xgboost中的数学原理
xgboost中的数学原理
boosting翻译过来就是提升的意思,通过研究如果将许多个弱分类器集成在一起提升为一个强分类器就是多数boosting算法所研究的内容。其中最为经典的算法就是Adaboost,gdbt,xgboost等算法,本文将从xgboost的原理出发,带大家理解boosting算法。由于xgboost是提升树模型,所以它与决策树是息息相关的,它通过将很多的决策树集成起来,从而得到一个很强的分类器,xgboost中主要的思想与CART回归树是很类似的,因此我们先介绍一下CART决策树,已有该部分知识的读者可以跳过这章。
CART回归树
决策树实际就是一种对空间不断进行划分算法,通过给每个划分的空间赋予一个标签或权重,那么当样本落到这个空间里面,我们就认为这个样本就满足这个标签。

可以预见的是,对空间进行划分其实是一个NP完全的问题,因此我们决策树算法通常采用启发式方法对空间进行划分的。常用的决策树算法有ID3,C4.5,CART决策树。
CART决策树又分为回归树和分类树,CART回归树,它假设了决策树是一颗二叉树。它通过不断地将特征进行分裂(划分为左右两半)来构造一颗决策树。正是因为这一点,我们在使用boosting的时候,需要对离散变量进行one-hot编码处理。你可以想象一下,将一个离散的变量划分为两部分其实是完全没有意义的,因为离散的变量之间并不存在大小关系。
一个典型的CART回归树产生算法包含了一个目标函数:
如果我们希望对变量进行一个划分,比如说将第j个变量 x(j) 和它的某个取值s划分为两个区域:
于是,为了求解最优的切分变量j和最优的切分点s,就转化为求解这么一个目标函数:
那么我们只需要遍历一次所有的变量的所有切分点,就可以找到一个最优的切分位置和变量。然后就这样递归地往下找,就可以产生一颗回归树。
xgboost的建树过程其实是与CART回归树类似的,有了CART回归树的知识,我们理解xgboost的原理也可以轻松很多。接来下将会开始进入xgboost原理的主题。
boosting介绍
boosting的核心思想就是我们希望训练出K颗树,将它们集成起来从而预测我们的Y。我们可以用以下公式表示:
在这里,我们用一个函数 fk(x) 来表示一颗决策树,那个函数 f 可以理解为将样本x映射到树的某个叶子结点中,树中的每个叶子结点都会对应着一个权重 w 。
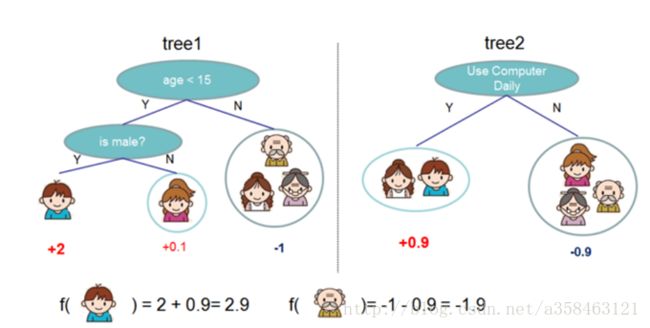
如图,这就是提升树的一个例子,这里一共有两颗树,意味着我们有两个函数 f1,f2 , K=2 ,然后将样本分别放到我们的两颗树中,就可以计算出两个值,把它加起来就是我们要预测的Y。
那么我们应该如何去建立一颗树呢?如果你了解过Adaboost,那么可能会知道,这些树是一颗一颗地建立起来的,通过一颗一颗地建立,不断地减少我们的损失函数。那么如何建立一颗树呢?建立的时候应该怎么去评价一次分裂的效果呢?接下来的一章将会回答这些问题。
xgboost原理
我们先来来考虑一个general的目标函数。
其中 l 是可导且凸的 损失函数,用来衡量 y^ 与 y 的相近程度,第二项 Ω 则是 正则项,它包含了两个部分,第一个是 γT ,这里的 T 表示 叶子结点的数量, γ 是超参,也就是说如果 γ 越大,那么我们的叶子结点数量就会越小。另外一部分则是L2正则项,通过对叶子结点的权重进行惩罚,使得不会存在权重过大的叶子结点防止过拟合。 w 就表示叶子结点的权重。
但是对于上面这么一个目标函数,我们是很难进行优化的,于是我们将它变换一下,我们通过每一步增加一个基分类器 ft ,贪婪地去优化这个目标函数,使得每次增加,都使得loss变小。如此一来,我们就得到了一个可以用于评价当前分类器 ft 性能的一个评价函数:
这个算法又可以称为前向分步优化。为了更快地去优化这个函数,我们可以在 ft=0 处二阶泰勒展开:
其中 gi 表示 l 对 f 的一阶偏导数 gi=∂y^t−1l(yi,y^t−1) , hi 表示 l 对 f 的二阶偏导数 hi=∂2y^t−1l(yi,y^t−1) 。由于我们的目标函数 L 只受函数 f 的影响,上一次的loss对本次迭代并没有影响,于是我们可以删除掉常数项,得到:
举个例子,假设我们的损失函数 l 是square loss:
那么我们的 gi 和 hi 就等于:
由于每个 ft(xi) 都对应着一个叶子结点 wi ,于是我们可以用 wi 来代替一个个 ft ,所以我们将该目标函数改写一下可以得到:
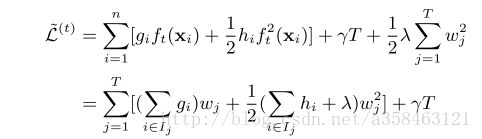
于是,我们对 wj 求偏导,并令其等于0,于是就可以得到基于该目标函数的最优权重:
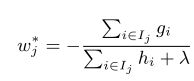
在实际中我们可以直接使用这里 w∗j 的公式来计算叶子结点上的权重。
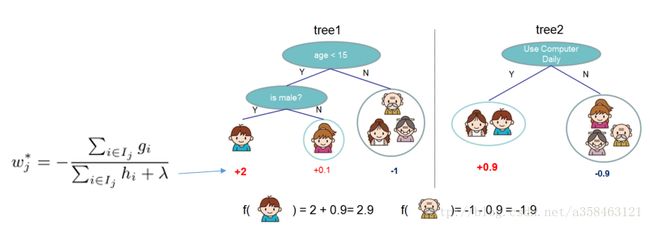
我们将最优权重回代进去,就得到我们的目标函数:
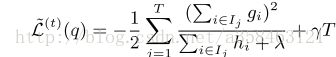
我们就可以用这个作为我们对决策树 ft 性能的评分函数。但是构造决策树实际上是一个NP问题,我们不可能遍历所有的树结构,那么可以用一个贪婪算法去做。它跟CART决策树是一样的,按照评分函数来进行贪婪搜索。
具体步骤,先从单个叶子开始,我们设某个分裂后的属性,将数据分为了 IL , IR 两个部分,然后我们就可以计算: IL+IR−I 的评分,就是我们分裂后的Gain。所以算法的基本步骤应该就是遍历所有特征的所有分割方法,选择损失最小的,得到两个叶子,然后继续遍历。遍历的时候可以并行的执行。

