人体姿态识别有了PaddlePaddle实现,它是否会成为下一个AI宠儿?
随着深度学习技术的发展,人体骨骼关键点的检测效果也在不断提升,且被广泛应用于计算机视觉相关领域,成为许多计算机视觉任务的基础,包括安防,新零售,动作捕捉,人机交互等等。现在,大火的人体姿态识别也有了PaddlePaddle的实现。我们来带小伙伴们学习一下怎么利用PaddlePaddle来实现人体姿态的识别任务。
项目地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/human_pose_estimation
应用背景
人体姿态识别(Human pose estimation)是指还原给定的一段视频或者是一张照片中人体关键点的位置。近年来研究人员对姿态识别深入研究,使得该领域得到了重大发展。伴随的是整体的算法和系统复杂性的增加,这导致了算法分析和比较变得更加困难。在这里我们用PaddlePaddle实现了简单有效的基准方法(baseline methods),并在有挑战性的benchmark上实现了最先进的结果,这会有助于激发一些新的ideas和简化评估方式。
人类姿态识别可以应用在众多领域,比如应用在安防领域,判断画面中的人是否有过激行为并及时报警。应用在新零售领域判断人们的购买行为。或者应用于步态分析,评估运动员的运动状况,进而提升运动员成绩。以及应用于人机交互领域,用户可以隔空控制家电设备等等方面。
下面的视频是一个基于Paddle Fluid,应用MSRA提供的用于人体姿态识别和跟踪的简单基准论文[1]的重新实现的简单演示。

图1 视频演示:Bruno Maes- That's What I Like [官方视频]
原文作者认为目前的姿态识别方法都过于复杂,并且有显著的差异,比如Hourglass,CPN等等,比较这些工作的差异性,更多体现在系统层面而不是信息层面。比如:MPII基准测试的主要方法在许多细节上有很大的差异,但是在准确性上的差别又很小。所以很难说哪些细节是影响准确性的重要因素。此外,关于COCO基准测试的主要代表性工作也很复杂,但是差别很大,这些方法之间的比较主要是在系统层面而不是信息层面。因此,该文作者提出了一个既精确,又简单(网络结构非常简单)的姿态估计方法,作为一个baseline,希望能激发一些新的ideas和简化评估方式。
姿态检测
文章的一个核心问题就是一个简单的方法到底能有多好的结果?为了能更好的回答这个核心问题,作者提供了一个baseline方法用于姿态识别和跟踪,虽然baseline十分简单,但是效果也十分地有效。因此我们将baseline和两个当前最先进的人体姿态识别方法Hourglass和CPN作比较。三者的网络结构比较如下图所示:
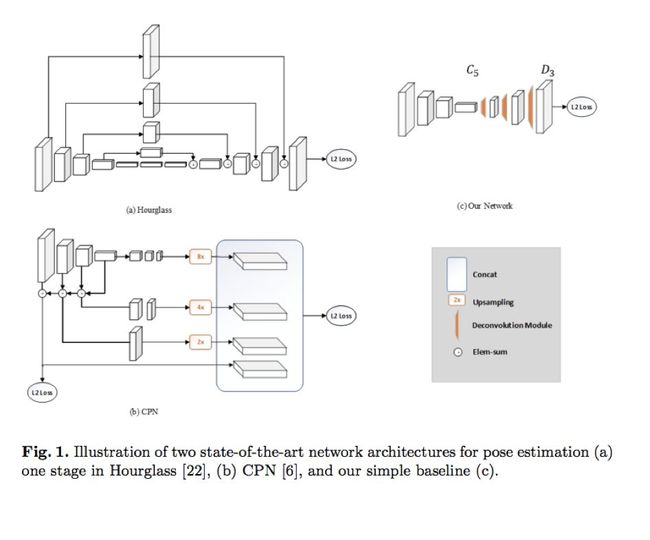
作者在文中提出的姿态识别方式是一种简单的baseline(图1中的c小图),相比于Hourglass和CPN,该网络结构比较简单,没有任何的特征融合。只是在ResNet中插入了几层反卷积(Deconvolution)来替换Upsampling与convolution组成的结构,这样可以将低分辨率的特征图(feature map)扩张为原图的大小,进而可以生成预测关键点需要的Heatmap。但是本文的方法在COCO关键点检测的任务上比CPN和Hourglass得到了更好的结果,即更高的AP(average precision)值,如图2:
 图2:简单的baseline、 Hourglass和CPN在COCO val2017数据集上的比较结果
图2:简单的baseline、 Hourglass和CPN在COCO val2017数据集上的比较结果
姿态追踪

