Python 爬虫、抓包
什么是爬虫?
爬虫就是模拟客户端(浏览器、电脑app、手机app)发送网路请求,获取相应,按照规则提取数据的程序。
模拟客户端发送网路请求:照着浏览器一模一样的请求,获取和浏览器一模一样的数据
爬虫的应用:
爬虫的数据
可以呈现在网页上、app上 例如:新闻、视频等。
也可以获取数据,进行数据的分析找出潜藏在数据中的规律 例如:百度指数
开发环境:
python3,pycharm、谷歌或者火狐浏览器。其他的ide也可以
浏览器请求分析
每当我们在百度的搜索框输入内容并点击‘’百度一下‘’的时候,浏览器会发送很多的网络请求,我们可以按住键盘上的F12键来调出浏览器的控制台,在控制台上点击网络选项卡可以看到所有的请求
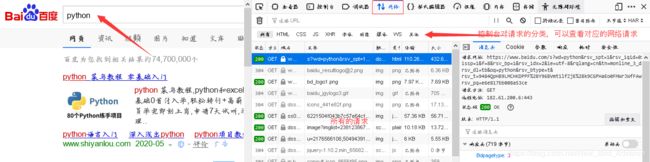 每个请求都会有一个请求头(Headers)
每个请求都会有一个请求头(Headers)
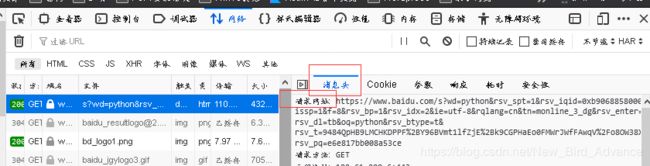
URL地址的分析:
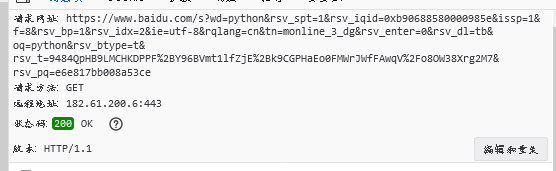
https协议 : // www.baidu.com域名 /s路径 之后是参数: ?wd=python&rsv_spt=1&rsv_iqid=0xb90688580000985e&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=monline_3_dg&rsv_enter=0&rsv_dl=tb&oq=python&rsv_btype=t&rsv_t=9484QpHB9LMCHKDPPF%2BY96BVmt1lfZjE%2Bk9CGPHaEo0FMWrJWfFAwqV%2Fo8OW38Xrg2M7&rsv_pq=e6e817bb008a53ce
- 协议:https 或者 http
- 网站的域名:www.baidu.com
- 资源路径:/s 等 像文件路径一样的东西
- 参数:以问号开头,a=b、c=d、&符号连接,出现百分号+数字的是UrlEncode编码,我们可以搜索解码器来解码。
浏览器请求的过程:
- 点击搜索之后,浏览器会请求url地址,我们可以看 控制台->网络的第一个请求地址,然后找响应(这个响应就时当前服务器根据你的url返回的内容,也可以通过在页面上右键点击查看网页源代码,查看当前url所对应的响应
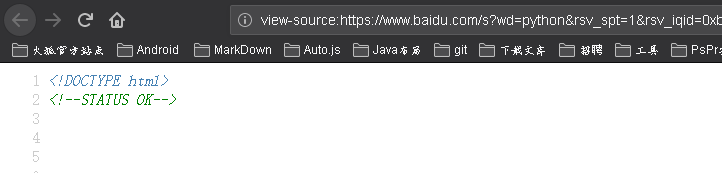
这两处的内容时相同的注意:也会有不同的时候,例如:有些网站更新内容比较快,像贴吧等网站,但网站的框架是一样的,只是填充的内容不同而已):
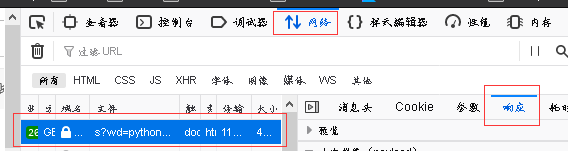 响应选项卡中会有一些字符串,浏览器就会去解析这些字符串,然后渲染界面,渲染过程中会发现有图片的url地址、js的url地址、css的url地址等,那么浏览器会再次发送网络请求来请求这些文件,如此变导致了网络选项卡中有很多请求。
响应选项卡中会有一些字符串,浏览器就会去解析这些字符串,然后渲染界面,渲染过程中会发现有图片的url地址、js的url地址、css的url地址等,那么浏览器会再次发送网络请求来请求这些文件,如此变导致了网络选项卡中有很多请求。
爬虫的请求:
- 请求时只会请求当前url地址的响应,并不会解析当前响应并去继续请求css、js等文件。就算你把css、js等文件全部请求下来,爬虫也不会将这些文件渲染在一起组成浏览器这样的界面。由此可以看到,爬虫可以做到浏览器做到的一些事情,像投票、买票、购物、下载等
Http 与 Https
- 在控制台 -> 网络 选中请求后,第一个标签页Headers中 下面General:Request Url 或者
 中经常会看到http 或者 https
中经常会看到http 或者 https
Http:
- 超文本传输协议
- 明文形式传输,例如:账号、密码
- 效率高、不安全l
Https:
- http + ssl(安全套接字层)
- 加密形式传输,传输之前先加密,之后解密获取内容
- 效率低、安全
其他参数分析:
请求头
