一步一步带你训练自己的SSD检测算法
目录
- 一、前言
- 二、实现细节
- 1、前提条件
- 2、数据标注
- 2.1 Labelme
- 2.1.1 工具特点简介
- 2.1.2 工具安装
- 2.1.3 工具使用简介
- 2.2 LabelImg
- 2.2.1 工具安装
- 2.2.2 工具使用简介
- 3、标签预处理
- 3.1 PASCAL VOC数据集格式详解
- 3.2 构造新的PASCAL VOC数据集
- 3.3 COCO数据集格式详解
- 3.4 构造新的COCO数据集
- 4、搭建SSD运行环境
- 5、修改代码训练网络
- 5.1 代码架构详解
- 5.2 修改网络配置参数
- 5.3 修改VOC类别参数
- 5.4 下载模型
- 5.5 训练模型
- 5.6 Loss和Accuracy可视化
- 5.7 模型测试和效果分析
- 6、SSD性能改进
- 7、Pytorch模型加速
- 三、总结
- 参考资料
- 注意事项
一、前言
随着深度学习的快速发展,越来越多的场景都开始应用这么技术,但是当前的深度学习还是具有一些门槛,厉害的大佬们都在设计各种各样的网络,发各种各样的顶会论文,他们关注的是算法的设计。然而在现实场景中,对于很多人而言,他们更多的是关注如何去使用这个算法,比如我如何快速的使用现有的工具训练一个满足自己需求的模型,当前网上浅显易懂的带小白构建自己的模型的教程太少了,我决定来弥补一下这个空缺,为自己为大家做一点点小贡献。本文专注于使用SSD网络从头训练自己的数据集,我们详细讲解里面的细节,具体的内容如下所示感兴趣的小伙伴可以扫描下方的二维码加群,我们可以一起交流更多的问题。

二、实现细节
1、前提条件
在执行下面的操作之前,请保证你当前已经具有以下的这些环境。
- Ubuntu 16.04系统
- NVIDIA 显卡,建议不低于GTX 1080
- CUDA驱动,CUDA8.0\CUDA9.0\CUDA10.0均可,建议设置为可以随时切换的模式
- Anaconda3
2、数据标注
对于一个完整的深度学习流程而言,数据标注是必不可少的一环,数据标注质量会极大的影响算法的性能。当前如果你使用别人已经标注好的数据或者公有的数据集,请直接跳过该步骤。
下面就来简单的介绍几种数据标注工具,当前已经有很多开源的数据标注工具,这些工具基本上可以满足我们98%的需求,工具没有好坏之分,合适自己的工具就是好工具,所以大家需要根据自己的情况去选择合适的标注工具。
2.1 Labelme
Github链接
2.1.1 工具特点简介
- 同时支持Ubuntu / macOS / Windows系统
- 可以使用多边形、矩形、圆、线和点进行图像注释
- 支持VOC和COCO数据格式
- 支持分类、检测和分割等多个计算机视觉任务
2.1.2 工具安装
方案1:
conda create --name=labelme python=3.6
source activate labelme
pip install labelme
方案2:
sudo apt-get install python3-pyqt5 # PyQt5
sudo pip3 install labelme
2.1.3 工具使用简介
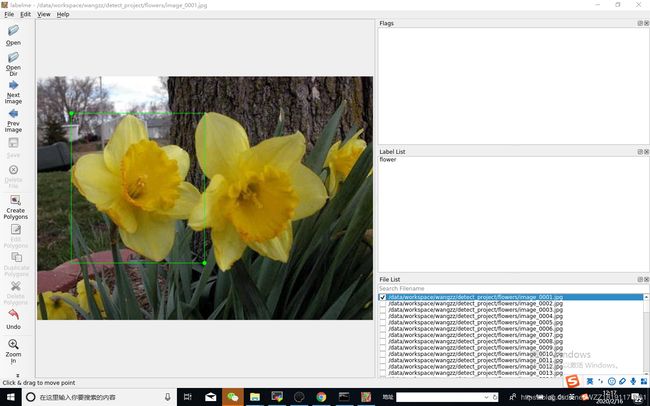
上图展示了Labelme工具的标注界面,工具的使用留给大家自己去熟悉,在这里我只会强调几个需要注意的地方,具体的内容如下所示:
- 建议把需要标注的数据集存放在一个文件夹下面,并以相应的名字来命名
- 该工具默认的标注方式是多边形,如果进行目标检测任务,通过Edit->Create Rectangle来切换
- 在标注的过程中,尽量做到精细化的标注,尽量先将目标放大,再执行精细标注,标注的质量会对极大的影响检测算法的精度
- 该工具默认会生成.json格式的标签并和标注图片存放在同一个目录,.json格式的标签文件适合用来构建COCO数据集格式,而.xml格式的标签文件适合用来构建VOC数据集格式,
2.2 LabelImg
Github链接
2.2.1 工具安装
方案1:
pip3 install labelImg
labelImg
labelImg [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
方案2:
git clone https://github.com/tzutalin/labelImg.git
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3
python3 labelImg.py
python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
2.2.2 工具使用简介

上图展示了LabelImg工具的标注界面,工具的使用留给大家自己去熟悉,在这里我只会强调几个需要注意的地方,具体的内容如下所示:
- 该工具默认生成的标签格式为.xml,便于构造成VOC数据集的格式
- 该工具可以将以前使用的标签保存起来,并将其设置为默认标签,这个单类目标检测任务中能够极大的节约你的时间
总而言之,通过使用上面两个工具对我们自己的数据集进行标注之后,我们最终会获得一些.json或者.xml格式的标签文件。当然你也可以使用其它的工具进行标注,具体的细节请看该链接。
3、标签预处理
通过标注工具我们已经获得了我们需要的标签文件,那么我们为什么还需要标签预处理操作呢?其实原因是这样的,在计算机视觉界,你可能都会或多或少的听说过PASCAL VOC和COCO数据集吧,由于这两个数据集得到了大量的应用,学者们已经针对这两个数据集写了很好有用的代码,比如如何快速的加载图片和标签文件等,那么,对于一个新手来说,能够复用大佬们的代码是一个很明智的选择,这样你不仅不需要去写冗长的加载和处理代码,而且还可以极大的加快你的开发进程,这就是对生成的标签进行预处理的目的。简而言之,所谓的标签预处理即是将自己的图片和标签文件调整为PASCAL VOC和COCO数据集的格式,这样我们只需要更换数据集,就可以很块的完成数据的加载和解析工作。
