HDFS技术原理
- HDFS概述及应用场景
- HDFS在FusionInsight产品的位置
- HDFS系统架构
- 关键特性介绍
HDFS概述及应用场景举例
HDFS(Hadoop Distributed File System)基于Google发布的GFS论文设计开发,运行在通用硬件上的分布式文件系统。其除具备其它分布式文件系统相同特性外,还有自己特有的特性:
高容错性:认为硬件总是不可靠的
高吞吐量:为大量数据访问的应用提供高吞吐量支持 大文件存储:支持存储TB-PB级别的数据
HDFS适合做什么?大文件存储、流式数据访问
HDFS不适合做什么?大量小文件、随机写入、低延迟读取
HDFS是Hadoop技术框架中的分布式文件系统,对部署在多台独立物理机器上的文件进行管理。可应用于以下几种场景:
网站用户行为数据存储
生态系统数据存储
气象数据存储
2、HDFS在FusionInsight产品的位置

系统设计目标
硬件失效
硬件的异常比软件的异常更加常见。
对于有上百台服务器的数据中心来说认为总有服务器异常,硬件异常是常态。
HDFS需要监测这些异常,并自动恢复数据。
流式数据访问
基于HDFS的应用仅采用流式方式读数据。
运行在HDFS上的应用并非以通用业务为目的的应用程序。 应用程序关注的是吞吐量,而非响应时间。
非POSIX标准接口的数据访问。
存储数据较大
运行在HDFS的应用程序有较大的数据需要处理。
典型的文件大小为GB到TB级别。
数据一致性
应用程序采用WORM(Write Once Read Many)的数据读写模型。
文件仅支持追加,而不允许修改。
多硬件平台
HDFS可运行在不同的硬件平台上。
移动计算能力
计算和存储采用就近原则,计算离数据最近。
就近原则将有效减少网络的负载,降低网络拥塞。
3、基本系统架构
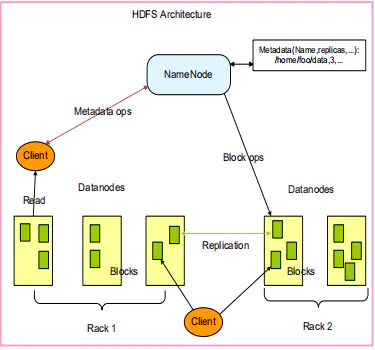
HDFS架构包含三个部分:NameNode,DataNode,Client
NameNode:NameNode用于存储、生成文件系统的元数据。运行一个实例。
DataNode:DataNode用于存储实际的数据,将自己管理的数据块上报给NameNode ,运行多个实例。
Client:支持业务访问HDFS, 从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行。
4、关键特性介绍
HDFS架构关键设计
HDFS数据读取流程
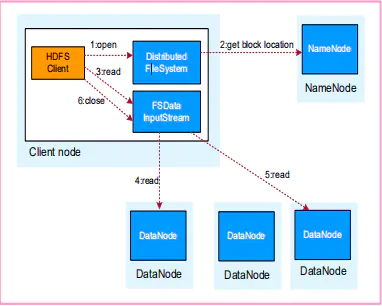
HDFS数据读取流程如下:
- 业务应用调用HDFS Client提供的API打开文件。
- HDFS Client联系NameNode,获取到文件信息(数据块、DataNode位置信息)。
- 业务应用调用read API读取文件。
- HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应的数据块。(Client采用就近原则读取数据)。
- HDFS Client会与多个DataNode通讯获取数据块。
- 数据读取完成后,业务调用close关闭连接。
HDFS数据写入流程
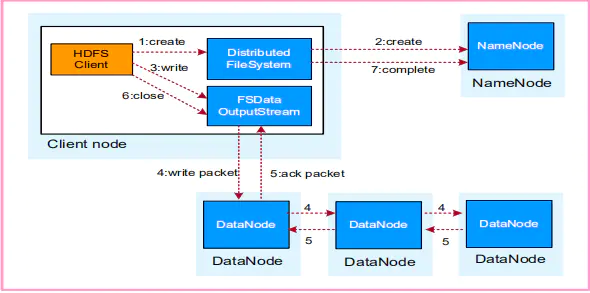
- 业务应用调用HDFS Client提供的API创建文件,请求写入。
- HDFS Client联系NameNode,NameNode在元数据中创建文件节点。3. 业务应用调用write API写入文件。
- HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并将需要写入数据的DataNode建立起流水线,完成后,客户端再通过自有协议写入数据到DataNode1,再由DataNode1复制到DataNode2, DataNode3。
- 写完的数据,将返回确认信息给HDFS Client。
- 所有数据确认完成后,业务调用HDFS Client关闭文件。
- 业务调用close,flush后HDFS Client联系NameNode,确认数据写完成,NameNode持久化元数据。
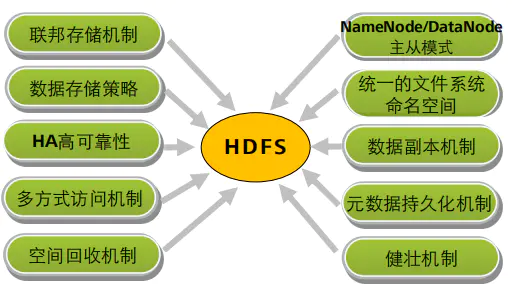
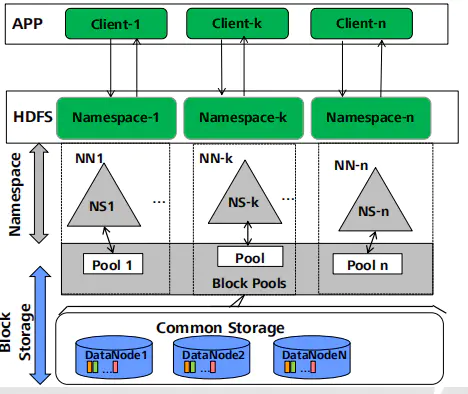
HDFS联邦(Federation)
数据副本机制
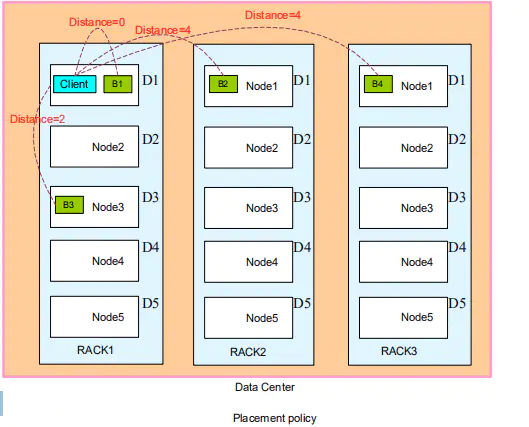
副本距离计算公式:
Distance(Rack1/D1, Rack1/D1)=0 同一台服务器的距离为0
Distance(Rack1/D1, Rack1/D3)=2 同一机架不同的服务器距离为2
Distance(Rack1/D1, Rack2/D1)=4不同机架的服务器距离为4
副本放置策略:
第一个副本在本地机器
第二个副本在远端机架的节点
第三个副本看之前的两个副本是否在
同一机架,如果是则选择其他机架,否则选择和第一个副本相同机架的不同节点,第四个及以上,随机选择副本存放位置。
元数据持久化
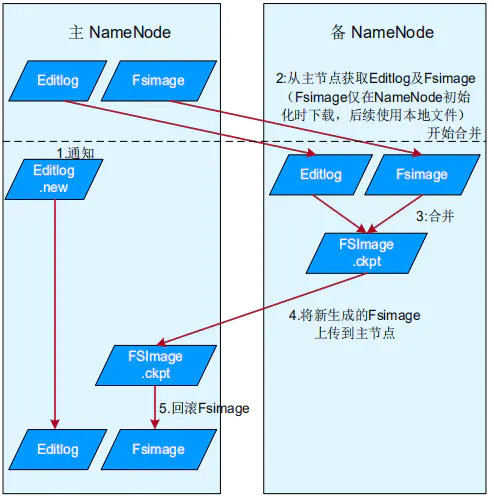
元数据持久化的流程如下:
1.备NameNode通知主NameNode生成新的日志文件,以后的日志写到Editlog.new中,并获取旧的Editlog。
2.备NameNode从主NameNode上获取FSImage文件及旧的EditLog。
3.备NameNode将日志和旧的元数据合并,生成新的元数据FSImage.ckpt。
4.备NameNode将元数据上传到主NameNode。
5.主NameNode将上传的元数据进行回滚。
6.循环步骤1。
元数据持久化健壮机制
HDFS主要目的是保证存储数据完整性。对于各组件的失效,做了可靠性处理。
重建失效数据盘的副本数据
DataNode向NameNode周期上报失败时,NameNode发起副本重建动作以恢复丢失副本。
集群数据均衡 HDFS架构设计了数据均衡机制,此机制保证数据在各个DataNode上分布是平均的。
数据有效性保证 DataNode数据在读取时校验失败,则从其他数据节点读取数据。
元数据可靠性保证
采用日志机制操作元数据,同时元数据存放在主备NameNode上。
快照机制实现了文件系统常见的快照机制,保证数据误操作时,能及时恢复。
安全模式
HDFS提供独有安全模式机制,在数据节点故障,硬盘故障时,能防止故障扩散。
配置HDFS数据存储策略
默认情况下,HDFS NameNode自动选择DataNode保存数据的副本。在实际业务中,存在以下场景:
DataNode上存在的不同的存储设备,数据需要选择一个合适的存储设备分级存储数据。
DataNode不同目录中的数据重要程度不同,数据需要根据目录标签选择一个合适的DataNode节点保存。
DataNode集群使用了异构服务器,关键数据需要保存在具有高度可靠性的节点组中。
配置HDFS数据存储策略-分级存储
配置DataNode使用分级存储:HDFS的异构分级存储框架提供了RAM_DISK(内存虚拟硬盘)、DISK(机械硬盘)、ARCHIVE(高密度低成本存储介质)、SSD(固态硬盘)四种存储类型的存储设备。通过对四种存储类型进行合理组合,即可形成适用于不同场景的存储策略。

