- 1. 内存管理概述
- 2. 内存大小
- 1.2.1 DTS上报 * memblock
- 1.2.2 ACPI上报
- 1.2.1 DTS上报 * memblock
- 3. 物理内存映射
- 4. zone初始化
- 5. 空间划分
- 6. 物理内存初始化
- 7 小结
- 7.1 内存空间
- 7.2
本节思考:
- 在系统启动时,ARM Linux内核如何知道系统中有多大的内存空间?
- 在32bit Linux内核中,用户空间和内核空间的比例通常是3:1,可以修改成2:2吗?
- 物理内存页面如何添加到伙伴系统中,是一页一页添加,还是以2的几次幂来加入呢?
在内存管理的上下文中, 初始化(initialization)可以有多种含义.在许多CPU上,必须显式设置适用于Linux内核的内存模型.在x86_32上需要切换到保护模式, 然后内核才能检测到可用内存和寄存器.
在初始化过程中, 还必须建立内存管理的数据结构,以及很多事务.因为内核在内存管理完全初始化之前就需要使用内存. 在系统启动过程期间,使用了额外的简化的内存管理模块,然后在初始化完成后,将旧的模块丢弃掉.
对相关数据结构的初始化是从全局启动函数start_kernel中开始的,该函数在加载内核并激活各个子系统之后执行. 由于内存管理是内核一个非常重要的部分,因此在特定体系结构的设置步骤中检测并确定系统中内存的分配情况后, 会立即执行内存管理的初始化.
现在大部分计算机使用DDR(Dual Data Rate SDRAM)的存储设备,DDR包括DDR3L、DDR4L、LPDDR3/4等。DDR初始化一般在BIOS或boot loader中,BIOS或boot loader将DDR大小传给内核,因此从Linux内核角度看其实就是一段物理内存空间。
1. 内存管理概述
分层描述的话,内存空间可以分为3个层次,分别是用户空间层、内核空间层和硬件层。如图2.1。
图2.1 内存管理框图:
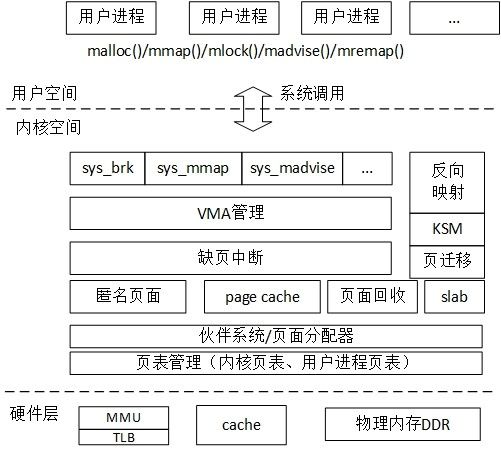
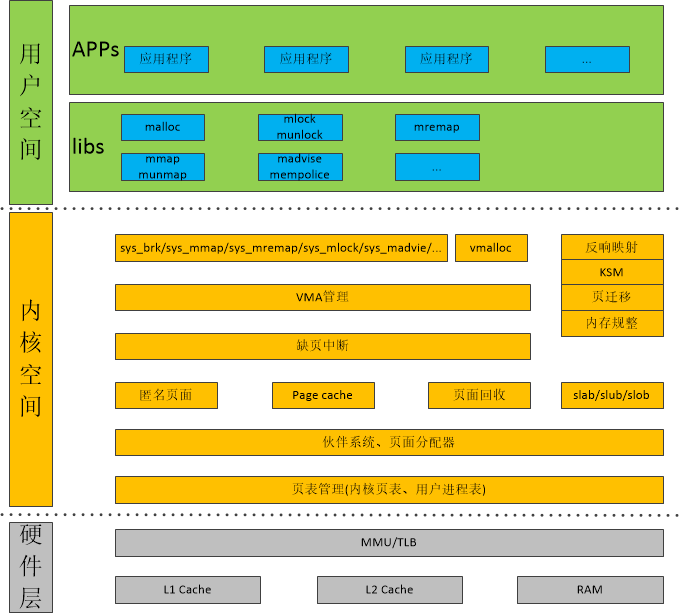
| 层次 | 描述 |
|---|---|
| 用户空间层 | 可以理解为Linux 内核内存管理为用户空间暴露的系统调用接口. 例如brk(), mmap()等系统调用. 通常libc库会将系统调用封装成大家常见的C库函数, 比如malloc(), mmap()等. |
| 内核空间层 | 包含的模块相当丰富, 用户空间和内核空间的接口时系统调用, 因此内核空间层首先需要处理这些内存管理相关的系统调用, 例如sys_brk, sys_mmap, sys_madvise等. 接下来就包括VMA管理, 缺页中断管理, 匿名页面, page cache, 页面回收, 反向映射, slab分配器, 页面管理等模块. |
| 硬件层 | 包含处理器的MMU, TLB和cache部件, 以及板载的物理内存, 例如LPDDR或者DDR |
用户空间和内核空间的接口是系统调用,因此内核空间层首先需要处理这些内存管理相关的系统调用,例如sys_brk、sys_mmap、sys_madvise等。接下来就包括VMA管理、缺页中断管理、匿名页面、page cache、页面回收、反向映射、slab分配器、页表管理等模块了。
最下面是硬件层,包括处理器的MMU、TLB和cache部件,以及板载的物理内存,例如LPDDR或DDR。
首先,需要知道整个用户和内核空间是如何划分的(3:1、2:2),然后从Node->Zone->Page的层级进行初始化,直到内存达到可用状态。
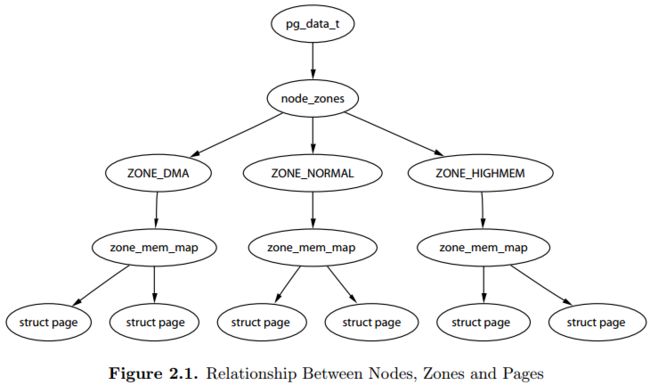
关于Nodes、Zones、Pages三者之间的关系,《ULVMM》 Figure 2.1介绍,虽然zone_mem_map一层已经被替代,但是仍然反映了他们之间的层级树形关系。
pg_data_t对应一个Node,node_zones包含了不同Zone;Zone下又定义了per_cpu_pageset,将page和cpu绑定。
2. 内存大小
1.2.1 DTS上报
ARM Linux, 所有的设备的相关属性描述都采用DTS(Device Tree Source)方式.
