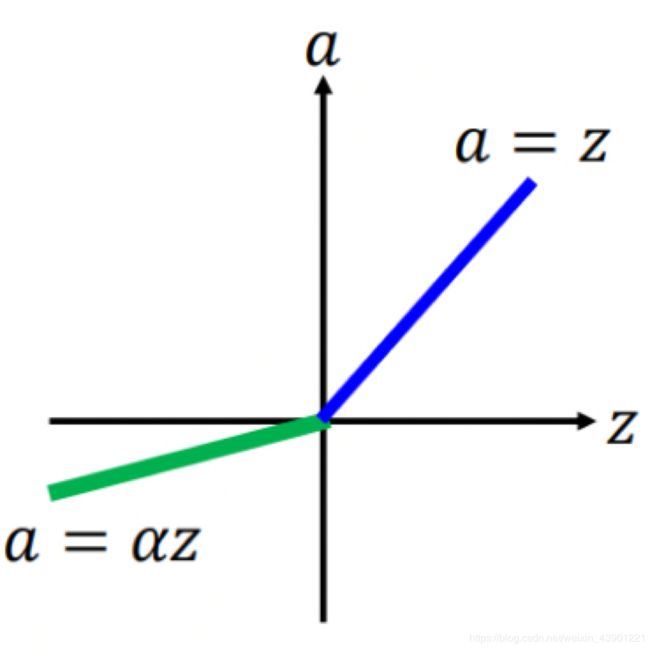
Maxout —— 让network自动学习的激活函数
方法:
- 先将输入分组,如2个一组或3个一组
- 再从每一组中选择最大的一个
下图为一个简单的示例

原理:
其实上面介绍的ReLU为一个特殊的Maxout,理论上Maxout可以拟合任何激活函数
比如下面这个ReLU可以由如此的Maxout得到

选择不同的 w w w和 b b b可以做到

你可能会问这样不就有的节点训练不到了吗?因为有些节点的权值为0等于从网络中去除了。其实只是部分数据上此节点为0,但是我们有大量数据,总有数据可以训练到这个节点。所以 M a x o u t Maxout Maxout 需要比 R e L U ReLU ReLU 更大的数据量才能训练好这个网络。
更新学习速率
RMSProp
属于之前在线性模型中提到的 A d a g r a d Adagrad Adagrad算法的变形
w 1 ⟵ w 0 − η σ 0 g 0 σ 0 = g 0 w^1 \longleftarrow w^0 - \frac{\eta}{\sigma^0}g^0 \qquad \sigma^0=g^0 w1⟵w0−σ0ηg0σ0=g0
w 2 ⟵ w 1 − η σ 1 g 1 σ 1 = α ( σ 0 ) 2 + ( 1 − α ) ( g 1 ) 2 w^2 \longleftarrow w^1 - \frac{\eta}{\sigma^1}g^1 \qquad \sigma^1=\sqrt{\alpha(\sigma^0)^2+(1-\alpha)(g^1)^2} w2⟵w1−σ1ηg1σ1=α(σ0)2+(1−α)(g1)2
w 3 ⟵ w 2 − η σ 2 g 2 σ 2 = α ( σ 1 ) 2 + ( 1 − α ) ( g 2 ) 2 w^3 \longleftarrow w^2 - \frac{\eta}{\sigma^2}g^2 \qquad \sigma^2=\sqrt{\alpha(\sigma^1)^2+(1-\alpha)(g^2)^2} w3⟵w2−σ2ηg2σ2=α(σ1)2+(1−α)(g2)2
. . . . . . ...... ......
w t + 1 ⟵ w t − η σ t g t σ t = α ( σ t − 1 ) 2 + ( 1 − α ) ( g t ) 2 w^{t+1} \longleftarrow w^t - \frac{\eta}{\sigma^t}g^t \qquad \sigma^t=\sqrt{\alpha(\sigma^{t-1})^2+(1-\alpha)(g^t)^2} wt+1⟵wt−σtηgtσt=α(σt−1)2+(1−α)(gt)2
一个固定的learning rate除以一个 σ \sigma σ(在第一个时间点, σ \sigma σ就是第一个算出来GD的值),在第二个时间点,你算出来一个 g 1 g^1 g1和 σ 2 \sigma^2 σ2(你可以去手动调一个 α \alpha α值,把 α \alpha α值调整的小一点,说明你倾向于相信新的gradient告诉你的这个error surface的平滑或者陡峭的程度)。
Momentum
参考了物理世界惯性的概念,遇到一个小山坡时可以通过惯性翻过,从而越过局部最优点。