图3:提出的flow-based姿态追踪框架
对于视频中的多人姿态跟踪,首先估计帧中的人体姿势,然后通过在帧上为它们分配唯一标识号(id)来跟踪这些人体姿势。文章先引入了ICCV’17 PoseTrack Challenge的优胜者的一种算法来解决多人轨迹追踪,也就是使用MaskRcnn来进行人的检测,在视频第一帧中对每个检测到的人给一个标识ID,在之后的每一帧检测到的人都和上一帧检测到的人通过某种度量方式(计算检测框的IoU)来算一个相似度,将相似度大的作为同一个标识id,没有匹配到的分配一个新的标识id。文章作者提出的方法保留了这一方法的主要流程,并且在此之上又提出了两点改进方案:
1.除了检测网络之外,还使用光流(optical flow)法补充一些检测框,用以解决检测网络的漏检问题(比如图3©中最左边的人就没有被检测网络检测到)。
2.使用 Object Keypoint Similarity(OKS)代替检测框的IoU来计算相似度。这是因为当人的动作比较快时,用IoU可能并不合理。
接下来就是我们如何利用PaddlePaddle来复现这个simple baseline。
基于PaddlePaddle的实战
环境配置
Python == 2.7 or 3.6
PaddlePaddle >= 1.4.0
opencv-python >= 3.3
准备数据集和预训练模型
根据指导说明instruction 准备数据集
下载预训练好的ResNet-50模型
wget http://paddle-imagenet-models.bj.bcebos.com/resnet_50_model.tar然后,将它们放在此repo的目录根目录下预训练pretrained的文件夹中,使它们看起来像:
${THIS REPO ROOT}
`-- pretrained
`-- resnet_50
|-- 115
`-- data
`-- coco
|-- annotations
|-- images
`-- mpii
|-- annot
|-- images安装COCOAPI
# COCOAPI=/path/to/clone/cocoapi
git clone https://github.com/cocodataset/cocoapi.git $COCOAPI
cd $COCOAPI/PythonAPI
# if cython is not installed
pip install Cython
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python2 setup.py install --user模型验证
从 here下载在MPII数据集上训练过的Pose-ResNet-50的检查点。将其解压缩到此repo目录根目录下的checkpoints文件夹,之后可以运行:
python val.py --dataset 'mpii' --checkpoint 'checkpoints/pose-resnet50-mpii-384x384' --data_root 'data/mpii'模型训练
python train.py --dataset 'mpii'注:训练配置在lib/mpii_reader.py和lib/coco_reader.py中汇总。
模型测试
我们还支持在自定义图像上应用预先训练的模型。将图像放入此repo的目录根目录下的测试文件夹中,之后可以运行:
python test.py --checkpoint 'checkpoints/pose-resnet-50-384x384-mpii'注:如果图像中有多个人,则应首先使用Faster R-CNN,SSD等检测器先检测并裁剪出人体区域,再进行姿态估计。因为本文提到的simple-baseline是一种top-down的姿态估计方法。
结果预览
以下结果的测试环境为:CentOS 6.3,4卡Tesla K40 / P40 GPU,CUDA-9.0 / 8.0和cuDNN-7.0。
在MPII 测试集上的结果:

在COCO val2017数据集上使用人体AP为0.564检测器的COCO val2017的结果:

注:
以上结果均使用了翻转测试(flip-test)。
我们没有使用任何模型选择策略来挑选最佳模型,均直接采用最后一个checkpoint结果进行测试。
注:模型下载请去github该项目页下载:
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/human_pose_estimation
论文传送门:
Simple Baselines for Human Pose Estimation andTracking,
Bin Xiao, Haiping Wu, Yichen Weihttps://arxiv.org/abs/1804.06208