总结:
ARM Linux中,各种设备的相关属性描述(!!!)都采用DTS方式(!!!)呈现。DTS是device tree source,最早由PowerPC等其他体系结构使用的FDT(Flattened Device Tree)转变的,ARM Linux社区自2011年被Linus公开批评后全面支持DTS。
在ARM Vexpress平台中,内存的定义在vexpress-v2p-ca9.dts文件中。该DTS文件定义了内存的起始地址为0x60000000,大小为0x40000000,即1GB大小内存空间。
// [arch/arm/boot/dts/vexpress-v2p-ca9.dts]
// http://elixir.free-electrons.com/linux/v4.13.11/source/arch/arm/boot/dts/vexpress-v2p-ca9.dts#L65
memory@60000000 {
device_type = "memory";
reg = <0x60000000 0x40000000>;
};ARM64平台类似, 起始地址为 0x80000000, 大小 0x80000000(2GB).
// http://elixir.free-electrons.com/linux/v4.13.11/source/arch/arm64/boot/dts/arm/vexpress-v2f-1xv7-ca53x2.dts#L61
memory@80000000 {
device_type = "memory";
reg = <0 0x80000000 0 0x80000000>; /* 2GB @ 2GB */
};内核启动中,需要解析这些DTS文件,在early_init_dt_scan_memory()函数中。代码调用关系是:start_kernel()->setup_arch()->setup_machine_fdt()->early_init_dt_scan_nodes()->of_scan_flat_dt(遍历Nodes)->early_init_scan_memory(初始化单个内存node)。
[drivers/of/fdt.c]
void __init early_init_dt_scan_nodes(void)
{
/* Retrieve various information from the /chosen node */
of_scan_flat_dt(early_init_dt_scan_chosen, boot_command_line);
/* Initialize {size,address}-cells info */
of_scan_flat_dt(early_init_dt_scan_root, NULL);
/* Setup memory, calling early_init_dt_add_memory_arch */
of_scan_flat_dt(early_init_dt_scan_memory, NULL);
}最终early_init_dt_scan_nodes()调用了early_init_dt_scan_memory函数读取DTS的信息并初始化内存信息.
[drivers/of/fdt.c]
/**
* early_init_dt_scan_memory - Look for and parse memory nodes
*/
int __init early_init_dt_scan_memory(unsigned long node, const char *uname,
int depth, void *data)
{
const char *type = of_get_flat_dt_prop(node, "device_type", NULL);
const __be32 *reg, *endp;
int l;
bool hotpluggable;
/* We are scanning "memory" nodes only */
if (type == NULL) {
/*
* The longtrail doesn't have a device_type on the
* /memory node, so look for the node called /memory@0.
*/
if (!IS_ENABLED(CONFIG_PPC32) || depth != 1 || strcmp(uname, "memory@0") != 0)
return 0;
} else if (strcmp(type, "memory") != 0)
return 0;
reg = of_get_flat_dt_prop(node, "linux,usable-memory", &l);
if (reg == NULL)
reg = of_get_flat_dt_prop(node, "reg", &l);
if (reg == NULL)
return 0;
endp = reg + (l / sizeof(__be32));
hotpluggable = of_get_flat_dt_prop(node, "hotpluggable", NULL);
pr_debug("memory scan node %s, reg size %d,\n", uname, l);
while ((endp - reg) >= (dt_root_addr_cells + dt_root_size_cells)) {
u64 base, size;
base = dt_mem_next_cell(dt_root_addr_cells, ®);
size = dt_mem_next_cell(dt_root_size_cells, ®);
if (size == 0)
continue;
pr_debug(" - %llx , %llx\n", (unsigned long long)base,
(unsigned long long)size);
early_init_dt_add_memory_arch(base, size);
if (!hotpluggable)
continue;
if (early_init_dt_mark_hotplug_memory_arch(base, size))
pr_warn("failed to mark hotplug range 0x%llx - 0x%llx\n",
base, base + size);
}
return 0;
}解析 “memory” 描述的信息从而得到内存的base_address和 size信息,最后内存块信息通过early_init_dt_add_memory_arch()-> memblock_add() -> memblock_add_range函数添加到memblock子系统中。
struct memblock {
bool bottom_up; /* is bottom up direction? */
phys_addr_t current_limit;
struct memblock_type memory; #添加物理内存区域
struct memblock_type reserved; #添加预留内存区域
#ifdef CONFIG_HAVE_MEMBLOCK_PHYS_MAP
struct memblock_type physmem;
#endif
};
memblock_add用于添加region到memblock.memory中;在内核初始化阶段很多地方(比如arm_memblock_init)使用memblock_reserve将region添加到memblock.reserved。
memblock_remove用于将一个region从memblock.memory中移除,memblock_free等用于将一个region从memblock.reserved中移除。
这里面的地址都是物理地址,所有的信息都在memblock这个全局变量中。
[mm/memblock.c]
int __init_memblock memblock_add_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int nid, unsigned long flags)
{
bool insert = false;
phys_addr_t obase = base;
phys_addr_t end = base + memblock_cap_size(base, &size);
int i, nr_new;
if (!size)
return 0;
/* special case for empty array */
if (type->regions[0].size == 0) {
WARN_ON(type->cnt != 1 || type->total_size);
type->regions[0].base = base;
type->regions[0].size = size;
type->regions[0].flags = flags;
memblock_set_region_node(&type->regions[0], nid);
type->total_size = size;
return 0;
}
repeat:
/*
* The following is executed twice. Once with %false @insert and
* then with %true. The first counts the number of regions needed
* to accomodate the new area. The second actually inserts them.
