机器学习实战之KNN算法(代码)详解
目录
- 机器学习实战之KNN算法(代码)详解
- KNN算法一般流程
- 算法的一般操作
- 创建数据集
- KNN算法
- 代码详解
- 代码测试
- 运行实现:
机器学习实战之KNN算法(代码)详解
KNN算法一般流程
(1)收集数据:可以使用任何方法
(2)准备数据:距离计算所需要的数值,最好是结构化数据格式
(3)分析数据:可以使用任何方法
(4)训练算法:此步骤不适合KNN
(5)测试算法:计算错误率
(6)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行KNN判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
算法的一般操作
对未知类别属性的数据集中的每个点一次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点
(4)确定前K个点所在的类别的出现频率
(5)返回前K个点出现频率最高的类别作为当前点的预测分类
创建数据集
from numpy import *
import operator
def createDataset():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
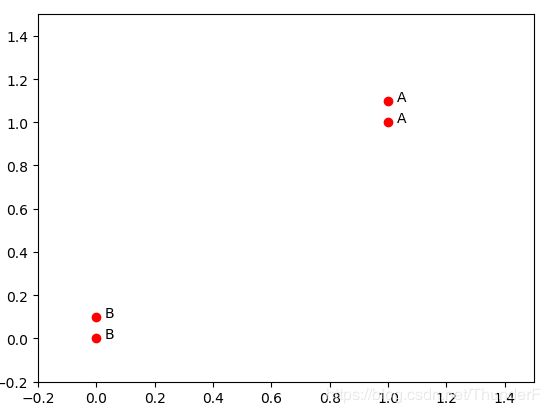
带有四个数据点的简单例子.
KNN算法
def classify0(inX, dataSet, labels, k):
#计算出欧氏距离数组
dataSetSize = dataSet.shape[0] #获取数据集中数据的个数
diffMat = tile(inX,(dataSetSize,1))-dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances**0.5
sortedDisiIndicies = distances.argsort()
#选择k个距离最小的点
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDisiIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
#排序:将classCount字典分分解为元组列表,使用运算符模块的itemgetter方法,按照第二个元素的次序对元组进行排序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0]
代码详解
1、 diffMat = tile(inX,(dataSetSize,1))-dataSet
构造出元素为[inXx - Ax ,inXy - Ay]的数组
tile(A, reps)函数:
构造一个把A重复reps遍的数组
Examples
-------------------------------------------------------------
>>> a = np.array([0, 1, 2])
>>> np.tile(a, 2)
array([0, 1, 2, 0, 1, 2])
>>> np.tile(a, (2, 2))
array([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]])
>>> np.tile(a, (2, 1, 2))
array([[[0, 1, 2, 0, 1, 2]],
[[0, 1, 2, 0, 1, 2]]])
>>> b = np.array([[1, 2], [3, 4]])
>>> np.tile(b, 2)
array([[1, 2, 1, 2],
[3, 4, 3, 4]])
>>> np.tile(b, (2, 1))
array([[1, 2],
[3, 4],
[1, 2],
[3, 4]])
>>> c = np.array([1,2,3,4])
>>> np.tile(c,(4,1))
array([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])
-----------------------------------------------------------
2、 sqDistances = sqDiffMat.sum(axis = 1) #计算每行的和
sum函数:
当axis=0,按列计算和;当axis=1,按行计算和
3、 sortedDisiIndicies = distances.argsort()
argsort函数:
Returns the indices that would sort this array.(排好序后返回其索引,不改变原数组元素排列顺序)
4、 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #统计k个数据里每个标签的频率
get函数:
dict.get(key, default=None)
参数
key – 字典中要查找的键。
default – 如果指定键的值不存在时,返回该默认值值。
返回值
返回指定键的值,如果值不在字典中返回默认值None。
5、 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse = True)
sorted函数:
sorted()函数对所有可迭代的对象进行排序操作。
sorted(iterable[,cmp[,key[,reverse]]])
iterable是可迭代对象;
cmp是比较函数。
key为一个函数或者lambda函数。所以itemgetter可以用来当key的参数
reverse为排序方向,reverse=True降序,reverse=False升序。
itemgetter函数:
>>>itemgetter(1)([3,4,5,2,7,8])
> 4
>>>itemgetter(4)([3,4,5,2,7,8])
> 7
>>>itemgetter(1,3,5)([3,4,5,2,7,8])
>(4,2,8)
operator.itemgetter函数
operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为一些序号。看下面的例子
a = [1,2,3]
>>> b=operator.itemgetter(1) #定义函数b,获取对象的第1个域的值
>>> b(a)
2
>>> b=operator.itemgetter(1,0) #定义函数b,获取对象的第1个域和第0个的值
>>> b(a)
(2, 1)
要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。
代码测试
if __name__ == "__main__":
group, labels=createDataset()
print(classify0([0,0], group, labels, 3))
运行实现: