网络(四)——对BIO、NIO、AIO的理解
目录
- 1、同步阻塞IO:BIO:
- 2、伪异步IO:
- 3、同步非阻塞IO:NIO
- Reactor模型
- 1、Reactor是什么?
- 2、为何要使用Reactor?
- 3、Reactor
- ㈠单Reactor单线程模型
- ㈡单Reactor多线程模型
- ㈢多Reactor多线程模型
- 4、异步非阻塞:AIO:
- 5、I/O模型总结:
1、同步阻塞IO:BIO:
BIO就是,每来一个客户端,服务端就会启动一个线程去连接这个客户端,并处理相应的读写操作:

对于每个客户请求,它的处理过程如下:

注意:BIO的通信是单向的,这个通道读的时候不能写,写的时候不能读
也就是它们服务端线程数和客户端连接数之间的关系是1:1的关系,这样如果连接的客户端比较多的话:
- 如果客户端和服务端的信息交互比较多(数据较大)的话:会导致服务端的线程不停的上下切换,增加了CPU的开销;
- 如果客户端和服务端的信息交互很少(数据较小)的话:那么有很多线程就阻塞在那什么都不干,浪费了资源;
并且BIO模型下的客户端连接服务端,客户端等待服务端响应是阻塞的、服务端等待客户端连接是阻塞的、连接客户端之后分配线程去处理当前的读写操作,读写操作也是阻塞的,这就造就了BIO的效率非常低,不适合高并发的场景,性能开销大;但是它很稳定,并且代码实现也很简单,适合大量数据的传输,比如传输文件;
2、伪异步IO:
对于BIO每来一个客户端就启动一个线程作了优化,就是先创建好若干个线程放在线程池里面,然后有客户端来连接了,将当前的任务丢给线程池,让线程池里面的线程去处理,它将客户端连接数和服务端启动的线程数比例降到了m:n(m >= n一般m > n);
由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机,但是这样治标不治本,伪异步i/o采用了线程池实现,避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题,但是由于它底层的通信依然采用的是同步阻塞模型,因此无法从根本上解决问题;

3、同步非阻塞IO:NIO
BIO不适合高并发的场景,于是为了解决这个问题NIO就诞生了:
NIO与BIO一个比较重要的不同,我们使用BIO的时候往往会引入多线程,每个连接一个单独的线程;而NIO则是使用单线程或者只使用少量的多线程,每个连接共用一个线程;NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。

这幅图简单理解就是,Selector它的作用就是监听和通知,它会轮询的去监听有没有关注的事件发生(对于服务端来说关注事件包括:可连接事件、读事件、写事件),如果有可连接事件发生(也就是有客户端连接),那么Selector就会通知服务端创建连接通道,并继续监听感兴趣事件,如果有可读或可写事件发生,它也会通知服务端去处理;(注意啊,服务端和Selector用的是同一个线程,也就是在轮询查看有没有感兴趣事件发生的时候服务端是阻塞的);
对于每个用户来说,其连接过程如下(NIO的通道是双向的):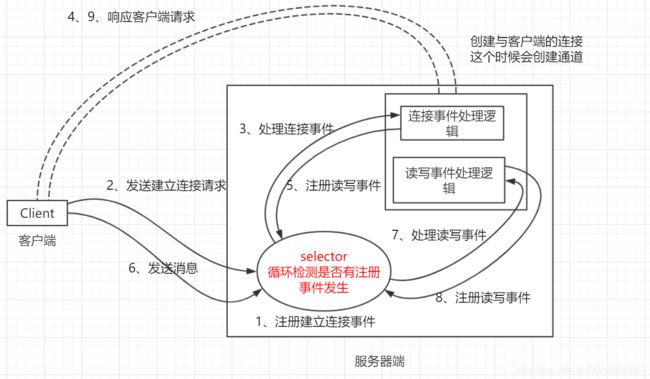
可以看出:
- Selector监听的内容包括①有没有客户端需要连接,②监听已经建立的通道里面有没有数据需要读写;
- 服务端这边只需要一个线程就可以处理所有事情了;
NIO的三个核心:
- channel:通道(双向),非阻塞,操作唯一性(只能在buffer上操作);(包括文件类FileChannel、UDP类DatagramChannel、TCP类ServerSocketChannel和SocketChannel);
- buffer:一块内存缓冲区(唯一与channel交互的方式),读写channel中的数据;
- selector:I/O就绪选择器,NIO网络编程的基础;
buffer解析:
它包括①capacity 容量②position 读写指针位置③limit 读写上限位置④mark 标记,如下图,假设有一个5个空间大小的buffer:
ByteBuffer buffer = ByteBuffer.allocate(5);