*/
...
}memblock
在内核启动阶段,也有内存管理的需求,但是此时伙伴系统并没有完成初始化。在早期内核中使用bootmem机制,作为内核初始化阶段的内存分配器。
后来使用memblock作为内核初始化阶段内存分配器,用于内存分配和释放。
CONFIG_NO_BOOTMEM用于决定是否使用bootmem,Vexpress使能,所以使用memblock作为初始化阶段的内存分配器。
因为bootmem和memblock两者API兼容,所以使用者无感。使用memblock的时候编译mm/nobootmem.c,调用memblock.c中的分配器接口。
1.2.2 ACPI上报
待补充
3. 物理内存映射
由于没有打开CONFIG_ARM_LPAE,Linux页表采用两层映射。所以PGD->PUD->PMD->PTE中间的PUD/PMD被省略的,pmd_off_k的返回值实际就是pgd_offset_k。
[arch\arm\mm\mm.h]
static inline pmd_t *pmd_off_k(unsigned long virt)
{
return pmd_offset(pud_offset(pgd_offset_k(virt), virt), virt);
}
[arch\arm\include\asm\pgtable.h]
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
/* to find an entry in a kernel page-table-directory */
// 实际就是addr右移PGDIR_SHIFT位,然后相对于init_mm.pgd即swapper_pg_dir的偏移。
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
#swapper_pg_dir是存放内核页表的地方。在内核使用内存前,需要初始化内核的页表,初始化页表主要在map_lowmem()函数中。在映射页表之前,需要把页表的页表项清0,主要在prepare_page_table()函数中实现。
[start_kernel() ->setup_arch() ->paging_init() -> prepare_page_table()]
[arch/arm/mm/mmu.c]
static inline void prepare_page_table(void)
{
unsigned long addr;
phys_addr_t end;
/*
* Clear out all the mappings below the kernel image.
*/
for (addr = 0; addr < MODULES_VADDR; addr += PMD_SIZE) #清除0~MODULES_VADDR地址段一级页表。
pmd_clear(pmd_off_k(addr));
#ifdef CONFIG_XIP_KERNEL
/* The XIP kernel is mapped in the module area -- skip over it */
addr = ((unsigned long)_etext + PMD_SIZE - 1) & PMD_MASK;
#endif
for ( ; addr < PAGE_OFFSET; addr += PMD_SIZE) #清除MODULES_VADDR~PAGE_OFFSET地址段一级页表。
pmd_clear(pmd_off_k(addr));
/*
* Find the end of the first block of lowmem.
*/
end = memblock.memory.regions[0].base + memblock.memory.regions[0].size;
if (end >= arm_lowmem_limit) #end=0x60000000+0x40000000, arm_lowmem_limit=0x8f800000
end = arm_lowmem_limit;
/*
* Clear out all the kernel space mappings, except for the first
* memory bank, up to the vmalloc region.
*/
for (addr = __phys_to_virt(end);
addr < VMALLOC_START; addr += PMD_SIZE) #此处end取0x8f800000,转成虚拟地址0xef800000。
pmd_clear(pmd_off_k(addr)); #清除0xef800000~VMALLOC_START地址段一级页表。
}这里对如下3段地址调用pmd_clear()函数来清除一级页表项的内容。
- 0x0 ~ MODULES_VADDR。
- MODULES_VADDR ~ PAGE_OFFSET。
- arm_lowmem_limit(0xef800000)~ VMALLOC_START。
[start_kernel() ->setup_arch() ->paging_init() ->map_lowmem()]
[arch/arm/mm/mmu.c]
static void __init map_lowmem(void)
{
struct memblock_region *reg;
phys_addr_t kernel_x_start = round_down(__pa(_stext), SECTION_SIZE); #kernel_x_start=0x60000000
phys_addr_t kernel_x_end = round_up(__pa(__init_end), SECTION_SIZE); #kernel_x_end=60800000
/* Map all the lowmem memory banks. */
for_each_memblock(memory, reg) {
phys_addr_t start = reg->base; #start=0x60000000
phys_addr_t end = start + reg->size; #end=0x60000000+0x40000000
struct map_desc map;
if (end > arm_lowmem_limit)
// 因为arm_lowmem_limit=0x8f800000,所以end=0x8f800000
end = arm_lowmem_limit;
if (start >= end)
break;
if (end < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RWX;
