Hive从0.11版本开始提供了ORC的文件格式,ORC文件不仅仅是一种列式文件存储格式,最重要的是有着很高的压缩比,并且对于MapReduce来说是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升,因为ORC较其他文件格式压缩比高,查询任务的输入数据量减少,使用的Task也就减少了。
ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Spark SQL、Presto等查询引擎支持,但是Impala对于ORC目前没有支持,仍然使用Parquet作为主要的列式存储格式。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。
例如,与RCFile格式相比,ORC文件格式具有许多优点,例如:
- 一个文件作为每个任务的输出,这减少了NameNode的负载
- 支持复杂的数据结构,Hive类型支持包括datetime,decimal和复杂类型(struct,list,map和union)
- 三级索引,存储在文件中的轻量级索引,能过滤掉没在查找范围内的数据块,快速查询到满足条件的数据
- 基于数据类型的块模式压缩,整数列的行程编码,字符串列的字典编码,减少了读或写所需的数据量
- 分割的数据块,使用单独的RecordReaders并发读取同一文件
由于ORC普遍应用于Apache大数据生态,了解其原理,有助于hive和presto查询优化。
列式存储
列式存储可以提升OLAP查询查询性能,但是它是如何做到的呢?这就要从列式存储的原理说起,从图1中可以看到,相对于关系数据库中通常使用的行式存储,在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
1)查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum,字符类型数据长度等),实现部分的谓词下推。
2)由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
3)由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。

文件结构
从下图可以看到ORC文件结构
ORC文件的元数据一个ORC文件会被分成多个stripe,而且文件的元数据中有每个字段的统计信息(min/max,sum,hasNull等等),这就为ORC的查询优化做好了基础准备。
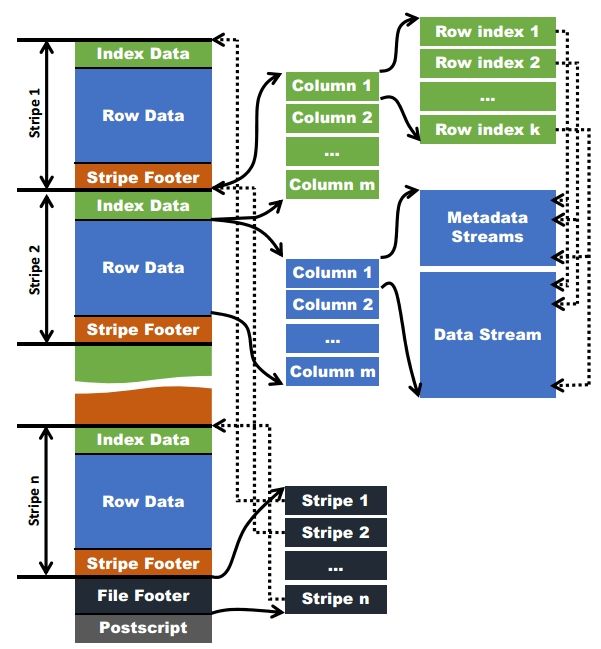
整个文件从下往上分成几个部分:
1)Postscript: 提供了解释文件其余部分的必要信息,包括文件的页脚和元数据部分的长度,文件的版本以及使用的常规压缩类型(例如,none,zlib,LZO,LZ4,ZSTD或snappy)
2)File Footer: 包含文件正文的布局,类型架构信息,行数以及每个列的统计信息。
3)Stripe条带数据块:文件正文分为条带。每个条带都是自包含的,只能使用自己的字节与文件的Footer和Postscript结合使用。每个条带仅包含整行,因此行不会跨越条带边界。Stripes有三个部分:条带中行的一组索引,数据本身和条带页脚。索引和数据部分都按列分割,因此只需要读取所需列的数据。
4)列统计:列统计信息的目标是,对于每个列,编写器记录计数并根据其他有用字段的类型进行记录。对于大多数原始类型,它记录最小值和最大值; 对于数字类型,它还存储总和。从Hive 1.1.0开始,列统计信息还将通过设置hasNull标志来记录行组中是否存在任何空值。ORC的谓词下推使用hasNull标志来更好地回答'IS NULL'查询。真实列数据块,其中又分为Index data( 记录每列的索引信息),Raw Data(记录原始数据),Stripe Footer(记录每列的统计信息,min/max/sum等)。
Stripe在默认情况下64MB。文件中的条带彼此独立,形成分布式工作的自然单元。在每个条带中,列彼此分开,因此Reader只能读取所需的列。
三级索引
ORC在每个文件中提供三级索引:
文件级别 - 有关整个文件中每列中的值的统计信息
stripe条带级别 - 有关每个条带的每列中的值的统计信息
行级别 (行组)- 条带中每组10,000行(默认值)的每列值的统计信息
文件和条带级别列统计信息位于文件页脚中,因此可以轻松访问它们以确定是否需要读取文件的其余部分。行级索引包括每个行组的列统计信息和搜索行组开头的位置。
列统计信息始终包含值的计数以及是否存在空值。大多数其他原始类型包括最小值和最大值,对于数字类型,则包括总和。从Hive 1.2开始,索引可以包括bloom过滤器,它提供了更具选择性的过滤器。
