Hadoop HA脑裂的疑惑
Hadoop HA脑裂的疑惑
我看了很多帖子,大多数都是如下吗的这段描述,感觉都是互相复制的。我阅读完后,有以下几点疑惑,希望大佬给指点解惑。多谢~
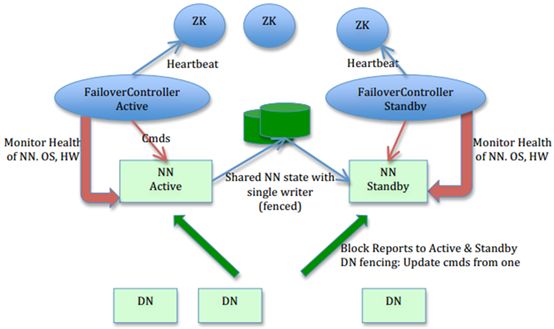
社区的NN HA包括两个NN,主(active)与备(standby),ZKFC,ZK,share editlog。流程:集群启动后一个NN处于active状态,并提供服务,处理客户端和datanode的请求,并把editlog写到本地和share editlog(可以是NFS,QJM等)中。另外一个NN处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与active的状态同步。为了实现standby在sctive挂掉后迅速提供服务,需要DN同时向两个NN汇报,使得Stadnby保存block to datanode信息,因为NN启动中最费时的工作是处理所有datanode的blockreport。为了实现热备,增加FailoverController和ZK,FailoverController与ZK通信,通过ZK选主,FailoverController通过RPC让NN转换为active或standby。 2.关键问题: (1) 保持NN的状态同步,通过standby周期性获取editlog,DN同时想standby发送blockreport。 (2) 防止脑裂共享存储的fencing (我英文不行,这个fencing该怎么理解?查询了翻译软件,仍然难题理解,该怎么翻译这个词?) ,确保只有一个NN能写成功。使用QJM实现fencing,下文叙述原理。datanode的fencing。确保只有一个NN能命令DN。HDFS-1972 (这个又是什么?1972是什么?一本书名?) 中详细描述了DN如何实现fencing (a) 每个NN改变状态的时候,向DN发送自己的状态和一个序列号。 (b) DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回是认为该NN为新的active。 (c) 如果这时原来的active(比如GC)恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。 (基于abc三点描述,我有一个疑问:意思是NN和DN心跳检测通讯的时候,每次都携带这个序列号吗? 假设我原先active NN的序号为1,standby NN的序列号此时也是1吗?应该是比1要小吧?不然两个NN都是1,DN也不知道哪个序列号大呀,一样大的,DN听谁的?所以我感觉应该是比1要小,我就暂时将standby NNd的序号标记为0。 现在active NN的序号为1,standby NN的序号为0,1>0, DN听从序号为1的NN的命令,也就是active NN的命令。 okay, 继续,那么此时active NN挂了,根据上面的描述,standby NN会代替active NN,并且返回给DN一个更大的序列号?那是几?比1要大,那是2?暂标记为2吧。那standby NN怎么知道要比1大呢?那他得知道active NN的序列号原先为1,问题:它是怎么知道的? 避免脑裂的关键来了:DN接到一个序号大于原先的1的NN的命令,也就是standby NN,那么DN认为此时的standby NN为acitve的NN。没问题,我能理解。但是如果原先挂掉的active NN恢复了,他的序列号还是原来的1,那就不能命令DN来干活了。也能理解。问题:如果standby的NN 挂掉了,此时该怎么办?active NN将自己原来的序列号1改变为比standby NN序列号2更大的?改为3吗?这两个NN之间是如何更改他们的序列号的呢?) (d) 特别需要注意的一点是,上述实现还不够完善,HDFS-1972中还解决了一些有可能导致误删除block的隐患,在failover后,active在DN汇报所有删除报告前不应该删除任何block。 客户端fencing,确保只有一个NN能响应客户端请求。让访问standby nn的客户端直接失败。在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间。
2
社区的NN HA包括两个NN,主(active)与备(standby),ZKFC,ZK,share editlog。流程:集群启动后一个NN处于active状态,并提供服务,处理客户端和datanode的请求,并把editlog写到本地和share editlog(可以是NFS,QJM等)中。另外一个NN处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与active的状态同步。为了实现standby在sctive挂掉后迅速提供服务,需要DN同时向两个NN汇报,使得Stadnby保存block to datanode信息,因为NN启动中最费时的工作是处理所有datanode的blockreport。为了实现热备,增加FailoverController和ZK,FailoverController与ZK通信,通过ZK选主,FailoverController通过RPC让NN转换为active或standby。 2.关键问题: (1) 保持NN的状态同步,通过standby周期性获取editlog,DN同时想standby发送blockreport。 (2) 防止脑裂共享存储的fencing (我英文不行,这个fencing该怎么理解?查询了翻译软件,仍然难题理解,该怎么翻译这个词?) ,确保只有一个NN能写成功。使用QJM实现fencing,下文叙述原理。datanode的fencing。确保只有一个NN能命令DN。HDFS-1972 (这个又是什么?1972是什么?一本书名?) 中详细描述了DN如何实现fencing (a) 每个NN改变状态的时候,向DN发送自己的状态和一个序列号。 (b) DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回是认为该NN为新的active。 (c) 如果这时原来的active(比如GC)恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。 (基于abc三点描述,我有一个疑问:意思是NN和DN心跳检测通讯的时候,每次都携带这个序列号吗? 假设我原先active NN的序号为1,standby NN的序列号此时也是1吗?应该是比1要小吧?不然两个NN都是1,DN也不知道哪个序列号大呀,一样大的,DN听谁的?所以我感觉应该是比1要小,我就暂时将standby NNd的序号标记为0。 现在active NN的序号为1,standby NN的序号为0,1>0, DN听从序号为1的NN的命令,也就是active NN的命令。 okay, 继续,那么此时active NN挂了,根据上面的描述,standby NN会代替active NN,并且返回给DN一个更大的序列号?那是几?比1要大,那是2?暂标记为2吧。那standby NN怎么知道要比1大呢?那他得知道active NN的序列号原先为1,问题:它是怎么知道的? 避免脑裂的关键来了:DN接到一个序号大于原先的1的NN的命令,也就是standby NN,那么DN认为此时的standby NN为acitve的NN。没问题,我能理解。但是如果原先挂掉的active NN恢复了,他的序列号还是原来的1,那就不能命令DN来干活了。也能理解。问题:如果standby的NN 挂掉了,此时该怎么办?active NN将自己原来的序列号1改变为比standby NN序列号2更大的?改为3吗?这两个NN之间是如何更改他们的序列号的呢?) (d) 特别需要注意的一点是,上述实现还不够完善,HDFS-1972中还解决了一些有可能导致误删除block的隐患,在failover后,active在DN汇报所有删除报告前不应该删除任何block。 客户端fencing,确保只有一个NN能响应客户端请求。让访问standby nn的客户端直接失败。在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间。
全部回复
只看楼主 倒序排列![]() nextuser LV42楼
nextuser LV42楼
首先第一个问题:
fencing,这里可以理解为 隔离或则 隔离机制
HDFS-1972是对hdfs修改的某些bug或则增加的功能,里面有详细说明。具体网址如下
https://issues.apache.org/jira/browse/HDFS-1972

(2) 防止脑裂
共享存储的fencing(我英文不行,这个fencing该怎么理解?查询了翻译软件,仍然难题理解,该怎么翻译这个词?),确保只有一个NN能写成功。使用QJM实现fencing,下文叙述原理。
datanode的fencing。确保只有一个NN能命令DN。HDFS-1972(这个又是什么?1972是什么?一本书名?)中详细描述了DN如何实现fencing
fencing,这里可以理解为 隔离或则 隔离机制
HDFS-1972是对hdfs修改的某些bug或则增加的功能,里面有详细说明。具体网址如下
https://issues.apache.org/jira/browse/HDFS-1972
1 小时前
![]() nextuser LV43楼
nextuser LV43楼
这个问题专门下载了相关文档
其中下面一个比较重要
根据英文文档,以下总结:
并不是文章中所说的namenode和DataNode的通信,相信使用的算法也是 ZAB 和Paxos算法。对我有所启发。
那就是如果journal node相应,那么QJM的数字就会+1,也就是说,如果DataNode活着,那么namenode的序列号就可以自增。直到大于DataNode,这样命令就可以执行了。而且这个相信时间不会太长。
启发相关内容:
重点研究了下面内容
其中下面一个比较重要
根据英文文档,以下总结:
并不是文章中所说的namenode和DataNode的通信,相信使用的算法也是 ZAB 和Paxos算法。对我有所启发。
那就是如果journal node相应,那么QJM的数字就会+1,也就是说,如果DataNode活着,那么namenode的序列号就可以自增。直到大于DataNode,这样命令就可以执行了。而且这个相信时间不会太长。
启发相关内容:
重点研究了下面内容
Fencing writers
In order to satisfy the fencing requirement without requiring custom hardware, we require the ability to
guarantee that a previously active writer can commit no more edits after a certain point. In this design, we
introduce the concept of epoch numbers, similar to those found in much distributed systems literature (eg
Paxos, ZAB, etc). In our system, epoch numbers have the following properties:
When a writer becomes active, it is assigned an epoch number.
Each epoch number is unique. No two writers have the same epoch number.
Epoch numbers dene a total order of writers. For any two writers, epoch numbers dene a relation
such that one writer can be said to be strictly later than the other if its epoch number is higher.
We utilize the epoch numbers as follows:
Before making any mutations to the edit logs, a QJM must rst be assigned an epoch number.
The QJM sends its epoch number to all of the JNs in a message newEpoch(N). It may not proceed
with this epoch number unless a quorum of JournalNodes responds with an indication of success.2
When a JN responds to such a request, it persistently records this epoch number in a variable
lastPromisedEpoch which is also written durably (fsynced) to local storage.
Any RPC that requests a mutation to the edit logs (eg logEdits(), startLogSegment(), etc. must
contain the requester's epoch number.
Before taking action in response to any RPC other than newEpoch(), the JournalNode checks the re-
quester's epoch number against its lastPromisedEpoch variable. If the requester's epoch is lower, then
it will reject the request. If the requester's epoch is higher, then it will update its own lastPromisedEpoch.
This allows a JN to update its lastPromisedEpoch even if it was down at the time that the new writer
became active.
This policy ensures that, once a QJM has received a successful response to its newEpoch(N) RPC, then
no QJM with an epoch number less than N will be able to mutate edit logs on a quorum of nodes. We defer
to the literature for a formal proof, but this is intuitively true since all possible quorums overlap by at least
one JN. So, any future RPC made by the earlier QJM will be unable to attain any quorum which does not
overlap with the quorum that responded to newEpoch(N).
In order to satisfy the fencing requirement without requiring custom hardware, we require the ability to
guarantee that a previously active writer can commit no more edits after a certain point. In this design, we
introduce the concept of epoch numbers, similar to those found in much distributed systems literature (eg
Paxos, ZAB, etc). In our system, epoch numbers have the following properties:
When a writer becomes active, it is assigned an epoch number.
Each epoch number is unique. No two writers have the same epoch number.
Epoch numbers dene a total order of writers. For any two writers, epoch numbers dene a relation
such that one writer can be said to be strictly later than the other if its epoch number is higher.
We utilize the epoch numbers as follows:
Before making any mutations to the edit logs, a QJM must rst be assigned an epoch number.
The QJM sends its epoch number to all of the JNs in a message newEpoch(N). It may not proceed
with this epoch number unless a quorum of JournalNodes responds with an indication of success.2
When a JN responds to such a request, it persistently records this epoch number in a variable
lastPromisedEpoch which is also written durably (fsynced) to local storage.