create_mapping(&map);
} else if (start >= kernel_x_end) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
} else {
/* This better cover the entire kernel */
if (start < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = kernel_x_start - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
}
map.pfn = __phys_to_pfn(kernel_x_start);
map.virtual = __phys_to_virt(kernel_x_start);
map.length = kernel_x_end - kernel_x_start;
map.type = MT_MEMORY_RWX;
// 创建虚拟地址0xc0000000 - 0xc0800000到物理地址0x60000000 - 0x60800000的映射关系,属性为MT_MEMORY_RWX。
create_mapping(&map);
if (kernel_x_end < end) {
map.pfn = __phys_to_pfn(kernel_x_end);
map.virtual = __phys_to_virt(kernel_x_end);
map.length = end - kernel_x_end;
map.type = MT_MEMORY_RW;
// 创建虚拟地址0xc0800000 - 0xef800000到物理地址0x60800000 - 0x8f800000的映射关系,属性为MT_MEMORY_RW。
create_mapping(&map);
}
}
}
}真正创建页表是在map_lowmem()函数中,会从内存开始的地方覆盖到arm_lowmem_limit处。这里需要考虑kernel代码段的问题,kernel的代码段从_stext幵始,到_init_end结束。以ARM Vexpress平台为例。
- 内存开始地址0x60000000。
- _stext: 0x60000000。
- _init_end: 0x60800000(该值与实际内核配置和image大小相关)。
- arm_lowmem_limit: 0x8f800000。
其中,arm_lowmem_limit地址需要考虑高端内存的情况,该值的计算是在sanity_check_meminfo()函数中。在ARM Vexpress平台中,arm_lowmem_limit等于vmalloc_min,其定义如下:
static void * __initdata vmalloc_min =
(void *) (VMALLOC_END - (240 « 20) - VMALLOC_OFFSET);
phys_addr_t vmalloc_limit = __pa(vmalloc_min - 1) + 1 map_lowmem()会对两个内存区间创建映射。
(1)区间1
- 物理地址:0x60000000~0x60800000。
- 虚拟地址:0xc0000000~0xc0800000。
- 属性:可读、可写并且可执行(MT_MEMORY_RWX)。
- 主要用于存放Kernel代码数据段,还包括swapper_pg_dir内容。
(2)区间2
- 物理地址:0x60800000~0x8f800000。
- 虚拟地址:0xc0800000~0xef800000。
- 属性:可读、可写、不可执行(MT_MEMORY_RW )。
- Normal Memory部分。
MT_MEMORY_RWX和MT_MEMORY_RW的区别在于ARM页表项有一个XN比特位,XN比特位置为1 , 表示这段内存区域不允许执行。
映射函数为create_mapping(),这里创建的映射就是物理内存直接映射,即线性映射,该函数会在第2.2节中详细介绍。
4. zone初始化
对页表的初始化完成之后,内核就可以对内存进行管理了,但是内核并不是统一对待这些页面,而是采用层次化管理。
Linux把物理内存划分为三个层次来管理
| 层次 | 描述 |
|---|---|
| 存储节点(Node) | CPU被划分为多个节点(node), 内存则被分簇, 每个CPU对应一个本地物理内存, 即一个CPU-node对应一个内存簇bank,即每个内存簇被认为是一个节点 |
| 管理区(Zone) | 每个物理内存节点node被划分为多个内存管理区域, 用于表示不同范围的内存, 内核可以使用不同的映射方式(!!!)映射物理内存 |
| 页面(Page) | 内存被细分为多个页面帧, 页面是最基本的页面分配的单位 | |
为了支持NUMA模型,也即CPU对不同内存单元的访问时间可能不同,此时系统的物理内存被划分为几个节点(node), 一个node对应一个内存簇bank,即每个内存簇被认为是一个节点
-
首先, 内存被划分为结点. 每个节点关联到系统中的一个处理器, 内核中表示为pg_data_t的实例. 定义了一个大小为MAX_NUMNODES类型为pg_data_t的数组node_data,数组的大小根据CONFIG_NODES_SHIFT的配置决定. 对于UMA来说,NODES_SHIFT为0,所以MAX_NUMNODES的值为1. 而对于PC这种UMA结构的机器来说, 只使用了一个成为contig_page_data的静态pg_data_t结构.
-
各个节点又被划分为内存管理区域, 一个管理区域通过struct zone_struct描述, 其被定义为zone_t, 用以表示内存的某个范围,低端范围的16MB被描述为ZONE_DMA,某些工业标准体系结构中的(ISA)设备需要用到它,然后是可直接映射到内核的普通内存域ZONE_NORMAL,最后是超出了内核段的物理地址域ZONE_HIGHMEM, 被称为高端内存. 是系统中预留的可用内存空间, 不能被内核直接映射.
-
最后页帧(page frame)代表了系统内存的最小单位, 堆内存中的每个页都会创建一个struct page的一个实例. 传统上,把内存视为连续的字节,即内存为字节数组,内存单元的编号(地址)可作为字节数组的索引. 分页管理时,将若干字节视为一页,比如4K byte. 此时,内存变成了连续的页,即内存为页数组,每一页物理内存叫页帧,以页为单位对内存进行编号,该编号可作为页数组的索引,又称为页帧号.
在一个单独的节点内,任一给定CPU访问页面所需的时间都是相同的。然而,对不同的CPU,这个时间可能就不同。对每个CPU而言,内核都试图把耗时节点的访问次数减到最少这就要小心地选择CPU最常引用的内核数据结构的存放位置.