现在往其中写入3个字符:
buffer.put("acd".getBytes(Charset.forName("UTF-8")));

现在从写模式切换到读模式:
buffer.flip();

读取其中一个字符:
buffer.get();

记录当前位置,下次访问调用buffer.reset();将从mark位置为起点:
buffer.mark();

调用clear()方法将所有熟悉重置:
buffer.clear();

服务端一个线程用来处理多个客户端的连接和读写操作,效率是高了,但是如果连接的客户端非常多,达到百万千万级别的,那可能服务端一个线程就处理不过来了,这个时候有两种解决办法:
- 在服务端加入消息队列,将服务端来不及处理的任务放在消息队列里面,等服务端处理;
- 加入多线程,服务端的主线程只需要监听相关事件是否发生并处理连接事件就好,其他的读写事件如果发生了交给子线程或者丢给线程池去处理(也就是响应式编程,netty的雏形);
Reactor模型
在Unix的IO模型中有一个叫IO多路复用,在Java中,没有相应的IO模型,但有相应的编程模式,Reactor就是;
1、Reactor是什么?
关键点:
- 事件驱动(event handling);
- 可以处理一个或多个输入源(one or more inputs);
- 通过Service Handler同步的将输入事件(Event)采用多路复用分发给相应的Request Handler(多个)处理;
Reactor 的处理方式:
- 同步的等待多个事件源到达(采用select()实现);
- 将事件多路分解以及分配相应的事件服务进行处理,这个分派采用server集中处理(dispatch);
- 分解的事件以及对应的事件服务应用从分派服务中分离出去(handler);
2、为何要使用Reactor?
常见的网络服务中,如果每一个客户端都维持一个与登录服务器的连接。那么服务器将维护多个和客户端的连接以出来和客户端的contnect 、read、write ,特别是对于长链接的服务,有多少个c端,就需要在s端维护同等的IO连接。这对服务器来说是一个很大的开销;
Reactor的特点:
- 更少的资源利用,通常不需要一个客户端一个线程;
- 更少的开销,更少的上下文切换以及locking;
- 能够跟踪服务器状态;
- 能够管理handler 对event的绑定;
3、Reactor
首先定义以下三种角色:
- Reactor 将I/O事件分派给对应的Handler;
- Acceptor 处理客户端新连接,并分派请求到处理器链中;
- Handlers 执行非阻塞读/写 任务;
㈠单Reactor单线程模型

/**
* 等待事件到来,分发事件处理
*/
class Reactor implements Runnable {
private Reactor() throws Exception {
SelectionKey sk =
serverSocket.register(selector,
SelectionKey.OP_ACCEPT);
// attach Acceptor 处理新连接
sk.attach(new Acceptor());
}
public void run() {
try {
while (!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
it.remove();
//分发事件处理
dispatch((SelectionKey) (it.next()));
}
}
} catch (IOException ex) {
//do something
}
}
void dispatch(SelectionKey k) {
// 若是连接事件获取是acceptor
// 若是IO读写事件获取是handler
Runnable runnable = (Runnable) (k.attachment());
if (runnable != null) {
runnable.run();
}
}
}
/**
* 连接事件就绪,处理连接事件
*/
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
new Handler(c, selector);
}
} catch (Exception e) {
}
}
}
这是最基本的单Reactor单线程模型。其中Reactor线程,负责多路分离套接字,有新连接到来触发connect 事件之后,交由Acceptor进行处理,有IO读写事件之后交给hanlder 处理。
Acceptor主要任务就是构建handler ,在获取到和client相关的SocketChannel之后 ,绑定到相应的hanlder上,对应的SocketChannel有读写事件之后,基于racotor 分发,hanlder就可以处理了(所有的IO事件都绑定到selector上,有Reactor分发)。
该模型 适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
㈡单Reactor多线程模型

/**
* 多线程处理读写业务逻辑
*/
class MultiThreadHandler implements Runnable {
public static final int READING = 0, WRITING = 1;
int state;
final SocketChannel socket;
final SelectionKey sk;
//多线程处理业务逻辑
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public MultiThreadHandler(SocketChannel socket, Selector sl) throws Exception {
this.state = READING;
this.socket = socket;
sk = socket.register(selector, SelectionKey.OP_READ);
sk.attach(this);
socket.configureBlocking(false);
}
@Override
public void run() {
if (state == READING) {
read();
} else if (state == WRITING) {
write();
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理写事件
sk.interestOps(SelectionKey.OP_WRITE);
this.state = WRITING;
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理读事件
sk.interestOps(SelectionKey.OP_READ);
this.state = READING;
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}
相对于第一种单线程的模式来说,在处理业务逻辑,也就是获取到IO的读写事件之后,交由线程池来处理,这样可以减小主reactor的性能开销,从而更专注的做事件分发工作了,从而提升整个应用的吞吐。
㈢多Reactor多线程模型