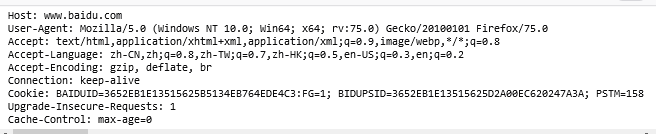
在消息头中包含的请求头有如下内容
-
Connection:Keep-alive 通知服务器,客户端支持长链接,如果服务器也支持长链接,那么就会在建立连接之后再请求相同网站内容时会复用第一次的链接,缩短请求时间。
-
Cache-Control:缓存控制,max-age=0,客户端对服务端不做任何缓存
-
User-Agent:用户代理,可以理解成浏览器的身份标识,可以通过这个表示让服务器知晓我们使用的是什么设备在请求数据。
火狐浏览器:
电脑端:
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0
手机安卓端:
Mozilla/5.0 (Android; Mobile; rv:18.0) Gecko/18.0 Firefox/18.0
IE浏览器 :
Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; WOW64; Trident/6.0)
等等。。。,这是非常重要的参数,服务器可以根据这个来区分爬虫。同样的爬虫也会使用这个参数来伪装自己。 -
Upgrade-Insecure-Requests:客户端通知服务端将不安全的请求转换为安全的请求,将http变为https等
-
Accept:客户端可以接收类型的数据
-
Accept-Encoding:客户端可以接收什么编码方式的数据如gzip 一种压缩方式等
-
Accept-Language:客户端可以接收什么语言的数据
-
Cookie:客户端保存的用户信息,通过Cookie可以获取到登录之后才能获取的信息。例如:账号、密码、状态信息,此参数可以区分爬虫与程序,此参数也很重要,每次请求都要携带。
请求体
可以从网络标签页中看请求是get还是post
- get请求是没有请求体的,参数放在url中
- post请求是有请求体,请求体中是参数,常用于登录、注册、传输大文本的时候
响应
响应头
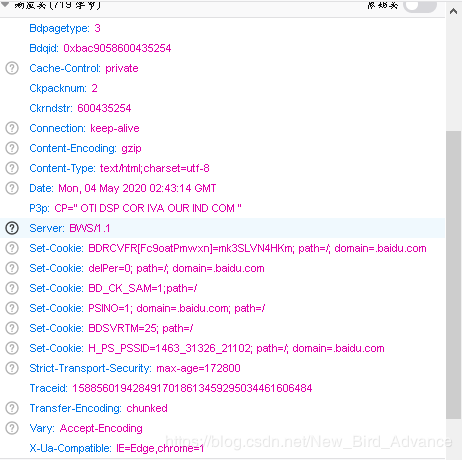 Set-Cookie:服务器通过这个字段来设置客户端的Cookie
Set-Cookie:服务器通过这个字段来设置客户端的Cookie
当然还可以通过js来设置客户端本地的Cookie
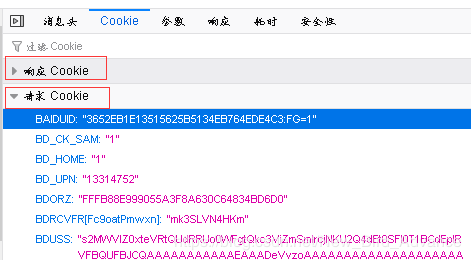 这里的cookie可以从请求头中查看到,比较关键
这里的cookie可以从请求头中查看到,比较关键
响应体
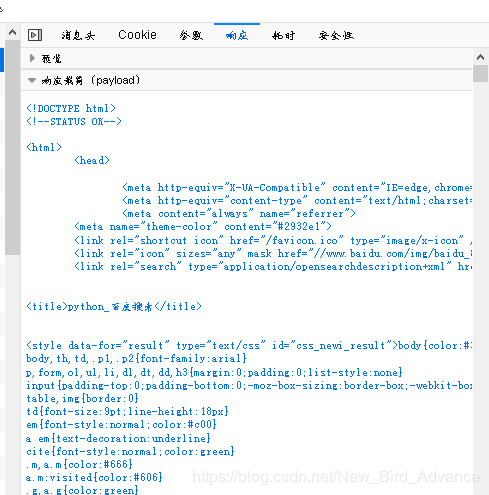 爬虫伪装是呢,就是模拟请求头中的关键内容如:UserAgent、Cookie等即可
爬虫伪装是呢,就是模拟请求头中的关键内容如:UserAgent、Cookie等即可
request 模块学习
安装
pip install requests
使用
发送请求的方式:
get请求
response = requesrs.get(url)
发送get请求并使用response来接收响应
import requests
url = "http://www.baidu.com"
response = requests.get(url)
print(response)
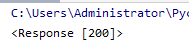 尖括号往往代表着一个对象,Response是个对象 200是个请求成功的状态码
尖括号往往代表着一个对象,Response是个对象 200是个请求成功的状态码
post请求
response = requests.post(url,data={请求体的字典})
发送一个post请求
这里利用手机版本的 百度翻译举例子


import requests
url = "https://fanyi.baidu.com/basetrans" # url地址在请求头中可以看见
query_string = {"query":"人生",
"from":"zh",
"to":"en"} # 参数
response = requests.post(url,data=query_string);
print(response)
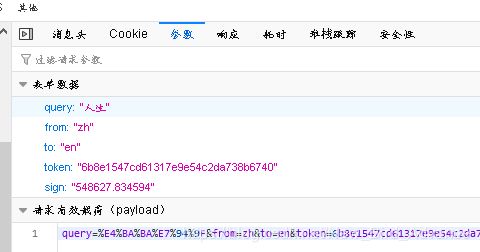 结果仍然是个对象,之后会解释如何变成字符串
结果仍然是个对象,之后会解释如何变成字符串
解析对象
方式一:
response.text #该方式会出现乱码
获取响应中的字符串
以get请求获取字符串为例子(post请求相同):
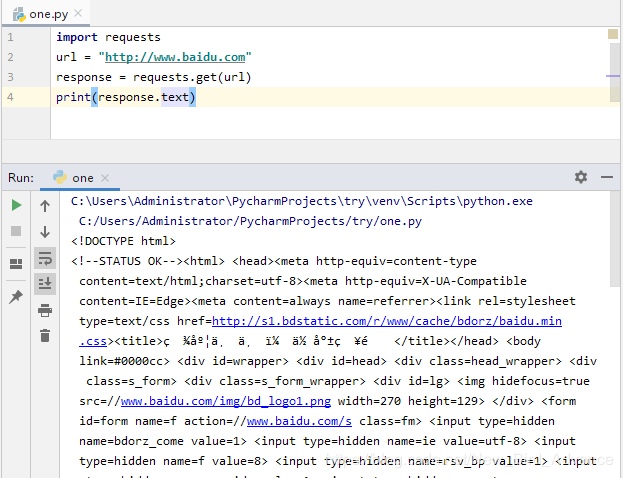 解码格式需要变化:一般网页都是utf-8格式,在 response.text 之前加上一个
解码格式需要变化:一般网页都是utf-8格式,在 response.text 之前加上一个response.encoding="utf-8" #指定解码格式即可
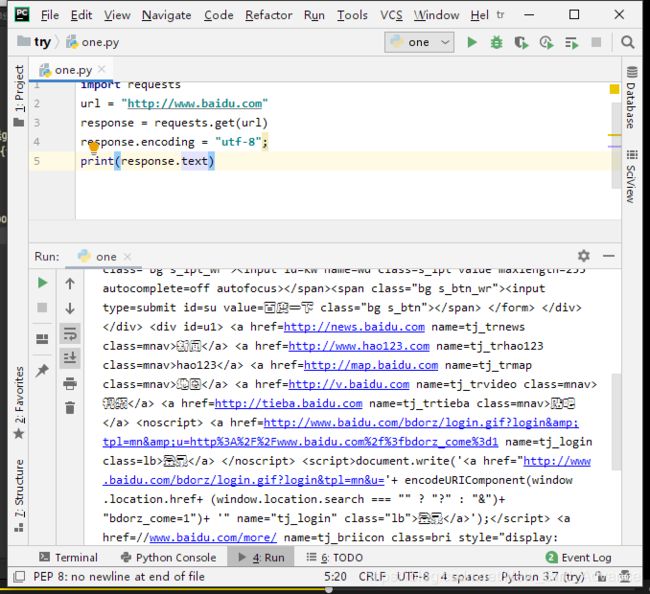
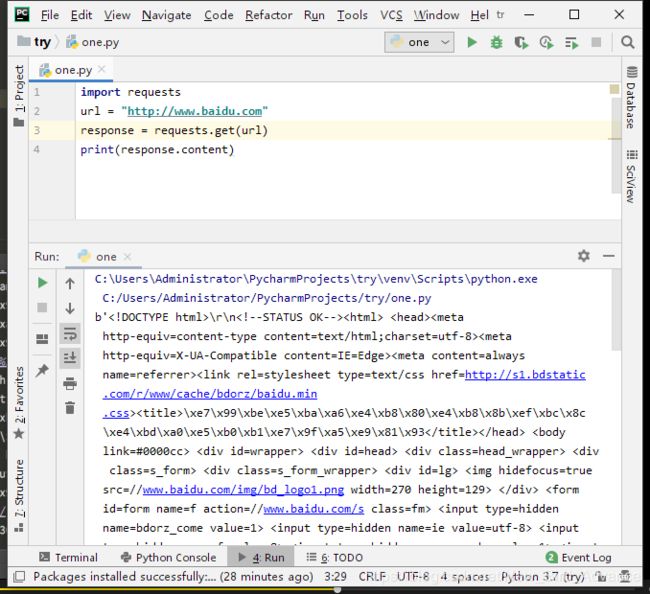
方式二:
response.content # 返回的是一个byte类型,也需要解码
response.content.decode() #对byte类型进行解码,更方便
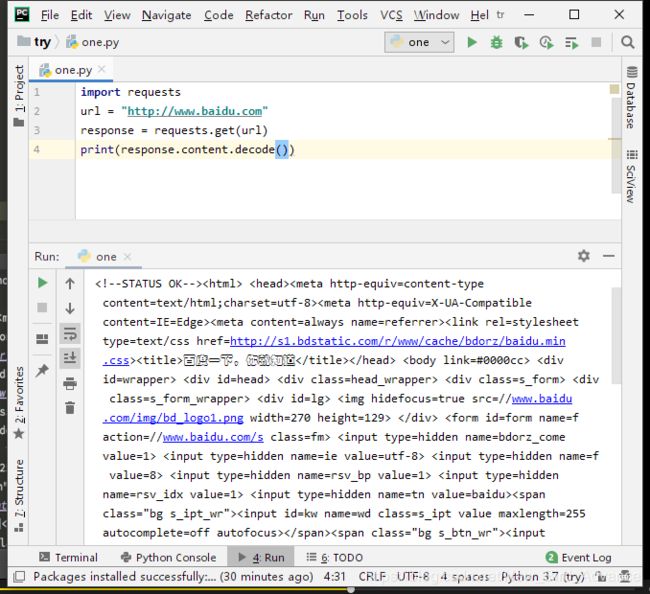
方式三:
在使用上面两种都不可以后,要替换成下面的代码
response.content.decode("gbk")
response.text #碰运气
使用post请求被服务端判断为爬虫: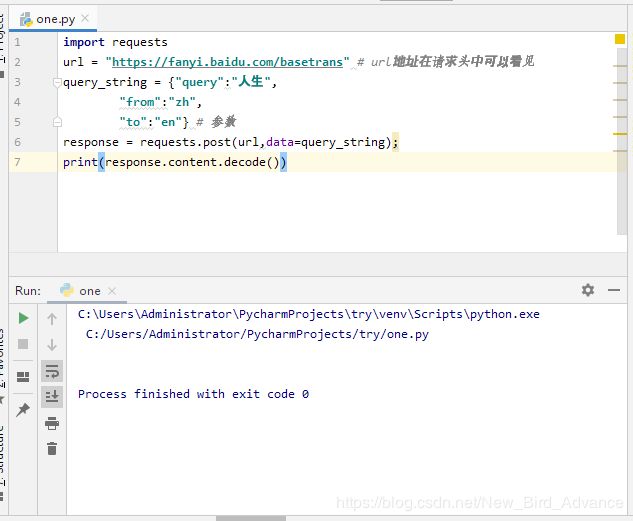
使用response查看当前响应的信息
response.request.url # 查看当前响应的网址
response.request.headers # 查看请求头
response.headers # 查看响应头
添加headers
这些请求头都是一个一个参数尝试出来的,需要就向里面添加,包括参数也是,这些内容都可以从浏览器控制台页面的网络标签页中的请求中找到。若不加headers,服务器会判断你是一个爬虫,并返回你一个假数据
headers = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1","Referer":"https://fanyi.baidu.com/?aldtype=16047"}
import requests
url = "https://fanyi.baidu.com/basetrans" # url地址在请求头中可以看见
query_string = {"query":"人生",
"from":"zh",
"to":"en",
"token":"6b8e1547cd61317e9e54c2da738b6740",
"sign":"548627.834594"} # 参数
headers_string = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
"Cookie":"BAIDUID=3652EB1E13515625B5134EB764EDE4C3:FG=1; BIDUPSID=3652EB1E13515625D2A00EC620247A3A; PSTM=1584412752; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1588206030,1588481363,1588546956,1588566527; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=s2MWVIZ0xteVRtQUdRRUo0WFgtQkc3VjZmSmlrcjNKU2Q4dEt0SFl0T1BCdEplRVFBQUFBJCQAAAAAAAAAAAEAAADeVvzoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI95ql6PeapeS0; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