其中zone结构的定义用struct zone。struct zone数据结构的主要成员如下:
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_) ## 重要
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock; ## 重要
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
spinlock_t lru_lock; ## 重要
struct lruvec lruvec; ## 重要
ZONE_PADDING(_pad3_) ## 重要
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;首先struct zone是经常会被访问到的,因此这个数据结构要求以L1 Cache对齐。另外,这里的ZONE_PADDING()是让zone->lock和zone->lru_lock这两个很热门的锁可以分布在不同的cache line中。一个内存节点最多也就几个zone,因此zone数据结构不需要像struct page—样关注数据结构的大小,因此这里ZONE_PADDING()可以为了性能而浪费空间。在内存管理开发过程中,内核开发者逐步发现有一些自旋锁会竞争得非常厉害,很难获取。像zone->lock和zone->lru_lock这两个锁有时需要同时获取锁,因此保证它们使用不同的cache line是内核常用的一种优化技巧。
- watermark: 每个zone在系统启动时会计算出3个水位值,分别是WMARK_MIN、WMARK_LOW和WMARK_HIGH水位,这在页面分配器和kswapd页面回收中会用到。
- lowmem_reserve: zone中预留的内存。
- zone_pgdat: 指向内存节点。
- pageset: 用于维护Per-CPU上的一系列页面,以减少自旋锁的争用。
- zone_start_pfn: zone中开始页面的页帧号。
- managed_pages: zone中被伙伴系统管理的页面数量。
- spanned_pages: zone包含的页面数量。
- present_pages: zone里实际管理的页面数量。对一些体系结构来说,其值和spanned_pages相等。
- free_area: 管理空闲区域的数组,包含管理链表等。
- lock: 并行访问时用于对zone保护的自旋锁。
- lru_lock: 用于对zone中LRU链表并行访问时进行保护的自旋锁。
- lruvec: LRU链表集合。
- vm_stat:zone计数。
通常情况下,内核的zone分为ZONE_DMA、ZONE_DMA32、ZONE_NORMAL和ZONE_HIGHMEM。在ARM Vexpress平台中,没有定义CONFIG_ZONE_DMA和CONFIG_ZONE_DMA32,所以只有ZONE_NORMAL和ZONE_HIGHMEM两种。zone类型的定义在include/linux/mmzone.h 文件中。
enum zone_type {
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
_MAX_NR_ZONES
};zone的初始化函数集中在bootmem_init()中完成,所以需要确定每个zone的范围。在find_limits()函数中会计算出min_low_pfn、max_low_pfn和max_pfn这3个值。其中,min_low_pfn是内存块的开始地址的页帧号(0x60000),max_low_pfn(0x8f800)表示normal区域的结束页帧号,它由arm_lowmem_limit这个变量得来,max_pfn(0xa0000) 是内存块的结束地址的页帧号。
下面是ARM Vexpress平台运行之后打印出来的zone的信息。
Normal zone: 1520 pages used for memmap
Normal zone: 0 pages reserved
Normal zone: 194560 pages, LIFO batch:31 //ZONE_NORMAL
HighMem zone: 67584 pages, LIFO batch:15 //ZONE_HIGHMEM
Virtual kernel memory layout:
vector : 0xffff0000 - 0xffff1000 ( 4 KB)
fixmap : 0xffc00000 - 0xfff00000 (3072 KB)
vmalloc : 0x£0000000 - 0xff000000 ( 240 MB)
lowmem : 0xc0000000 - 0xef800000 ( 760 MB)
pkmap : 0xbfe00000 - 0xc0000000 ( 2 MB)
modules : 0xbf000000 - 0xbfe00000 ( 14 MB)
.text : 0xc0008000 - 0xc0676768 (6586 KB)
.init : 0xc0677000 - 0xc07a0000 (1188 KB)
.data : 0xc07a0000 - 0xc07cf938 ( 191 KB)
.bss : 0xc07cf938 - 0xc07f9378 ( 167 KB)
可以看出ARM Vexpress平台分为两个zone,ZONE_NORMAL和ZONE_HIGHMEM。其中ZONE_NORMAL是从0xc0000000到0xef800000,这个地址空间有多少个页面呢?
(Oxef800000 - Oxc0000000 ) / 4096 = 194560
所以ZONE_NORMAL有194560个页面。
另外ZONE_NORMAL的虚拟地址的结束地址是Oxef800000, 减去PAGE_OFFSET(Oxc00000),再加上PHY_OFFSET(0x60000000),正好等于 0x8f80_0000,这个值等于我们之前计算出的arm_lowmem_limit。
zone的初始化函数在free_area_init_core()中。
[mm/page_alloc.c]
static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
int ret;
pgdat_resize_init(pgdat);
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spin_lock_init(&pgdat->split_queue_lock);
INIT_LIST_HEAD(&pgdat->split_queue);
pgdat->split_queue_len = 0;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
#ifdef CONFIG_COMPACTION
init_waitqueue_head(&pgdat->kcompactd_wait);
#endif
pgdat_page_ext_init(pgdat);
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
realsize = freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
zone->min_unmapped_pages = (freesize*sysctl_min_unmapped_ratio)
/ 100;
zone->min_slab_pages = (freesize * sysctl_min_slab_ratio) / 100;
#endif
zone->name = zone_names[j];
spin_lock_init(&zone->lock);
spin_lock_init(&zone->lru_lock);
zone_seqlock_init(zone);
zone->zone_pgdat = pgdat;
zone_pcp_init(zone);
/* For bootup, initialized properly in watermark setup */
mod_zone_page_state(zone, NR_ALLOC_BATCH, zone->managed_pages);
lruvec_init(&zone->lruvec);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
ret = init_currently_empty_zone(zone, zone_start_pfn, size);
BUG_ON(ret);
memmap_init(size, nid, j, zone_start_pfn);
}
}
另外系统中会有一个zondist的数据结构,伙伴系统分配器会从zonelist开始分配内存,zonelist有一个zoneref数组,数组里有一个成员会指向zone数据结构。zoneref数组的第一个成员指向的zone是页面分配器的第一个候选者,其他成员则是第一个候选者分配失败之后才考虑,优先级逐渐降低。zonelist的初始化路径如下:
[start_kernel->build_all_zonelists->build_all_zonelists_init->
__build_all_zonelists->build_zonelists->build_zonelists_node]
static int build_zonelists_node(pg_data_t *pgdat, struct zonelist *zonelist,
int nr_zones)
{
struct zone *zone;
enum zone_type zone_type = MAX_NR_ZONES;
do {
zone_type--;
zone = pgdat->node_zones + zone_type;
if (populated_zone(zone)) {
zoneref_set_zone(zone,
&zonelist->_zonerefs[nr_zones++]);
check_highest_zone (zone_type);
}
} while (zone_type);
return nr_zones;
}从最高的MAX_NR_ZONES的zone开始,设置到_zonerefs[0]数组中。在ARM Vexpress平台中,运行结果如下:
HighMem _zonerefs[0]->zone_index=l
Normal _zonerefs[1]->zone_index=0
这个页面分配器在2.4会讲。
另外,系统中还有一个非常重要的全局变量mem_map,它是一个struct page的数组,可以实现快速地把虚拟地址映射到物理地址中,这里指内核空间的线性映射,它的初始化是在free_area_init_node()->alloc_node_mem_map()函数中。
5. 空间划分
在32bit Linux中 ,一共能使用的虚拟地址空间是4GB,用户空间和内核空间的划分通常是按照3:1来划分,也可以按照2:2来划分。
[arch/arm/Kconfig]
choice
prompt "Memory split"
depends on MMU
default VMSPLIT_3G
help
Select the desired split between kernel and user memory.