Any RPC that requests a mutation to the edit logs (eg logEdits(), startLogSegment(), etc. must
contain the requester's epoch number.
Before taking action in response to any RPC other than newEpoch(), the JournalNode checks the re-
quester's epoch number against its lastPromisedEpoch variable. If the requester's epoch is lower, then
it will reject the request. If the requester's epoch is higher, then it will update its own lastPromisedEpoch.
This allows a JN to update its lastPromisedEpoch even if it was down at the time that the new writer
became active.
This policy ensures that, once a QJM has received a successful response to its newEpoch(N) RPC, then
no QJM with an epoch number less than N will be able to mutate edit logs on a quorum of nodes. We defer
to the literature for a formal proof, but this is intuitively true since all possible quorums overlap by at least
one JN. So, any future RPC made by the earlier QJM will be unable to attain any quorum which does not
overlap with the quorum that responded to newEpoch(N).
Generating epoch numbers
In the above section, we did not explain how the QJM determines an epoch number which satises the
required properties. Our solution to this problem borrows from ZAB and Paxos. We use the following
algorithm:
1. The QJM sends a message getJournalState() to the JNs. Each JN responds with its current value
for lastPromisedEpoch.
2. Upon receiving a response from a quorum of JNs, the QJM calculates the maximum value seen, and
then increments it by 1. This value is the proposedEpoch. 3
3. It sends a message newEpoch(proposedEpoch) to all of the JNs. Each JN atomically compares this
proposal to its current value for lastPromisedEpoch. If the new proposal is greater than the stored
value, then it stores the proposal as its new lastPromisedEpoch and returns a success code. Otherwise,
it returns a failure.
4. If the QJM receives a success code from a quorum of JNs, then it sets its epoch number to the proposed
epoch. Otherwise, it aborts the attempt to become the active writer by throwing an IOException. This
will be handled by the NameNode in the same fashion as a failure to write to an NFS mount { if the
QJM is being used as a shared edits volume, it will cause the NN to abort.
Again, we defer a formal proof to the literature. A rough explanation, however, is as follows: no two
nodes can successfully complete step 4 for the same epoch number, since all possible quorums overlap by at
least one node. Since no node will return success twice for the same epoch number, the overlapping node
will prevent one of the two proposers from succeeding.
Following is an annotated log captured from the uncontended case:
In the above section, we did not explain how the QJM determines an epoch number which satises the
required properties. Our solution to this problem borrows from ZAB and Paxos. We use the following
algorithm:
1. The QJM sends a message getJournalState() to the JNs. Each JN responds with its current value
for lastPromisedEpoch.
2. Upon receiving a response from a quorum of JNs, the QJM calculates the maximum value seen, and
then increments it by 1. This value is the proposedEpoch. 3
3. It sends a message newEpoch(proposedEpoch) to all of the JNs. Each JN atomically compares this
proposal to its current value for lastPromisedEpoch. If the new proposal is greater than the stored
value, then it stores the proposal as its new lastPromisedEpoch and returns a success code. Otherwise,
it returns a failure.
4. If the QJM receives a success code from a quorum of JNs, then it sets its epoch number to the proposed
epoch. Otherwise, it aborts the attempt to become the active writer by throwing an IOException. This
will be handled by the NameNode in the same fashion as a failure to write to an NFS mount { if the
QJM is being used as a shared edits volume, it will cause the NN to abort.
Again, we defer a formal proof to the literature. A rough explanation, however, is as follows: no two
nodes can successfully complete step 4 for the same epoch number, since all possible quorums overlap by at
least one node. Since no node will return success twice for the same epoch number, the overlapping node
will prevent one of the two proposers from succeeding.
Following is an annotated log captured from the uncontended case:
转:
http://wsq.discuz.com/?siteid=264104844&c=index&a=viewthread&tid=24419&source=pcscan