; yjs_js_security_passport=7e8d62bafc4c8187893cfbd6840f2b54c2ace19e_1588569021_js; H_PS_PSSID=1463_31326_21102; delPer=0; PSINO=1; BDRCVFR[Fc9oatPmwxn]=aeXf-1x8UdYcs; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1588569155; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1588566596; Hm_lpvt_afd111fa62852d1f37001d1f980b6800=1588569155"}
response = requests.post(url,data=query_string,headers=headers_string);
print(response.content.decode())

超时参数
网络有延迟时,规定一段时间内返回数据否则报错
response = requests.get(url.headers=headers,timeout=3)
3s内必须返回响应否则会报错
retrying模块的使用
pip install retrying
from retrying import retry
#执行的函数代码
@retry(stop_max_attempt_number=3) # 让被装饰的函数反复执行3次,三次全部报错才报错,中间的报错正常
def _parse_url(url,headers_string):
"""关于请求url地址的方法"""
response = requests.get(url,headers=headers_string,timeout=5)
return response.content.decode()
def parse_url(url,headers_string):
"""这里用来返回错误信息"""
try:
html_str = _parse_url(url,headers_string)
except:
html_str = None
return html_str
正例子:
import requests
from retrying import retry
@retry(stop_max_attempt_number=3) # 让被装饰的函数反复执行3次,三次全部报错才报错,中间的报错正常
def _parse_url(url,headers_string):
"""关于请求url地址的方法"""
print("*"*100)
response = requests.get(url,headers=headers_string,timeout=5)
return response.content.decode()
def parse_url(url,headers_string):
try:
html_str = _parse_url(url,headers_string)
except:
html_str = None
return html_str
url = "https://www.baidu.com" # url地址在请求头中可以看见
headers_string = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
"Cookie":"BAIDUID=3652EB1E13515625B5134EB764EDE4C3:FG=1; BIDUPSID=3652EB1E13515625D2A00EC620247A3A; PSTM=1584412752; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1588206030,1588481363,1588546956,1588566527; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=s2MWVIZ0xteVRtQUdRRUo0WFgtQkc3VjZmSmlrcjNKU2Q4dEt0SFl0T1BCdEplRVFBQUFBJCQAAAAAAAAAAAEAAADeVvzoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI95ql6PeapeS0; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; yjs_js_security_passport=7e8d62bafc4c8187893cfbd6840f2b54c2ace19e_1588569021_js; H_PS_PSSID=1463_31326_21102; delPer=0; PSINO=1; BDRCVFR[Fc9oatPmwxn]=aeXf-1x8UdYcs; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1588569155; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1588566596; Hm_lpvt_afd111fa62852d1f37001d1f980b6800=1588569155"}
print(parse_url(url,headers_string)[:20])

反例子:
将上面代码的url改成:www.baidu.com 即可
处理Cookie相关的请求
1.直接在headers中携带Cookie参数,详情请往上翻,查看
添加Headers模块,post请求百度翻译 的代码
2.直接在requests.get();或者requests.post();参数中传入Cookie的参数
import requests
url = "https://fanyi.baidu.com/basetrans" # url地址在请求头中可以看见
query_string = {"query":"人生",
"from":"zh",
"to":"en",
"token":"6b8e1547cd61317e9e54c2da738b6740",
"sign":"548627.834594"} # 参数
headers_string = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"}
cookie = "BAIDUID=3652EB1E13515625B5134EB764EDE4C3:FG=1; BIDUPSID=3652EB1E13515625D2A00EC620247A3A; PSTM=1584412752; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1588206030,1588481363,1588546956,1588566527; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=s2MWVIZ0xteVRtQUdRRUo0WFgtQkc3VjZmSmlrcjNKU2Q4dEt0SFl0T1BCdEplRVFBQUFBJCQAAAAAAAAAAAEAAADeVvzoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI95ql6PeapeS0; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; yjs_js_security_passport=7e8d62bafc4c8187893cfbd6840f2b54c2ace19e_1588569021_js; H_PS_PSSID=1463_31326_21102; delPer=0; PSINO=1; BDRCVFR[Fc9oatPmwxn]=aeXf-1x8UdYcs; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1588569155; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1588566596; Hm_lpvt_afd111fa62852d1f37001d1f980b6800=1588569155";
