python+Xpath爬取英文新闻并生成文档词频矩阵
详情见我的github:https://github.com/Snowing-ST/Statistical-Case-Studies/tree/master/Lab3%20English%20Text%20Processing
1.爬取新华网Business - Finance类别的新闻url
由于新华网是动态网站,不能直接爬取,所以通过检查找到实际保存新闻摘要列表的网址,里面的信息均用json格式保存。
import requests
import json
from selenium import webdriver
from lxml import etree
import time
import os
import pandas as pd
import numpy as np
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer #词形变化
from sklearn.feature_extraction.text import CountVectorizer
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.933.400 QQBrowser/9.4.8699.400',
}
url = 'http://qc.wa.news.cn/nodeart/list?nid=11143416&pgnum=1&cnt=50&tp=1&orderby=1?callback=jQuery111307913713753952403_1522322711817&_=1522322711818'
data = requests.get(url, headers=headers)
data.encoding
html=data.content
dic_html = html[42:(len(html)-2)] #提取json文本
url_num = len(json.loads(dic_html)["data"]["list"]);url_num #50条url
def geturls(i):
return json.loads(dic_html)["data"]["list"][i]["LinkUrl"]
new_urls = map(geturls,range(url_num))
for i in new_urls[:10]:
print i 
2.对每个url,用Xpath爬取新闻标题及内容
因为不同的新闻页面,结点可能有轻微不同,加了一堆了的try except保证程序不报错。
爬到的每条新闻保存在每个txt中.
driver = webdriver.PhantomJS(executable_path=r'C:/Users/yourname/Downloads/phantomjs-2.1.1-windows/bin/phantomjs.exe')
time.sleep(5)
i=0
for url in new_urls:
i=i+1
driver.get(url)
time.sleep(1)
page = driver.page_source
selector = etree.HTML(page)
try:
text = "\n".join(selector.xpath('/html/body/div[5]/div[1]/div[5]/p/text()')).strip()
if text=="":
text = "".join(selector.xpath('//*[@id="Zoom"]//text()')).strip()
if text=="":
text = "\n".join(selector.xpath('/html/body/div[5]/div[5]/p/text()')).strip()
except:
text = ""
try:
title = selector.xpath("/html/body/div[5]/div[1]/h1/text()")[0].strip()
except:
try:
title = selector.xpath("/html/body/div[5]/h1/text()")[0].strip()
except:
try:
title = selector.xpath("/html/body/div[3]/table[2]/tbody/tr/td[2]/table[1]/tbody/tr/td/table[1]/tbody/tr/td/table[2]/tbody/tr[1]/td/text()")[0].strip()
except:
title = "none"
if (text!="") & (title!="none"):
try:
with open(title+".txt","w") as f:
f.write(text)
print i #第几条url写出来了
except:
pass
3.批量读取新闻文本txt
批量保存在dataframe中,一列为标题,一列为内容
def batch_read_txt(filepath):
filenames = os.listdir(filepath) #获取当前路径下的文件名,返回List
l = len(filenames)
title = [s.split(".")[0] for s in filenames]
news = pd.DataFrame({"title":title,"content":np.zeros(l)})
for i in range(l):
f = filenames[i]
full_filenames=os.path.join(filepath,f) #将文件命加入到当前文件路径后面
with open(full_filenames,"r") as f2:
text = "".join(f2.readlines())
news["content"][i] = text.split(" -- ")[1]
return news
os.chdir("./xinhua_news/")
news = batch_read_txt(os.getcwd())
news.head(5)
4.文本预处理
使用python的re模块和nltk去除新闻文本中的数字、非英文字符、停用词、转换成小写、词形还原
wnl = WordNetLemmatizer()
def clean_text(text):
text = text.encode("utf-8").decode("utf-8")
text = re.sub("\d","",text)
text_seg = [re.sub(u'\W', "", i) for i in nltk.word_tokenize(text)]
space_len = text_seg.count(u"")
for i in range(space_len):
text_seg.remove(u'')
filtered = [w.lower() for w in text_seg if w not in stopwords.words('english') and 3<=len(w)]
lemmatized= [wnl.lemmatize(w) for w in filtered] #词形还原
return " ".join(lemmatized)
news["clean_text"] = map(clean_text,news["content"])
news.head(5)
5.生成文本词频矩阵
以scipy中稀疏矩阵的形式存储
content = [t for t in news["clean_text"]]
vectorizer=CountVectorizer(stop_words='english')
count_word = vectorizer.fit_transform(content)
count_word.shape#41篇文档, 616个词只选择词频大于5的词
vectorizer=CountVectorizer(stop_words='english',min_df=5)
count_word = vectorizer.fit_transform(content)
count_word.shape#41篇文档, 86个词生成文档词频矩阵的函数
def get_word_tf_mat(sparce_mat, feature_names):
arr = sparce_mat.toarray().T
word_tf = pd.DataFrame(arr,index = vectorizer.get_feature_names())
word_tf["tf"] = np.sum(arr,axis=1)
word_tf = word_tf.sort_values(by="tf",ascending=False)
return word_tf.T
word_tf = get_word_tf_mat(count_word, vectorizer.get_feature_names())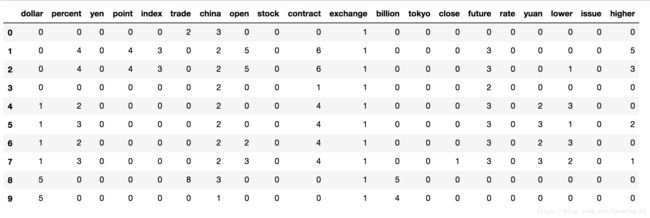
输出前20个高频词
print data.ix[41,:20] 6.根据词频绘制词云图
使用wordcloud包根据词频统计画词云图,当然也可以使用各种在线词云图,更好看。推荐一个在线词云图网站tagxedo
import wordcloud
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import PIL.Image as Image
tf = {data.columns[i]: data.ix[41,i] for i in range(len(data))} #词频统计词典
coloring = np.array(Image.open("E:/graduate/class/Statistical Case Studies/homework3/pictures/jinbi.jpg")) #图片
my_wordcloud = WordCloud(background_color="white", max_words=2000,
mask=coloring, max_font_size=60, random_state=42, scale=2,
font_path=os.environ.get("FONT_PATH", "C:/Windows/Fonts/simfang.ttf"))
my_wordcloud.fit_words(tf)
image_colors = ImageColorGenerator(coloring)
plt.figure(figsize=(18.5,10.5))
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.xticks([]),plt.yticks([]) #隐藏坐标线
plt.axis("off")
plt.imshow(my_wordcloud)
plt.show()