3.1 PASCAL VOC数据集格式详解
datasets
|__ VOC2007
|_ JPEGImages
|_ Annotations
|_ .xml
|_ ImageSets
|_ Main
|_ train.txt/val.txt/trainval.txt/test.txt
|_ SegmentationClass
|__ VOC2012
|_ JPEGImages
|_ .jpg
|_ Annotations
|_ ImageSets
|_ SegmentationClass
|__ ...
1、Annotations文件夹中存放使用标注工具获得的.xml标签文件;
2、ImageSets/Main文件夹中存放着训练集\验证集\训练验证集\测试集图片的名称,后续代码训练的图片从这些文件中读取;
3、JPEGImages文件夹中存放的是原始的训练和验证图片,验证图片是随机的从训练集中获得的;
4、SegmentationClass和SegmentationObject用来存放目标分割的信息,由于当前的任务仅仅是一个目标检测的任务,因而不需要在这两个文件夹下面存放任何文件;
3.2 构造新的PASCAL VOC数据集
# 切换到自己的想要存放数据集的目录,xxx代表自己的具体目录
cd xxx
#########################1、创建数据集包含的相关文件夹#########################
mkdir datasets
cd datasets
mkdir Annotations
mkdir ImageSets
mkdir JPEGImages
mkdir SegmentationClass
mkdir SegmentationObject
cd ImageSets
mkdir Main
#########################2、移动图片和标签到相应的文件夹#######################
cd xxx # xxx表示你的图片路径
mv * JPEGImages # 将图片(.jpg/.png/.bmp等)移动到JPEGImages文件夹中
cd xxx # xxx表示.xml文件所在的路径
mv * Annotations # 将标签文件(.xml)移动到Annotations文件夹中
#########################3、生成Main文件夹下面的.txt文件#######################
# coding=utf-8
import os
import random
# 用来划分训练集合验证集的比例
trainval_percent = 0.95
train_percent = 0.85
# 设置输入的.xml和输出的.txt文件的路径
xmlfilepath = './datasets/VOC2007/Annotations'
txtsavepath = '.datasets/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
# 打开相应的文件,准备存储内容
ftrainval = open('./datasets/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('./datasets/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('./datasets/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('./datasets/VOC2007/ImageSets/Main/val.txt', 'w')
# 遍历所有文件进行写文件
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
# 写完之后关闭文件
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
如果你是使用Labelme生成的.json格式的标签文件,你想要使用VOC格式训练网络,那么你需要使用下面这个小工具将.json格式转换为.xml格式
#########################4、对.json格式的标签文件进行处理#######################
# coding=utf-8
import os
import numpy as np
import codecs
import json
from glob import glob
import cv2
import shutil
from sklearn.model_selection import train_test_split
#1.标签路径
labelme_path = "./xxx/" # 原始xxx标注数据路径,需要更换成自己的数据集名称
saved_path = "./datasets/VOC2007/" # 保存路径
#2.创建要求文件夹
if not os.path.exists(saved_path + "Annotations"):
os.makedirs(saved_path + "Annotations")
if not os.path.exists(saved_path + "JPEGImages/"):
os.makedirs(saved_path + "JPEGImages/")
if not os.path.exists(saved_path + "ImageSets/Main/"):
os.makedirs(saved_path + "ImageSets/Main/")
#3.获取待处理文件
files = glob(labelme_path + "*.json")
files = [i.split("/")[-1].split(".json")[0] for i in files]