cookie_dit = {i.split("=")[0] : i.split("=")[1] for i in cookie.split("; ")}
print(cookie_dit)
response = requests.post(url,data=query_string,headers=headers_string,cookies=cookie_dit);
print(response.content.decode())

但是如果cookie中有干扰项则没有第一种来的方便
如:
BAIDUID=3652EB1E13515625B5134EB764EDE4C3:FG=1
增加了分析的时长
3.seesion发送post请求获取cookie,带上cookie再请求
cookie的持久化保持
以人人网为例子:
1.seesion = requests.session() # session方法具有和requests一样的方法
2.session.post(url,data,headers); # 假设成功 服务器的cookie会保存在seesion中
3.seesion.get(url) #会带上之前保存在seesion的cookie
import requests
url = "http://www.renren.com/PLogin.do"
query_string = {"email":"*******","password":"*******"}
headers_string = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"}
seesion = requests.session()
seesion.post(url,data=query_string,headers=headers_string)
url = "http://www.renren.com/974362318/newsfeed/photo"
response = seesion.get(url,headers=headers_string)
print(response.content.decode())
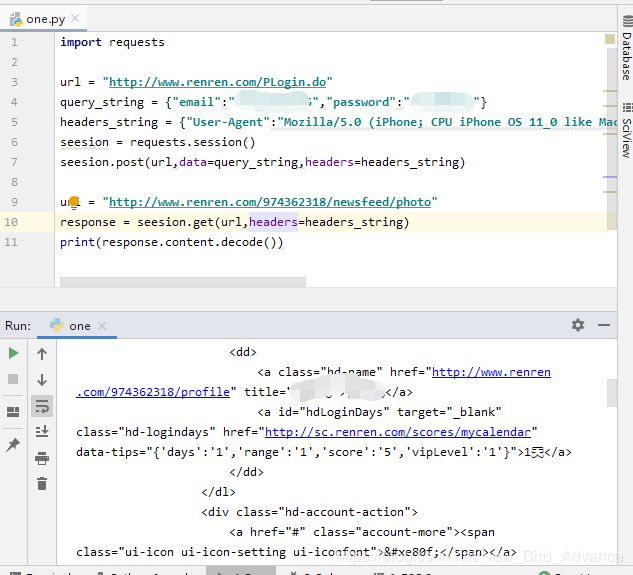
这些登录的接口可以在 控制台的查看器中找到,如果找不到可以在网络标签页中通过抓包一个一个分析得到,在登录时,页面会刷新,如果想保持记录可以将保持记录打勾
 也可以用第三方抓包工具如:Fidder等
也可以用第三方抓包工具如:Fidder等
数据分析
json
- 数据交换格式,类型像python的列表或者字典但其实是个字符串
- json的解析:json.loads 将json字符串转换为python类型
import requests
import json
url = "https://fanyi.baidu.com/basetrans" # url地址在请求头中可以看见
query_string = {"query":"人生",
"from":"zh",
"to":"en",
"token":"6b8e1547cd61317e9e54c2da738b6740",
"sign":"548627.834594"} # 参数
headers_string = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
"Cookie":"BAIDUID=3652EB1E13515625B5134EB764EDE4C3:FG=1; BIDUPSID=3652EB1E13515625D2A00EC620247A3A; PSTM=1584412752; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1588206030,1588481363,1588546956,1588566527; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=s2MWVIZ0xteVRtQUdRRUo0WFgtQkc3VjZmSmlrcjNKU2Q4dEt0SFl0T1BCdEplRVFBQUFBJCQAAAAAAAAAAAEAAADeVvzoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI95ql6PeapeS0; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; yjs_js_security_passport=7e8d62bafc4c8187893cfbd6840f2b54c2ace19e_1588569021_js; H_PS_PSSID=1463_31326_21102; delPer=0; PSINO=1; BDRCVFR[Fc9oatPmwxn]=aeXf-1x8UdYcs; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1588569155; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1588566596; Hm_lpvt_afd111fa62852d1f37001d1f980b6800=1588569155"}
response = requests.post(url,data=query_string,headers=headers_string);
print(json.loads(response.content.decode()))
print(type(json.loads(response.content.decode())))

之后操作字典来获取对应的值
print("翻译:"+json.loads(response.content.decode())["trans"][0]["dst"])
- 将python的字典转化为json用json.dumps();
json.dumps(传入字典,ensure_ascii=False 显示中文,indent=2 换行的效果)
xpath
-
一门用来从html中提取数据的语言
-
xpath helper插件:帮助从elements中定位数据,但爬虫是抓不到elements中的数据的,因为elements中的数据是根据js渲染的。如果url的响应的数据与elements一样时就可以用。
-
常用语法:
-
1.选择节点 / 标签
/html/head/meta能够选中html下的head下的所有的meta标签 -
2.选择当前页面下的任何一个节点 //
//li选择整个页面下的所有li标签
/html/head//link选中head下的所有的li标签 -
3选择指定的标签
//div[@class="xxxx"]/ul/li对标签进行限定 -
4.取标签中的值
/a/@herf取a标签中的herf值 -
5.获取标签中的文本
/a/text()取a标签中的text值
/a//text()取a标签中的所有text值
使用lxml
- 安装lxml
pip install lxml
- 使用
from lxml import etree
element = etree.HTML("html字
符串")
element.xpath("") //引号中填入对应的xpath表达式
- element.xpath() 返回的使一个element对象,我们可以用list来接收
urlEncode的解码与编码
- 在写爬虫的时候,经常会看到链接中有类似于这样的字符串:
%e6%88%91%e7%9a%84%e4%b8%96%e7%95%8c
- 其实这就使一个urlencode码,我们可以通过解码工具进行解码
urlencode解码网站
以上的urlencode的意思是:我的世界
- 在python3中我们可以使用urllib中的parse模块
from urllib import parse
编码:
print(parse.quote("我的世界"))
![]()
解码:
print(parse.unquote("%E6%88%91%E7%9A%84%E4%B8%96%E7%95%8C"))
![]()
by黑马程序员有感