If you are not absolutely sure what you are doing, leave this
option alone!
config VMSPLIT_3G
bool "3G/1G user/kernel split"
config VMSPLIT_3G_OPT
depends on !ARM_LPAE
bool "3G/1G user/kernel split (for full 1G low memory)"
config VMSPLIT_2G ### !!!
bool "2G/2G user/kernel split"
config VMSPLIT_1G
bool "1G/3G user/kernel split"
endchoice
config PAGE_OFFSET
hex
default PHYS_OFFSET if !MMU
default 0x40000000 if VMSPLIT_1G
default 0x80000000 if VMSPLIT_2G
default 0xB0000000 if VMSPLIT_3G_OPT
default 0xC0000000在 ARM Linux中有一个配置选项“memory split”,可以用于调整内核空间和用户空间的大小划分。通常使用“VMSPLIT_3G”选项,用户空间大小是3GB , 内核空间大小是1GB ,那么PAGE_OFFSET描述内核空间的偏移量就等于0xC0000000(等于2^31+2^30=3GB)。也可以选择“VMSPLIT_2G”选项,这时内核空间和用户空间的大小都是2GB,PAGE_OFFSET就等于0x80000000(等于2^31=2GB)。
这样配置的结果就是生成的autoconf.h(include/generated/autoconf.h)定义了#define CONFIG_PAGE_OFFSET 0xC0000000。
内核中通常会使用PAGE_OFFSET这个宏来计算内核线性映射中虚拟地址和物理地址的转换。
[arch/arm/include/asm/memory.h]
/* PAGE_OFFSET - the virtual address of the start of the kernel image */
#define PAGE_OFFSET UL(CONFIG_PAGE_OFFSET)
线性映射的物理地址等于虚拟地址vaddr减去PAGE_OFFSET (0xC000_0000)再加上PHYS_OFFSET(在部分ARM系统中该值为0)。
[arch/arm/include/asm/memory.h]
static inline phys_addr_t __virt_to_phys_nodebug(unsigned long x)
{
return (phys_addr_t)x - PAGE_OFFSET + PHYS_OFFSET;
}
static inline unsigned long __phys_to_virt(phys_addr_t x)
{
return x - PHYS_OFFSET + PAGE_OFFSET;
}
6. 物理内存初始化
在内核启动时,内核知道物理内存DDR的大小并且计算出高端内存的起始地址和内核空间的内存布局后,物理内存页面page就要加入到伙伴系统中,那么物理内存页面如何添加到伙伴系统中呢?
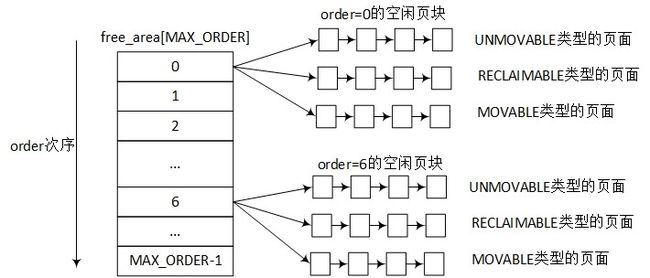
伙伴系统(Buddy System)是操作系统中最常用的一种动态存储管理方法,在用户提出申请时,分配一块大小合适的内存块给用户,反之在用户释放内存块时回收。在伙伴系统中,内存块是2的order次幂。Linux内核中order的最大值用MAX_ORDER来表示,通常是11,也就是把所有的空闲页面分组成11个内存块链表,每个内存块链表分别包括1、2、4、8、16、32、…、1024个连续的页面(连续页面!!!)。1024个页面对应着4MB大小的连续物理内存。
物理内存在Linux内核中分出几个zone来管理,zone根据内核的配置来划分,例如在ARM Vexpress平台中,zone分为ZONE_NORMAL和ZONE_HIGHMEM。
伙伴系统的空闲页块的管理如图2.2所示,zone数据结构中有一个free_area数组,数组的大小是MAX_ORDER。free_area数据结构中包含了MIGRATE_TYPES个链表,这里相当于zone中根据order的大小有0到MAX_ORDER - l个free_area,每个free_area根据MIGRATE_TYPES类型有几个相应的链表。
图2.2 伙伴系统的空闲页块管理:
[include/linux/mmzone.h]
struct zone{
...
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
...
};
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
MIGRATE_TYPES 类型的定义也在mmzone.h 文件中。
[include/1inux/mmzone.h]
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};
MIGRATE_TYPES 类型包含MIGRATE_UNMOVABLE、MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE等几种类型。当前页面分配的状态可以从**/proc/pagetypeinfo**中获取得到。
图2.3 ARM Vexpress平台pagetypeinfo信息:
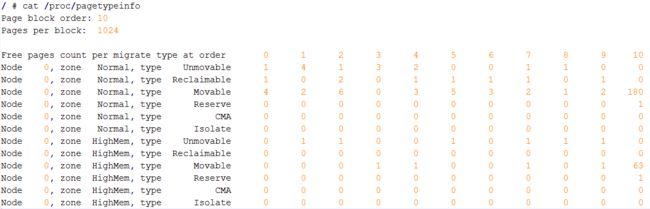
从 pagetypeinfo可以看出两个特点:
- 大部分物理内存页面都存放在MIGRATE_MOVABLE链表中。
- 大部分物理内存页面初始化时存放在2的10次幂的链表中。
Linux内核初始化时究竟有多少页面是MIGRATE_MOVABLE?
