爬虫入门————一个简单的吃瓜爬虫
小白第一次写爬虫,主要使用了requests,beautifulsoup 和 XPATH库。实现了爬取八卦组首页帖子并将标题,链接和3个亮评存入csv文件中以待以后可能的使用(或者就此荒废.........)
话不多说 先放代码
import requests
import bs4
from bs4 import BeautifulSoup
import os
url = 'https://www.douban.com/group/blabla/?ref=sidebar%E3%80%91'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
titlelist, linklist, timelist = [],[],[]
all_title = soup.find_all('td', class_='title')
for link in all_title:
linklist.append(link.a.attrs['href'])
titlelist.append(link.a.attrs['title'])
time_ = soup.find_all('td', class_='time')
for tim in time_:
# timelist.append(re.findall(r'>.*',tim.string))#笨比,你都string了,当然没有之后的标签了,你还正则个p
timelist.append(tim.string)
# print(timelist)
# type(time_)
path1 = r'C:\Users\Administrator\Desktop\豆瓣鹅组每日讨论'
current_time = timelist[4]
current_time = current_time.replace(':','_')
print(current_time)
join_path = ''
join_path = os.path.join(path1, (str(current_time) + '.txt'))
# info =['标题']
print(join_path)
with open(join_path,'w',encoding='utf-8')as f:
for i in range(len(titlelist)):
f.writelines(titlelist[i]+'\n'+linklist[i]+'\n')
# C:\Users\Administrator\Desktop\豆瓣鹅组每日讨论\03-06 20.txt
# for index, (title, link) in enumerate(zip(titlelist, linklist),1):
# if index>4:
# print('[', index-4, ']')
# print('title: ',title)
# print('link: ', link)
# print('时间:', timelist[index-1])这一块代码主要是用的beautifulsoup库来爬取页面内容,将内容保存在了txt文件中,这是一开始写的,因为能在jupyter notebook里将就用,也就懒得优化成一个个函数了。最后的print被我注释了因为内容已经被保存在列表里在后续会写入文件。大概效果是这样的:
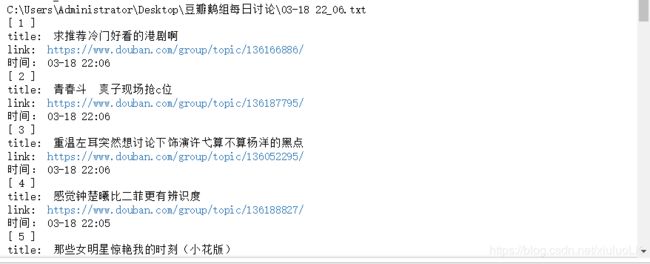
上面的代码块并没有爬取各个帖子中的亮评,主要原因是因为beautifulsoup库用的不熟练,定位标签定位半天还老出错,今天下午看了看xpath感觉xpath简单很多,就使用xpath对评论进行了爬取。
from lxml import etree
import csv
def get_short_comment(link, commentlist):
r = requests.get(link).text
s = etree.HTML(r)
comment = s.xpath('//*[@class="topic-reply popular-bd"]/li[@class="clearfix comment-item"]/div[\
@class="reply-doc content"]/p/text()') # comment是爬出来的评论list
commentlist.append(comment)
for i in range(3):
try:
print('亮屏第',i,': ',comment[i])
except:
print('这是个新帖子')
print('-------------------------------')运行函数后评论都被保存在了commentlist中,不过因为亮评是按每个帖子一个list来的,然后再按序保存到commentlist中,相当于该list是个二维数组(不太好表达,大致就是这个意思)
想写入csv文件的话 将list改为一维的比较方便,具体整合list和存储代码如下:
def save_csv(infolist): # 将info写入csv 理想结果是第一列是编号,第二列是标题,第三列是链接,456各存亮评
join_path = ''
join_path = os.path.join(path1, (str(current_time) + '.csv'))
name =['标题','连接','亮评1','亮评2','亮评3']
test = pd.DataFrame(columns=name, data =infolist)
test.to_csv(join_path,encoding='utf_8_sig')
def agg_info(titlelist, linklist, commentlist): # 将三个list合并为一个总list,好输入到csv文件中
infolist =[]
i = 0
for i in range(len(titlelist)): # int类型不能直接迭代
try:
_ = []
_.append(titlelist[i])
_.append(linklist[i])
_.append(commentlist[i][0])
_.append(commentlist[i][1])
_.append(commentlist[i][2])
except:
continue
infolist.append(_)
return infolist最后运行一下就好啦!
i = 0
commentlist = []
for link in linklist:
print('标题: '+titlelist[i])
print('链接: '+ link)
get_short_comment(link, commentlist)
i+=1
infolist = agg_info(titlelist, linklist, commentlist)
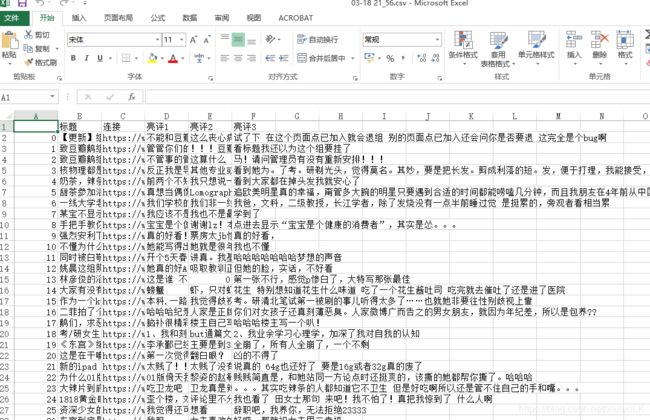
save_csv(infolist)具体结果是这样的:
并可以保存到文件夹中:
到这里就完成了,代码写的不够简洁但是最近又要看论文(懒)
之后提升的话在github上找到了些spider练手项目,回头多学习一下