#4.读取标注信息并写入 xml
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
json_file = json.load(open(json_filename,"r",encoding="utf-8"))
height, width, channels = cv2.imread(labelme_path + json_file_ +".jpg").shape
with codecs.open(saved_path + "Annotations/"+json_file_ + ".xml","w","utf-8") as xml:
xml.write('\n' )
xml.write('\t' + 'UAV_data' + '\n')
xml.write('\t' + json_file_ + ".jpg" + '\n')
xml.write('\t\n' )
xml.write('\t\tThe Defect Detection \n')
xml.write('\t\tDefect Detection \n')
xml.write('\t\tflickr \n')
xml.write('\t\tNULL \n')
xml.write('\t\n')
xml.write('\t\n' )
xml.write('\t\tNULL \n')
xml.write('\t\tWZZ \n')
xml.write('\t\n')
xml.write('\t\n' )
xml.write('\t\t' + str(width) + '\n')
xml.write('\t\t' + str(height) + '\n')
xml.write('\t\t' + str(channels) + '\n')
xml.write('\t\n')
xml.write('\t\t0 \n')
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:,0])
xmax = max(points[:,0])
ymin = min(points[:,1])
ymax = max(points[:,1])
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
xml.write('\t)
xml.write('\t\t' +json_file["shapes"][0]["label"]+'\n')
xml.write('\t\tUnspecified \n')
xml.write('\t\t1 \n')
xml.write('\t\t0 \n')
xml.write('\t\t\n' )
xml.write('\t\t\t' + str(xmin) + '\n')
xml.write('\t\t\t' + str(ymin) + '\n')
xml.write('\t\t\t' + str(xmax) + '\n')
xml.write('\t\t\t' + str(ymax) + '\n')
xml.write('\t\t\n')
xml.write('\t\n')
print(json_filename,xmin,ymin,xmax,ymax,label)
xml.write('')
#5.复制图片到 VOC2007/JPEGImages/下
image_files = glob(labelme_path + "*.jpg")
print("copy image files to VOC007/JPEGImages/")
for image in image_files:
shutil.copy(image,saved_path +"JPEGImages/")
#6.split files for txt
txtsavepath = saved_path + "ImageSets/Main/"
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
total_files = glob("./VOC2007/Annotations/*.xml")
total_files = [i.split("/")[-1].split(".xml")[0] for i in total_files]
test_filepath = "./test"
for file in total_files:
ftrainval.write(file + "\n")
#test
for file in os.listdir(test_filepath):
ftest.write(file.split(".jpg")[0] + "\n")
#split
train_files,val_files = train_test_split(total_files,test_size=0.15,random_state=42)
#train
for file in train_files:
ftrain.write(file + "\n")
#val
for file in val_files:
fval.write(file + "\n")
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
3.3 COCO数据集格式详解
COCO_ROOT
|__ annotations
|_ instances_valminusminival2014.json
|_ instances_minival2014.json
|_ instances_train2014.json
|_ instances_val2014.json
|_ ...
|__ train2014
|_ <im-1-name>.jpg
|_ ...
|_ <im-N-name>.jpg
|__ val2014
|_ <im-1-name>.jpg
|_ ...
|_ <im-N-name>.jpg
|__ ...