内存管理中有一个pageblock的概念,一个pageblock的大小通常是(MAX_ORDER - l)个页面。如果体系结构中提供了HUGETLB_PAGE特性,那么pageblock_order定义为HUGETLB_PAGE_ORDER。
[include/linux/pageblock-flags.h]
#ifdef CONFIG_HUGETLB_PAGE
#ifdef CONFIG_HUGETLB_PAGE_SIZE_VARIABLE
/* Huge page sizes are variable */
extern unsigned int pageblock_order;
#else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
/* Huge pages are a constant size */
#define pageblock_order HUGETLB_PAGE_ORDER
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
#else /* CONFIG_HUGETLB_PAGE */
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order (MAX_ORDER-1)
#endif /* CONFIG_HUGETLB_PAGE */
每个pageblock有一个相应的MIGRATE_TYPES类型。zone数据结构中有一个成员指针pageblock_flags,它指向用于存放每个pageblock的MIGRATE_TYPES类型的内存空间。pageblock_flags指向的内存空间的大小通过usemap_size()函数来计算,每个pageblock用4个比特位来存放MIGRATE_TYPES类型。
zone的初始化函数free_area_init_core()会调用setup_usemap()函数来计算和分配pageblock_flags所需要的大小,并且分配相应的内存。
[free_area_init_core -> setup_usemap -> usemap_size]
[mm/page_alloc.c]
static unsigned long __init usemap_size(unsigned long zone_start_pfn, unsigned long zonesize)
{
unsigned long usemapsize;
zonesize += zone_start_pfn & (pageblock_nr_pages-1);
usemapsize = roundup(zonesize, pageblock_nr_pages);
usemapsize = usemapsize >> pageblock_order;
usemapsize *= NR_PAGEBLOCK_BITS;
usemapsize = roundup(usemapsize, 8 * sizeof(unsigned long));
return usemapsize / 8;
}
usemap_size()函数首先计算zone有多少个pageblock,每个pageblock需要4bit来存放MIGRATE_TYPES类型,最后可以计算出需要多少Byte。然后通过memblock_virt_alloc_try_nid_nopanic()来分配内存,并且zone->pageblock_flags成员指向这段内存。
例如在ARM Vexpress平台,ZONE_NORMAL的大小是760MB,每个pageblock大小是4MB,那么就有190个pageblock,每个pageblock的MIGRATE_TYPES类型需要4bit,所以管理这些pageblock,需要96Byte。
内核有两个函数来管理这些迁移类型:get_pageblock_migratetype()和set_pageblock_migratetype()。内核初始化时所有的页面最初都标记为MIGRATE_MOVABLE类型,见free_area_init_core()->memmap_init()函数。
// [start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()
->free_area_init_node()->free_area_init_core()->memmap_init()]
void __meminit memmap_init_zone (unsigned long size, int nid, unsigned long zone,
unsigned long start_jpfn, enum memmap_context context)
{
struct page *page;
unsigned long end_pfn = start_pfn + size;
unsigned long pfn;
struct zone *z;
z = &NODE_DATA (nid) ->node zones [zone];
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
page = pfn_to._page (pfn);
init_page_count(page);
page_mapcount_reset(page);
page_cpupid—reset—last(page);
SetPageReserved(page);
if ((z->zone_start_pfn <= pfn)
&& (pfn < zone end_pfn(z))
&& ! (pfn & (pageblock_nr_pages - 1)))
set_pageblock_migratetype (page, MIGRATE_MOVABLE);
INIT_LIST_HEAD(&page->lru);
}
}set_pageblock_migratetype()用于设置指定pageblock的MIGRATE_TYPES类型,最后调用set_pfnblock_flags_mask()来设置pagelock的迁移类型。
物理页面是如何加入到伙伴系统的?是一页一页地添加,还是以2的几次幂来加入吗?
在free_low_memory_core_early()函数中,通过for_each_free_mem_range()函数来遍历所有的memblock内存块,找出内存块的起始地址和结束地址。
// [staxt_kemel-> mm_init-> mem_init-> free_all_bootmem-> free_low_memory_core_early]
[mm/nobootmem.c]
static unsigned long __init free_low_memory_core_early(void)
{
unsigned long count = 0;
phys_addr_t start, end;
u64 i;
memblock_clear_hotplug(0, -1);
for_each_free_mem_range(i, NUMA_NO_NODE, &start, &end,NULL)
count += __free_memory_core(start, end);
return count;
}把内存块传递函数中 ,该函数定义如下:
// [mm/nobootmem.c]
static inline unsigned long _ffs(unsigned long x)
{
return ffs(x) - 1;
}
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{
int order;
while (start < end) {
order = min(MAX_ORDER - 1UL, __ffs(start));
while (start + (1UL << order) > end)
order--;
__free_pages_bootmem(pfn_to_page(start), start, order);
start += (1UL << order);
