机器学习—随机森林算法
作者:WenWu_Both
出处:http://blog.csdn.net/wenwu_both/article/
版权:本文版权归作者和CSDN博客共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文链接;否则必究法律责任
(1) 随机森林基本原理
随机森林几乎是任何预测类问题(甚至非线性问题)的首选。随机森林是相对较新的机器学习策略(出自90年代的贝尔实验室),可应用于几乎所用问题。它隶属于更大的一类机器学习算法,叫做“集成方法”(ensemble methods)。
随机森林由LeoBreiman(2001)提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。
决策树为基本模型的bagging在每次bootstrap放回抽样之后,产生一棵决策树,抽多少样本就生成多少棵树,在生成这些树的时候没有进行更多的干预。而随机森林也是进行bootstrap抽样,但它与bagging的区别是:在生成每棵树的时候,每个节点变量都仅仅在随机选出的少数变量中产生。因此,不但样本是随机的,连每个节点变量(Features)的产生都是随机的。
(2)建立决策树
在建立每一棵决策树的过程中,有两点需要注意采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤——剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
决策树划分原则:
1、信息增益
2、增益率
3、基尼系数
具体的实现过程可参见“机器学习—决策树”
(3)实现过程
具体实现过程如下:
(1)原始训练集为N,应用bootstrap法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类树,每次未被抽到的样本组成了k个袋外数据;
(2)设数据集共有![]() 个变量,则在每一棵树的每个节点处随机抽取
个变量,则在每一棵树的每个节点处随机抽取![]() 个变量(
个变量(![]() ),然后在
),然后在![]() 中选择一个最具有分类能力的变量,变量分类的阈值通过检查每一个分类点确定;
中选择一个最具有分类能力的变量,变量分类的阈值通过检查每一个分类点确定;
(3)每棵树最大限度地生长, 不做任何修剪;
(4)将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定。
(4)优缺点
优点:
1.正如上文所述,随机森林算法能解决分类与回归两种类型的问题,并在这两个方面都有相当好的估计表现;
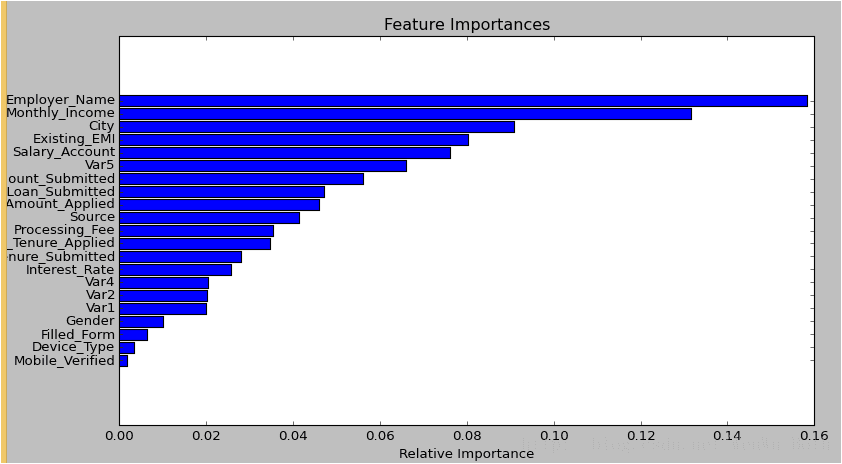
2.随机森林对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出变量的重要性程度,这是一个非常便利的功能。下图展示了随机森林对于变量重要性程度的输出形式:
3.在对缺失数据进行估计时,随机森林是一个十分有效的方法。就算存在大量的数据缺失,随机森林也能较好地保持精确性;
4.当存在分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法;
5.模型的上述性能可以被扩展运用到未标记的数据集中,用于引导无监督聚类、数据透视和异常检测;
6.随机森林算法中包含了对输入数据的重复自抽样过程,即所谓的bootstrap抽样。这样一来,数据集中大约三分之一将没有用于模型的训练而是用于测试,这样的数据被称为out of bag samples,通过这些样本估计的误差被称为out of bag error。研究表明,这种out of bag方法的与测试集规模同训练集一致的估计方法有着相同的精确程度,因此在随机森林中我们无需再对测试集进行另外的设置。
缺点:
1.随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
2.对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
(5)Python实现
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
Python提供了一个机器学习算法的包:scikit-learn,随机森林算法的调用参数官方文档讲的非常详细,我就不班门弄斧了,网址:sklearn.ensemble.RandomForestClassifier