1、COCO_ROOT表示自己的数据集所在的文件夹的名称;
2、annotations文件夹用来存放标签文件,instances_train2014.json和instances_val2014.json分别表示训练集和验证集的标签;
3、train2014和val2014文件夹分别用来存储训练集和验证集的图片,命名格式为im-N-name.jpg的格式;
3.4 构造新的COCO数据集
本文更倾向于生成VOC格式的数据集,如果你需要生成COCO格式的数据,请参考博文1和博文2。
4、搭建SSD运行环境
# 克隆一份SSD代码到本地
git clone https://github.com/lufficc/SSD.git
cd SSD
# 创建conda虚拟环境
conda create -n ssd python=3.6
# 激活虚拟环境
conda activate ssd
# 安装相应的python依赖包
pip install torch torchvision yacs tqdm opencv-python vizer
pip install tensorboardX
# 克隆一份cocoapi到本地
git clone https://github.com/cocodataset/cocoapi.git
# 切换到PythonAPI路径并安装
cd cocoapi/PythonAPI
python setup.py build_ext install
# 切换到ext文件夹
cd ext
# 编译NMS等操作,用来加速网络的训练过程
python build.py build_ext develop
5、修改代码训练网络
5.1 代码架构详解
configs-该文件夹下面存放的是不同的网络配置文件;
mobilenet_v2_ssd320_voc0712.yaml-表示mobilenet backbone的配置文件;
vgg_ssd512_voc0712.yaml-表示vgg backbone的配置文件;
datasets-该文件夹存放数据文件,具体的结果看上文;
demo-该文件夹存放一些测试图片;
ext-该文件夹存放CPU和GPU版本的NMS代码;
figures-该文件夹存放网络训练过程中的一些可视化文件;
outputs-该文件夹存放训练过程中的log文件和模型文件(.pth);
demo.py-该文件用来测试新的图片并输出检测结果;
train.py-该文件用来训练网络;
test.py-该文件用来测试网络;
ssd-该文件夹中存放ssd算法的实现代码;
config-该文件夹存放着默认的配置文件;
data-该文件夹中存放着基本的数据预处理源文件,包括voc和coco数据集;
engine-该文件夹中存放着基本的训练和推理引擎的实现源码;
layers-该文件夹中存放着separable_conv的实现源码;
modeling-该文件夹中存放着SSD网络的Backbone和head网络的源码;
solver-该文件中存放着SSD网络中使用到的优化器的源码;
structures-该文件夹中存放着一些Box的help函数的源码;
utils-该文件夹中存放着一些训练和推理SSD算法的小工具的源码:
5.2 修改网络配置参数
mv datasets SSD # 将构造好的VOC数据集移动到SSD文件夹中
cd configs # 切换到配置文件夹下面
vim vgg_ssd512_voc0712.yaml # 使用vim打开配置文件
注:
1、vgg_ssd512_voc0712.yaml表示使用VGG作为基准网络,SSD网络的输入大小为512x512 ,使用VOC2007格式的数据集来训练新的网络,大量的实验结果表明该配置参数下能够获得最好的检测效果。
2、vgg_ssd300_voc0712.yaml表示使用VGG作为基准网络,SSD网络的输入大小为300x300 ,使用VOC2007格式的数据集来训练新的网络,由于输入图片的分辨率由512减小到300,整个网络的训练速度得到了提升,但是效果不如vgg_ssd512_voc0712.yaml架构。
3、mobilenet_v2_ssd320_voc0712.yaml表示使用Mobilenet_v2作为基准网络,SSD网络的输入大小为300x300 ,使用VOC2007格式的数据集来训练新的网络,由于使用Mobilenet_v2作为基准网络,因此该架构下面的训练速度最快,但是最终获得精度也是最差的,这个架构适合于一些简单的检测任务,Mobilenet_v2不能能够获得较好的检测效果,而且可以获得接近实时的推理速度。
###############################修改前的网络配置###############################
MODEL:
NUM_CLASSES: 21
BACKBONE:
OUT_CHANNELS: (512, 1024, 512, 256, 256, 256, 256)
PRIORS:
FEATURE_MAPS: [64, 32, 16, 8, 4, 2, 1]
STRIDES: [8, 16, 32, 64, 128, 256, 512]
