可用性和可靠性的区别
可用性和可靠性区别简介
可用性(Availability)是关于系统可供使用时间的描述,以丢失的时间为驱动(Be Driven
By Lost Time)。可靠性(Reliability)是关于系统无失效时间间隔的描述,以发生的失效个数为驱动(Be Driven By Number of Failure)。两者都用百分数的形式来表示。
在一般情况下,可用性不等于可靠性,只有在没有宕机和失效发生的理想状态下,两者才
是一样的。
1可用性
可用性最简单的表示形式是:
A = Uptime / ( Uptime + Downtime )
如果我们要讨论一年的可用性,公式的分母就必须至少是8760小时。固有可用性从设计的
角度来看待可用性:Ai = MTBF / ( MTBF + MTTR )MTBF,mean time between failureMTTR,mean time to repair 或者
Ai = MTTF / ( MTTF + MTTR )MTTF,mean time to failMTTR,mean time to replace
从上述公式可以看出。如果平均失效间隔时间(MTBF,mean time between failure)或平均
失效前时间(MTTF,mean time to fail)远大于平均修复时间(MTTR,mean time to repair)或者平均恢复时间(MTTR,mean time to replace),那么可用性将很高。同样的,如果平均修复时间或平均恢复时间很小,那么可用性将很高。如果可靠性下降(比如MTTF变小),那么就需要提高可维护性(比如减小MTTR)才能达到同样的可用性。当然对于一定的可用性,可靠性增长了,可维护性也就不是那么重要了。所以我们可以在可靠性和可维护性之间做出平衡,来达到同样的可用性,但是这两个约束条件必须同步改进。 如果系统操作中没有人为疏忽的发生,Ai 是我们可以观察到的最大的可用性了。
在实际环境中,我们采用使用可用性公式。使用可用性公式考虑了人为影响的因素。 A0 = MTBM/ ( MTBM + MDT )
平均维护间隔时间(MTBM,mean time between maintenance)包括所有纠正的和预防行为
的时间(相比 MTBF 只关心失效发生时的维护更切合实际应用)。平均宕机时间(MDT,meandown time)包括所有跟宕机有关的纠正维护(CM,corrective maintenance)时间,MDT中包括了:
(1)修复失效过程中如路途、材料等方面造成的延迟时间(相比 MTTR 只关注失效修复
时间更切合实际应用)
(2)为了防止宕机等失效而做的预防性维护操作(PM,preventive maintenance)时间因为在实际操作中总会有一些人为的延迟和疏忽。因此基于以上两点,A0 在数值上比 Ai 要
小,但更接近系统实际的可用性。
下面是一个不同可用性的系统在一年中由于失效而产生的不可工作的时间的例子。具体数
据见下表(1 年 = 365天*24小时 = 8760 小时,可用性 A = Uptime / ( Uptime + Downtime )):

可靠性最简单的表达式可以用指数分布来表示。它表述了随机失效。
R = e^[-(λ*t)] = e^[-(t/Θ)]
其中:
t = 运行时间Mission Time (1天,1 周,1月,1年等,可根据要求确定)λ = 失效率 Failure Rate
Θ = 1/λ = Mean Time To Failure 或 Mean Time Between Failures
注意,可靠性必须以任务时间作为一个参数去计算结果,当你在听取某产品的可靠性宣传
时优要关注,如果时间很短,则不合理。当你置疑失效模式,更要关注指数分布的表达式,因为:
(1)利用指数分布估算可靠性并不需要太多的信息作为输入(2)它可以充分代表由多种失效模式和机制组成的复杂系统(3)你几乎可以不必跟他人解释其复杂性。
当MTTF 或 MTBF 或 MTBM与运行时间(Mission Timw)相比比较长时,你可用可靠性
(Reliability)去度量(如不发生失效的可能性);当MTTF 或 MTBF 或 MTBM跟运行时间相比比较短时,你可用不可靠性(Unreliability)去度量(如发生失效的可能性)。
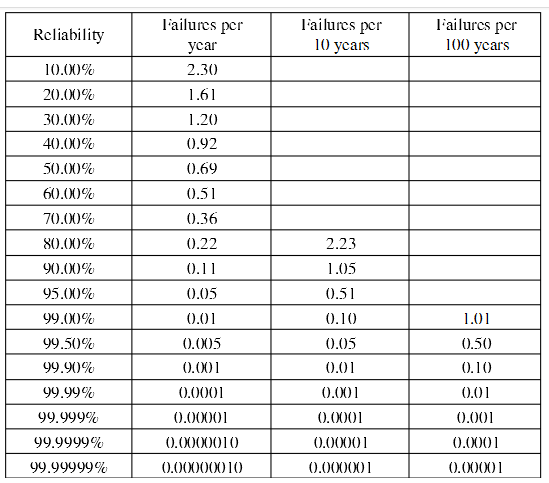
下面是一个不同可靠性的系统在不同运行时间中出现的失效个数的例子。具体数据见下表
(1 年 = 365天*24小时 = 8760 小时):