第三种模型比起第二种模型,是将Reactor分成两部分:
- mainReactor负责监听server socket,用来处理新连接的建立,将建立的socketChannel指定注册给subReactor。
- subReactor维护自己的selector, 基于mainReactor 注册的socketChannel多路分离IO读写事件,读写网 络数据,对业务处理的功能,另其扔给worker线程池来完成。
/**
* 多work 连接事件Acceptor,处理连接事件
*/
class MultiWorkThreadAcceptor implements Runnable {
// cpu线程数相同多work线程
int workCount =Runtime.getRuntime().availableProcessors();
SubReactor[] workThreadHandlers = new SubReactor[workCount];
volatile int nextHandler = 0;
public MultiWorkThreadAcceptor() {
this.init();
}
public void init() {
nextHandler = 0;
for (int i = 0; i < workThreadHandlers.length; i++) {
try {
workThreadHandlers[i] = new SubReactor();
} catch (Exception e) {
}
}
}
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
synchronized (c) {
// 顺序获取SubReactor,然后注册channel
SubReactor work = workThreadHandlers[nextHandler];
work.registerChannel(c);
nextHandler++;
if (nextHandler >= workThreadHandlers.length) {
nextHandler = 0;
}
}
}
} catch (Exception e) {
}
}
}
/**
* 多work线程处理读写业务逻辑
*/
class SubReactor implements Runnable {
final Selector mySelector;
//多线程处理业务逻辑
int workCount =Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(workCount);
public SubReactor() throws Exception {
// 每个SubReactor 一个selector
this.mySelector = SelectorProvider.provider().openSelector();
}
/**
* 注册chanel
*
* @param sc
* @throws Exception
*/
public void registerChannel(SocketChannel sc) throws Exception {
sc.register(mySelector, SelectionKey.OP_READ | SelectionKey.OP_CONNECT);
}
@Override
public void run() {
while (true) {
try {
//每个SubReactor 自己做事件分派处理读写事件
selector.select();
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
read();
} else if (key.isWritable()) {
write();
}
}
} catch (Exception e) {
}
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}
第三种模型中,我们可以看到,mainReactor 主要是用来处理网络IO 连接建立操作,通常一个线程就可以处理,而subReactor主要做和建立起来的socket做数据交互和事件业务处理操作,它的个数上一般是和CPU个数等同,每个subReactor一个线程来处理。
此种模型中,每个模块的工作更加专一,耦合度更低,性能和稳定性也大量的提升,支持的可并发客户端数量可达到上百万级别。
关于此种模型的应用,目前有很多优秀的矿建已经在应用了,比如mina 和netty 等。上述中的第三种形式的变种,也 是Netty NIO的默认模式。
4、异步非阻塞:AIO:
NIO是需要Selector自己不停的去轮询查看自己感兴趣的事件有没有发生,那么如果感兴趣的事件发生了,操作系统能不能来通知我呢,这就是AIO的思想,并且如果感兴趣的事件发生了,它还通过回掉函数让操作系统都把事件给处理了(也就是把感兴趣的事件让操作系统代为监听一下,并且把事件发生之后的处理逻辑的引用一并送给操作系统,事件一旦发生,操作系统就用给他的引用调用处理逻辑处理该事件,一切做完之后通知一下调用端,我给你弄好了);
在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了,在Linux上,AIO是对NIO的封装,底层还是NIO是实现的(这就是netty这些框架为什么是基于NIO是实现的,因为在Linux上这两底层都一样的,在windows上AIO的底层就和NIO不一样了,在windows上AIO的效率要高于NIO,不过服务器基本都是部署在Linux上的,你再高没用);
由于NIO的读写过程依然在应用线程里完成,所以对于那些读写过程时间长的,NIO就不太适合。而AIO的读写过程完成后才被通知,所以AIO能够胜任那些重量级,读写过程长的任务。
5、I/O模型总结:
| IO模型 | JDK版本 | 特性 | 描述 |
|---|---|---|---|
| BIO | 所有 | 同步阻塞I/O | 该模式下为每个请求创建一个线程,对性能开销大,不适合高并发场景,优点是稳定,适合连接数目小而且固定的架构 |
| NIO | 大于JDK 1.4 | 同步非阻塞I/O | 该模式基于多路复用选择器监测连接状态再通知线程处理,从而达到非阻塞的目的,比传统的BIO能更好的支持高并发性能 |
| AIO | 大于JDK 1.7 | 异步非阻塞I/O | 它与NIO不同在于它不需要多路复用选择器,而是请求处理线程执行完成进行回调通知,以继续执行后续操作 |