MIN_SIZES: [35.84, 76.8, 153.6, 230.4, 307.2, 384.0, 460.8]
MAX_SIZES: [76.8, 153.6, 230.4, 307.2, 384.0, 460.8, 537.65]
ASPECT_RATIOS: [[2], [2, 3], [2, 3], [2, 3], [2, 3], [2], [2]]
BOXES_PER_LOCATION: [4, 6, 6, 6, 6, 4, 4]
INPUT:
IMAGE_SIZE: 512
DATASETS:
TRAIN: ("voc_2007_trainval", "voc_2012_trainval")
TEST: ("voc_2007_test", )
SOLVER:
MAX_ITER: 120000
LR_STEPS: [80000, 100000]
GAMMA: 0.1
BATCH_SIZE: 24
LR: 1e-3
OUTPUT_DIR: 'outputs/vgg_ssd512_voc0712'
###############################修改后网络配置###############################
MODEL:
NUM_CLASSES: 18
BACKBONE:
OUT_CHANNELS: (512, 1024, 512, 256, 256, 256, 256)
PRIORS:
FEATURE_MAPS: [64, 32, 16, 8, 4, 2, 1]
STRIDES: [8, 16, 32, 64, 128, 256, 512]
MIN_SIZES: [35.84, 76.8, 153.6, 230.4, 307.2, 384.0, 460.8]
MAX_SIZES: [76.8, 153.6, 230.4, 307.2, 384.0, 460.8, 537.65]
ASPECT_RATIOS: [[2], [2, 3], [2, 3], [2, 3], [2, 3], [2], [2]]
BOXES_PER_LOCATION: [4, 6, 6, 6, 6, 4, 4]
INPUT:
IMAGE_SIZE: 512
DATASETS:
TRAIN: ("voc_2007_trainval",)
TEST: ("voc_2007_test", )
SOLVER:
MAX_ITER: 120000
LR_STEPS: [80000, 100000]
GAMMA: 0.1
BATCH_SIZE: 12
LR: 1e-4
OUTPUT_DIR: 'outputs/vgg_ssd512_voc0712'
注:
1、NUM_CLASSES参数表示检测的类型,由于当前的缺陷数据集的类别数目为17,另外加上一个__background__类,因此需要将该数值修改为17+1=18;
2、BATCH_SIZE参数表示每次训练的图片的个数,由于训练的图片需要加载到内存中,该数值和你当前使用的显卡的内容有着密切的关系,我根据自己的显卡(Tesla T4)将BATCH_SIZE调整为12;
3、LR参数表示网络训练时的学习率,由于我设置的迭代次数比较多,害怕网络跳过最优值,因而我将LR调整为1e-4;
4、TRAIN参数表示网络训练时使用的数据集,由于我们新建了一个类似于VOC2007的数据集,因而我删除了voc_2012_trainval;
5、其它的这些配置参数,你可以根据自己的需要进行修改,但是我建议你不用修改。
5.3 修改VOC类别参数
cd .ssd/data/datasets # 1、切换到datasets文件夹
vim voc.py # 2、打开voc文件
###############################修改前的类别###############################
class_names = ('__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
###############################修改后的类别###############################
class_names = ('_background_', 'Buttercup', 'Colts Foot', 'Daffodil',
'Daisy', 'Dandelion', 'Fritillary', 'Iris', 'Pansy',
'Sunflower', 'Windflower', 'Snowdrop', 'LilyValley',
'Bluebell', 'Crocus', 'Tigerlily', 'Tulip', 'Cowslip')
5.4 下载模型
# 下载vgg_ssd300_voc0712.pth预训练模型
wget https://github.com/lufficc/SSD/releases/download/1.2/vgg_ssd300_voc0712.pth