在算法中只参考上一次的速度,因为上一次的速度已经包含了之前所有的速度。
步骤:
- 选择一个初始位置 θ 0 \theta^0 θ0 和初始速度 v 0 = 0 v^0=0 v0=0
- 计算在 θ 0 \theta^0 θ0 处的梯度 Δ L ( θ 0 ) \Delta L(\theta^0) ΔL(θ0)
- v 1 = λ v 0 − η Δ L ( θ 0 ) v^1=\lambda v^0-\eta\Delta L(\theta^0) v1=λv0−ηΔL(θ0)
- θ 0 = θ 1 + v 1 \theta^0= \theta^1+v^1 θ0=θ1+v1
- 如此往复
Adam
R M S P r o p RMSProp RMSProp和 M o m e n t u m Momentum Momentum的结合。有兴趣的朋友直接看图吧。

在train上改进(过拟合)
Early Stopping
我们需要的是测试集错误最小,而不是训练集,如果测试集的Loss上升,则需要立刻停止训练,但是如果将测试集加入训练则会导致测试结果不客观。这时我们可以引入验证集来解决。当训练时验证集Loss上升则停止训练。

Regularization
和线性模型一样,我们需要在原来的 l o s s f u n c t i o n loss function lossfunction加入正则化,让得到的结果更加平滑。
常见的有 L 1 − n o r m L_1-norm L1−norm(一次式)和 L 2 − n o r m L_2-norm L2−norm(二次式)
Dropout
如何训练
在训练时的时候,每一次参数更新之前,对network里面的每个神经元(包括输入层),做采样(sampling)。 每个神经元会有p%的可能性会被丢掉,跟着的 w w w 也会被丢掉。
解释
你在训练时,加上dropout,你会看到在训练集上结果会变得有点差(因为某些神经元不见了),但是dropout真正做的事就是让你测试集越做越好。
假设有 m m m个神经元,就可以训练 2 m 2^m 2m 个神经网络结构,每个网络的偏差虽然很大,但是最后平均下来还是很准的(这个又要回到我们在线性模型中说的 v a r i e n c e varience varience 和 b i a s bias bias 问题)。
dropout其实是用了模型融合(model essemble)的思想,训练了很多模型最后加权得到最终的结果。

在testing上注意两件事情:
- 第一件事情就是在testing上不做dropout。
- 在dropout的时候,假设dropout rate在training是p%,all weights都要乘以 ( 1 − p % ) (1-p\%) (1−p%)
关于为什么要乘 ( 1 − p % ) (1-p\%) (1−p%),举一个简单的例子:
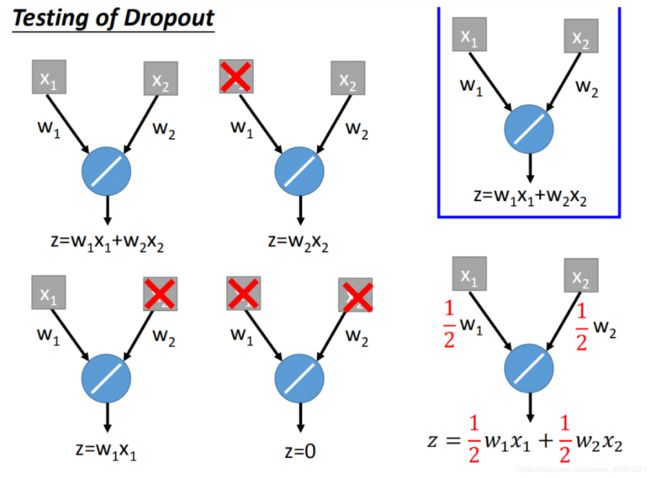
总结
到此神经网络已经介绍得差不多了,你可能会说,就这,就这?其实神经网络也不是什么深奥的东西,本质上就是一个有着数千个参数的模型,和最简单的线性模型一样,也是通过最常规的方法——梯度下降求解。当然,其中也涉及了一些挺玄学(只可意会,不可言传,当然也是我的数学功底不够,无法准确描述)的方法。
上一篇:机器学习笔记(1)——线性回归
下一篇:可能会讲一讲CNN或者神经网络中神经元的来源——logistic回归(未开始写=。=)
(如果觉得有用请点个赞吧)