配置HDFS数据存储策略-标签存储
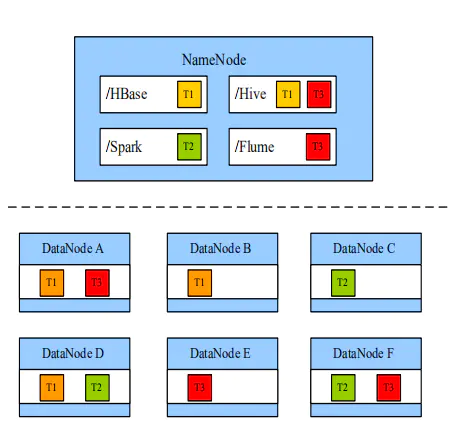
image.png
配置DataNode使用标签存储:用户通过数据特征灵活配置HDFS数据块摆放策略,即为一个HDFS目录设置一个标签表达式,每个DataNode可以对应一个或多个标签;当基于标签的数据块摆放策略为指定目录下的文件选择DataNode节点进行存放时,根据文件的标签表达式选择出将要存放的DataNode节点范围,然后在这个DataNode节点范围内,遵守下一个指定的数据块摆放策略进行存放。
配置HDFS数据存储策略-节点组存储
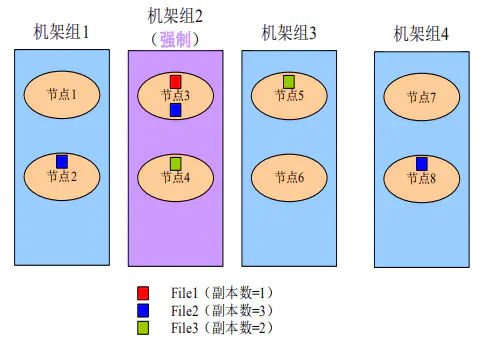
配置DataNode使用节点组存储:关键数据根据实际业务需要保存在具有高度可靠性的节点中,此时DataNode组成了异构集群。通过修改DataNode的存储策略,系统可以将数据强制保存在指定的节点组中。
使用约束:
第一份副本将从强制机架组(机架组2)中选出,如果在强制机架组中没有可用节点,则写入失败。
第二份副本将从本地客户端机器或机架组中的随机节点中(当客户端机器机架组不为强制机架组时)选出。
第三份副本将从其他机架组中选出。
各副本应存放在不同的机架组中。
如果所需副本的数量大于可用的机架组数量,则会将多出的副本存放在随机机架组中。
Colocation同分布
同分布(Colocation)的定义:将存在关联关系的数据或可能要进行关联操作的数据存储在相同的存储节点上。

Colocation同分布效果图

Hadoop 实现文件级同分布,即存在相关联的多个文件的所有块都分布在同一存储节点上。文件级同分布实现文件的快速访问,避免了因数据搬迁带来的大量网络开销。
HDFS高可靠性

HDFS的高可靠性(HA)架构
在基本架构上增加了以下组件:
ZooKeeper
分布式协调,主要用来存储HA下的状态文件,主备信息。ZK个数建议3个及以上且为奇数个。
NameNode主备
NameNode主备模式,主提供服务,备合并元数据并作为主的热备。
ZKFC
ZKFC(ZooKeeper Failover Controller)用于控制NameNode节点的主备状态。
JN
JN(JournalNode)用于共享存储NameNode生成的Editlog。
HDFS架构其他关键设计要点说明
统一的文件系统:HDFS对外仅呈现一个统一的文件系统。
统一的通讯协议:统一采用RPC方式通信。NameNode被动的接收Client, DataNode的RPC请求
空间回收机制:支持回收站机制,以及副本数的动态设置机制。
数据组织:数据存储以数据块为单位,存储在操作系统的HDFS文件系统上。
访问方式:提供JAVA API,HTTP方式,SHELL方式访问HDFS数据。
HDFS支持接口

思考题
- HDFS是什么样的系统,适合于做什么?
- HDFS的设计目标是什么?
- HDFS包含哪些组件?
- 请简述HDFS的读写流程。
- HDFS元数据是如何持久化的?
作者:雁翎枪
链接:https://www.jianshu.com/p/cdb9b36811cb
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。