# 下载vgg_ssd512_voc0712.pth预训练模型
wget https://github.com/lufficc/SSD/releases/download/1.2/vgg_ssd512_voc0712.pth
# 下载mobilenet_v2_ssd320_voc0712.pth预训练模型
wget https://github.com/lufficc/SSD/releases/download/1.2/mobilenet_v2_ssd320_voc0712.pth
# 创建.torch文件夹用来存放模型
mkdir ~/.torch/
# 将预训练好的模型移动到这个文件夹中
mv vgg_ssd300_voc0712.pth ~/.torch
mv vgg_ssd512_voc0712.pth ~/.torch
mv mobilenet_v2_ssd320_voc0712.pth ~/.torch
5.5 训练模型
# 导入环境变量VOC_ROOT
export VOC_ROOT="./datasets"
# 使用vim打开train.py文件
vim train.py
###############################修改前网络训练参数###############################
parser = argparse.ArgumentParser(description='Single Shot MultiBox Detector Training With PyTorch')
# 设置使用的配置文件
parser.add_argument( "--config-file", default="", metavar="FILE", help="path to config file",type=str)
# 设置是否进行local_rank
parser.add_argument("--local_rank", type=int, default=0)
# 设置保存log的步长
parser.add_argument('--log_step', default=10, type=int, help='Print logs every log_step')
# 设置保存checkpoint文件的步长
parser.add_argument('--save_step', default=2500, type=int, help='Save checkpoint every save_step')
# 设置执行网络评估操作的步长
parser.add_argument('--eval_step', default=2500, type=int, help='Evaluate dataset every eval_step, disabled when eval_step < 0')
# 设置是否使用tensorboard进行loss和accuracy的可视化
parser.add_argument('--use_tensorboard', default=True, type=str2bool)
parser.add_argument("--skip-test", dest="skip_test", help="Do not test the final model", action="store_true")
# 设置是否打开使用命令行来改变参数
parser.add_argument("opts", help="Modify config options using the command-line", default=None, nargs=argparse.REMAINDER)
args = parser.parse_args()
###############################修改后网络训练参数###############################
parser = argparse.ArgumentParser(description='Single Shot MultiBox Detector Training With PyTorch')
parser.add_argument("--config-file", default="configs/vgg_ssd512_voc0712.yaml", metavar="FILE", help="path to config file", type=str)
parser.add_argument("--local_rank", type=int, default=0)
parser.add_argument('--log_step', default=20, type=int, help='Print logs every log_step')
parser.add_argument('--save_step', default=2500, type=int, help='Save checkpoint every save_step')
parser.add_argument('--eval_step', default=2500, type=int, help='Evaluate dataset every eval_step, disabled when eval_step < 0')