}
}注意这里参数start和end指页帧号,while循环一直从起始页帧号start遍历到end,循环的步长和order有关。首先计算order的大小,取MAX_ORDER-l和__ffs(start)的最小值。ffs(start)函数计算start中第一个bit为1的位置,注意__ffs()=ffs()-1。因为伙伴系统的链表都是2的n次幂,最大的链表是2的10次方,也就是1024,即0x400。所以,通过ffs()函数可以很方便地计算出地址的对齐边界。例如start等于0x63300,那么__ffs(0x63300)等于8,那么这里order选用8。
得到order值后,我们就可以把这块内存通过__free_pages_bootmem()函数添加到伙伴系统了。
void __init __free_pages_bootmem(struct page *page, unsigned int order)
{
unsigned int nr_pages = 1 << order;
struct page *p = page;
page_zone(page)->managed_pages += nr_pages;
set_page_refcounted (page);
__free_pages(page, order};
}
__free_pages()函数是伙伴系统的核心函数,这里按照order的方式添加到伙伴系统中,该函数在第2.4节中会详细介绍。
下面是向系统中添加一段内存的情况,页帧号范围为[0x8800e, Oxaecea],以start为起始来计算其order,一开始order的数值还比较凌乱,等到start和0x400对齐,以后基本上order都取值为10了,也就是都挂入order为10的 free_list链表中。
__free_pages_memory: start=0x8800e, end=0xaecea
__free_pages_memory: start=0x8800e, order=1, __ffs()=1, ffs()=2
__free_pages_memory: start=0x88010, order=4, __ffs()=4, ffs()=5
__free_pages_memory: start=0x88020, order=5, __ffs()=5, ffs()=6
__free_pages_memory: start=0x88040, order=6, __ffs()=6, ffs()=7
__free_pages_memory: start=0x88080, order=7, __ffs()=7, ffs()=8
__free_pages_memory: start=0x88100, order=8, __ffs()=8, ffs()=9
__free_pages_memory: start=0x88200, order=9, __ffs()=9, ffs()=10
__free_pages_memory: start=0x88400, order=10, __ffs()=10, ffs()=11
__free_pages_memory: start=0x88800, order=10, __ffs()=11, ffs()=12
__free_pages_memory: start=0x88c00, order=10, __ffs()=10, ffs()=11
__free_pages_memory: start=0x89000, order=10, __ffs()=12, ffs()=13
__free_pages_memory: start=0x89400, order=10, __ffs()=10, ffs()=11
__free_pages_memory: start=0x89800, order=10, __ffs()=11, ffs()=12
__free_pages_memory: start=0x89c00, order=10, __ffs()=10, ffs()=11
7 小结
7.1 内存空间
内存空间分三层
| 层次 | 描述 |
|---|---|
| 用户空间层 | 可以理解为Linux 内核内存管理为用户空间暴露的系统调用接口. 例如brk(), mmap()等系统调用. 通常libc库会将系统调用封装成大家常见的C库函数, 比如malloc(), mmap()等. |
| 内核空间层 | 包含的模块相当丰富, 用户空间和内核空间的接口时系统调用, 因此内核空间层首先需要处理这些内存管理相关的系统调用, 例如sys_brk, sys_mmap, sys_madvise等. 接下来就包括VMA管理, 缺页中断管理, 匿名页面, page cache, 页面回收, 反向映射, slab分配器, 页面管理等模块. |
| 硬件层 | 包含处理器的MMU, TLB和cache部件, 以及板载的物理内存, 例如LPDDR或者DDR |
pg_data_t对应一个Node,node_zones包含了不同Zone;Zone下又定义了per_cpu_pageset,将page和cpu绑定。
7.2
ARM Linux, 各种设备的相关属性描述都采用DTS方式呈现.
内核启动, 解析DTS文件, 得到内存的base_address和size, 最后内存块信息通过memblock_add()添加到memblock子系统中, 内核启动阶段, 内存管理(分配和释放)便使用memblock机制作为内核初始化阶段的内存分配器.
根据配置项和处理器, 确定Linux页表(PGD->PUD->PMD->PTE)使用哪些.
内核使用内存前, 需要初始化内核的页表, 即建立页表映射.
对页表的初始化完成之后,内核就可以对内存进行管理了,但是内核并不是统一对待这些页面,而是采用层次化管理。
Linux把物理内存划分为三个层次来管理
| 层次 | 描述 |
|---|---|
| 存储节点(Node) | CPU被划分为多个节点(node), 内存则被分簇, 每个CPU对应一个本地物理内存, 即一个CPU-node对应一个内存簇bank,即每个内存簇被认为是一个节点 |
| 管理区(Zone) | 每个物理内存节点node被划分为多个内存管理区域, 用于表示不同范围的内存, 内核可以使用不同的映射方式(!!!)映射物理内存 |
| 页面(Page) | 内存被细分为多个页面帧, 页面是最基本的页面分配的单位 | |
为了支持NUMA模型,也即CPU对不同内存单元的访问时间可能不同,此时系统的物理内存被划分为几个节点(node), 一个node对应一个内存簇bank,即每个内存簇被认为是一个节点
-
首先, 内存被划分为结点. 每个节点关联到系统中的一个处理器, 内核中表示为pg_data_t的实例. 定义了一个大小为MAX_NUMNODES类型为pg_data_t的数组node_data,数组的大小根据CONFIG_NODES_SHIFT的配置决定. 对于UMA来说,NODES_SHIFT为0,所以MAX_NUMNODES的值为1. 而对于PC这种UMA结构的机器来说, 只使用了一个成为contig_page_data的静态pg_data_t结构.
-
各个节点又被划分为内存管理区域, 一个管理区域通过struct zone_struct描述, 其被定义为zone_t, 用以表示内存的某个范围,低端范围的16MB被描述为ZONE_DMA,某些工业标准体系结构中的(ISA)设备需要用到它,然后是可直接映射到内核的普通内存域ZONE_NORMAL,最后是超出了内核段的物理地址域ZONE_HIGHMEM, 被称为高端内存. 是系统中预留的可用内存空间, 不能被内核直接映射.
-
最后页帧(page frame)代表了系统内存的最小单位, 堆内存中的每个页都会创建一个struct page的一个实例. 传统上,把内存视为连续的字节,即内存为字节数组,内存单元的编号(地址)可作为字节数组的索引. 分页管理时,将若干字节视为一页,比如4K byte. 此时,内存变成了连续的页,即内存为页数组,每一页物理内存叫页帧,以页为单位对内存进行编号,该编号可作为页数组的索引,又称为页帧号.