索引工作原理
1)假如我的查询过滤条件为WHERE id = 0;在Map Task读到一个ORC文件时,首先从文件的统计信息(一级索引)中看看id字段的min/max值,如果0不包含在内,那么跳过该文件
2)如果在这个文件中,那么继续查看每个stripe中id字段的min/max值(二级索引),如果0不包含在内,那么跳过在stripe
3)如果在该stripe中,则继续匹配行组中的min/max值(三级索引),如果0不包含在内,那么跳过该行组。如果0包含在内min和max范围内,则利用布隆过滤器再次判断是否一定不在内,不在内则继续跳过该行组。
这种索引通常用于数值型字段的查询过滤优化上。
布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),布隆过滤器是一个 bit 向量或者说 bit 数组和一组hash函数组成。特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
布隆过滤器可以应用在各种类型字段上,包括字符串和二进制。
谓词下推
谓词下推(predicate pushdown)属于逻辑优化。优化器可以将谓词过滤下推到数据源,从而使物理执行跳过无关数据。在逻辑层面可以理解为利用where 条件中的过滤条件将无用的数据进行筛选掉最终得到需要的行列。
在ORC中表现为:
1)列式存储可以容易过滤掉不需要的列数据
2)利用三级索引中的统计信息可以跳过不需要的文件,条带块或行组
Hive建表优化
Hive中建表使用ORC存储格式时,ORC默认会开启索引。这样可以充分利用ORC索引减少数据扫描时间。
- 建议ETL过程中将where语句后经常过滤的字段预先排序后插入数据表
- 建议在建ORC表时对于where语句后经常过滤的字段添加在布隆过滤器中
CREATE TABLE bdc_dm.res_category_orc(
channel_id1 int comment '1级渠道id',
province string COMMENT '省',
city string comment '市',
uv int comment 'uv'
)
comment 'example'
partitioned by (landing_date int COMMENT '日期:yyyymmdd')
row format delimited fields terminated by '\t'
stored as orc
TBLPROPERTIES (
"orc.compress"="SNAPPY",
'orc.create.index'='true',
"orc.bloom.filter.columns"="channel_id1,uv",
'orc.bloom.filter.fpp'='0.05',
'orc.stripe.size'='10485760',
'orc.row.index.stride'='10000'
);
上面用到的参数见下表,有些含有默认值,可以不用设置。由于ZLIB压缩性能不如Snappy,ORC文件压缩器一般设置为snappy。
| 参数名 | 默认值 | 含义 |
|---|---|---|
| orc.compress | ZLIB | 高级压缩器 = {NONE, ZLIB, SNAPPY} |
| orc.compress.size | 262,144 | 压缩块大小 |
| orc.stripe.size | 67,108,864 | 每个stripe块中的字节数 |
| orc.row.index.stride | 10,000 | 行组大小 |
| orc.create.index | true | 是否创建索引 |
| orc.bloom.filter.columns | "" | 逗号分隔的列名列表,用于创建bloom过滤器 |
| orc.bloom.filter.fpp | 0.05 | 布隆过滤器的假阳性概率 (must >0.0 and <1.0) |
参考文档
https://orc.apache.org/docs/index.html
https://orc.apache.org/specification/ORCv1/
https://www.jianshu.com/p/2104d11ee0a2
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
http://lxw1234.com/archives/2016/04/632.htm
http://lxw1234.com/archives/2016/04/630.htm
https://www.cnblogs.com/ITtangtang/p/7677912.html