parser.add_argument('--use_tensorboard', default=True, type=str2bool)
parser.add_argument("--skip-test", dest="skip_test", help="Do not test the final model", action="store_true")
parser.add_argument("opts", help="Modify config options using the command-line", default=None, nargs=argparse.REMAINDER)
args = parser.parse_args()
注:
1、为了便于后续的代码运行,这里直接将–config-file的默认参数设置为vgg_ssd512_voc0712.yaml,即使用VGG作为基准网路,输入大小为512x512,使用自己创建的VOC2007格式的数据集训练新的模型。
2、对于其它的一些超参数,不建议你去改动。
# 如果你有一个GPU,执行该指令训练模型
python train.py
# 如果你有4个GPU,执行该指令训练模型
export NGPUS=4
python -m torch.distributed.launch --nproc_per_node=$NGPUS train.py
注:
1、下面展示是网络训练过程中输出的配置参数。

2、下面展示的是网络训练过程中的Loss、Accuracy和运行时间等输出。

5.6 Loss和Accuracy可视化
# 切换到相应的文件夹
cd ./SSD/outputs/vgg_ssd512_voc0712/
# 使用tensorboard打开网络训练过程中保存的log文件
tensorboard --logdir=tf_logs
# 在谷歌浏览器中输入该网址查看logs
http://ubuntu:6006
注:
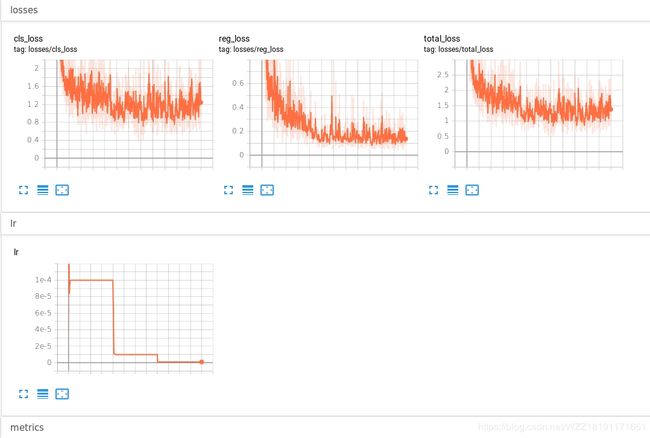
1、Tensorboard展示的logs文件如下图所示,cls_loss表示分类分支的loss曲线,横轴表示的是网络的迭代次数,纵轴表示cls_loss值,该数值越小表示网络预测的结果和标签的结果越接近;reg_loss表示回归分支的loss曲线,横轴表示的是网络的迭代次数,纵轴表示reg_loss值,该数值越小表示网络预测的结果和标签的结果越接近;total_loss是reg_loss和cls_loss之和,如果这3条曲线的整体趋势是随着迭代次数的增加呈现下降趋势就表示我们的网络正在不断的收敛,不断的寻找局部最优解。
2、LR表示网络的学习率,该参数一般设置为1e-3或者1e-4,随着迭代次数的增加应该不断的减小该数值的值以防跳跃最优解,这也就是所谓的衰减率。当在训练的过程中出现NAN或者NULL时可以尝试着调节该参数,或许可以解决该问题。
5.7 模型测试和效果分析
###############################使用test.txt下的图片做测试############################
# 切换到改文件夹
cd SSD/outputs/vgg_ssd512_voc0712/
# 将训练好的模型复制到model文件夹中
cp model_final.pth ../../model/
# 如果你有一个GPU,执行该指令训练模型
python test.py --config-file configs/vgg_ssd300_voc0712.yaml
# 如果你有4个GPU,执行该指令训练模型
export NGPUS=4
python -m torch.distributed.launch --nproc_per_node=$NGPUS test.py --config-file configs/vgg_ssd300_voc0712.yaml
###############################使用特定文件夹下的图片做测试###########################
# 切换到改文件夹
cd SSD/outputs/vgg_ssd512_voc0712/
# 将训练好的模型复制到model文件夹中
cp model_final.pth ../../model/
# 创建测试文件夹
mkdir test_imgs
# 将自己的测试图片拷贝到该文件夹下面,这里*.jpg只是用来进行演示
cp *jpg test_imgs
# 使用SSD对test_imgs文件夹下面的图片进行预测
python demo.py --config-file configs/vgg_ssd300_voc0712.yaml --images_dir test_imgs
注:
1、下图展示了运行python test.py之后的结果,这个输出中主要包含测试图片的数量和训练好的模型在测试集上面的mAP指标值,该指标可以用来评估检测模型的好坏,具体的细节请参考该博客。
![]()
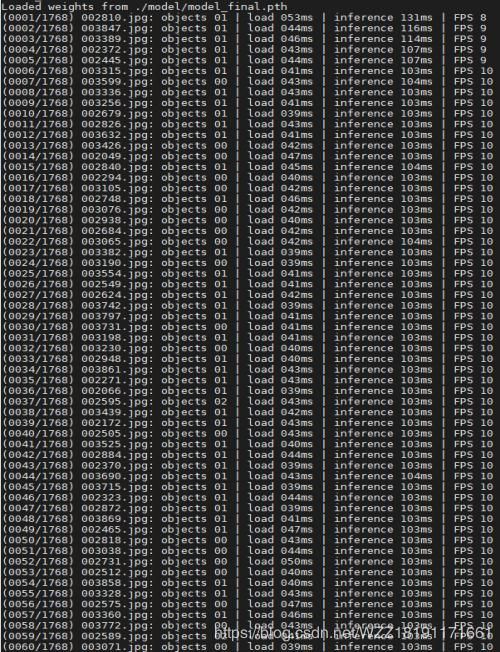
2、下图展示了运行python demo.py之后的结果,这个输出中不仅包含着测试图片的个数1768,同时包含着装载每一张图片所需要的时间,以及对每一张图片进行预测所花费的时间,除此之外,你还可以看到当前的帧率值。
6、SSD性能改进
如果直接使用现成的SSD训练的结果可能并不能达到你的预期精度,那么你可以从以下的几个地方快速的对该模型进行改进,以下的几个思路只是我自己的思路,希望大佬们不要吐槽。
- 思路1-该SSD网络在训练过程中已经包含了数据增强操作,具体的代码在./SSD/ ssd/data/ transforms/init.py下面,但是对于多类别检测任务而言,经常会存在类别不均衡问题,为了解决该问题,最笨的方法就是使用数据增强工具将不同类别的数目调整为相同数量,推荐使用Augmentor工具,具体的使用代码如下所示:
# coding=utf-8
import Augmentor
# 1. 指定图片所在目录
p = Augmentor.Pipeline("./chahua_imgs/")
p.ground_truth("./chahua_labels")
# 2. 增强操作
# 放大 概率0.3,最小为1.1倍,最大为1.6倍;1不做变换
p.zoom(probability=0.5, min_factor=0.5, max_factor=1.6)
p.skew_tilt(probability=0.5, magnitude=1)
p.skew_corner(probability=0.5, magnitude=1)
p.random_distortion(probability=0.5, grid_width=5, grid_height=5, magnitude=1)
p.rotate_random_90(probability=0.5)
p.shear(probability=0.5, max_shear_left=10, max_shear_right=10)
p.flip_random(probability=0.5)
# 3. 指定增强后图片数目总量
p.sample(1000)
- 思路2-如果你熟悉目标检测算法,可能知道Focal_loss可以很好的抑制样本不均衡问题,因而一个改进的思路就是利用Focal_loss替换掉原始的smooth_l1损失,具体的实现可以参考Focal_loss实现。
- 思路3-对于目标检测问题而言,Loss函数的好坏直接或者间接会影响到算法的性能,针对这个问题当前已经有很好改进的Loss函数,比较具有代表性的就是IoU_Loss和IoU的变种GIoU和DIoU等,因而你可以尝试着使用新的Loss来训练SSD网络,具体的实现可以参考DIoU实现。
- 思路4-NMS是目标检测中必不可少的一步, 当前已经有很好NMS的变种算法,你或许仅仅需要修改几行代码就可以提升整个模型的性能,因而你可以尝试着使用Soft-NMS等其它的变种去替换掉原始的NMS操作,具体的实现可以参考Soft-NMS实现。
7、Pytorch模型加速
当你训练完自己的SSD检测模型之后,如果你使用MobileNet_v2的Backbone之后,仍然感觉到整个网络的运行速度不能够满足你的需求,那么你可能就需要做模型加速啦,模型加速的主要方式包括模型蒸馏、模型裁剪和模型量化,当前大量使用的技术是模型量化,如果你需要对Pytorch训练好的模型做模型量化,建议你参考官网量化1、官网量化2。除了官方的量化工具外,你还可以使用这个Pytorch模型优化工具。具体的量化工作就交给大家自己去实现了,只有自己动手去做了才能真正的学懂知识,哈哈。
三、总结
本文的主要目的是教你如何一步步使用现有SSD代码在自己的数据集上面训练出一个可用的检测网络。主要的步骤包括数据标注、标签预处理、配置运行环境、修改模型参数、修改代码参数、训练模型、测试模型、优化模型和部署模型等。本文教给你的不仅仅训练一个SSD网络,当你理解了其中的道理,训练一个Yolov3或者其它的检测算法也就变成一件比较简单的事情了。
参考资料
1、SSD代码
2、Pytorch模型优化工具
3、官网量化1
4、官网量化2
5、Focal_loss实现
6、DIoU实现
7、Soft-NMS实现
8、Augmentor工具
注意事项
[1] 该博客是本人原创博客,如果您对该博客感兴趣,想要转载该博客,请与我联系(qq邮箱:[email protected]),我会在第一时间回复大家,谢谢大家的关注.
[2] 由于个人能力有限,该博客可能存在很多的问题,希望大家能够提出改进意见。
[3] 如果您在阅读本博客时遇到不理解的地方,希望您可以联系我,我会及时的回复您,和您交流想法和意见,谢谢。
[4] 本文测试的图片可以通过网盘链接进行下载。提取码:hku5。
[5] 本人业余时间承接各种本科毕设设计和各种小项目,包括图像处理(数据挖掘、机器学习、深度学习等)、matlab仿真、python算法及仿真等,有需要的请加QQ:1575262785详聊,备注“项目”!!!