这个公式形式上跟CART算法是一致的,都是用分裂后的某种值 减去 分裂前的某种值,从而得到增益。为了限制树的生长,我们可以加入阈值,当增益大于阈值时才让节点分裂,上式中的gamma即阈值,它是正则项里叶子节点数T的系数,所以xgboost在优化目标函数的同时相当于做了预剪枝。另外,上式中还有一个系数 λ ,是正则项里leaf score的L2模平方的系数,对leaf score做了平滑,也起到了防止过拟合的作用,这个是传统GBDT里不具备的特性。
缺失值处理
另外,基于这个分裂的评分函数,我们还可以用来处理缺失值。处理的方法就是,我们把缺失值部分额外取出来,分别放到 IL 和 IR 两边分别计算两个评分,看看放到那边的效果较好,则将缺失值放到哪部分。
建树时的终止条件
max_depth最大树深度:当树达到最大深度时则停止建立决策树。
min_child_weight:最小的样本权重和,样本权重和就是 ∑hi ,当样本权重和小于设定阈值时则停止建树。
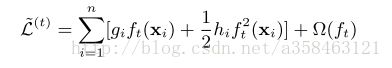
将上式重写一下我们可以得到:

我们发现 hi 是表示样本权重的。
Shrinkage 与采样
除了以上提到了正则项以外,我们还有shrinkage与列采样技术来避免过拟合的出现。所谓shrinkage就是在每个迭代中树中,对叶子结点乘以一个缩减权重eta。该操作的作用就是减少每颗树的影响力,留更多的空间给后来的树提升。
另一个技术则是采样的技术,有两种,一种是列采样(colsample_bytree和colsample_bylevel),一种是行采样(subsample)。其中列采样的实现一般有两种方式,一种是按层随机colsample_bylevel(一般来讲这种效果会好一点),另一种是建树前就随机选择特征colsample_bytree。
按层随机colsample_bylevel的意思就是,上文提到每次分裂一个结点的时候,我们都要遍历所有的特征和分割点,从而确定最优的分割点,那么如果加入了列采样,我们会在对同一层内每个结点分裂之前,先随机选择一部分特征,于是我们只需要遍历这部分的特征,来确定最优的分割点。
建树前就随机选择特征colsample_bytree就表示我们在建树前就随机选择一部分特征,然后之后所有叶子结点的分裂都只使用这部分特征。
而行采样则是bagging的思想,每次只抽取部分的样本进行训练,而不使用全部的样本,从而增加树的多样性。
样本权重
xgboost还支持设置样本权重,这个权重体现在梯度,和二阶梯度上,
grad_xgb[i] = grad[i] * case_weight[i]
hess_xgb[i] = hess[i] * case_weight[i]也就是说样本权重会提高或降低loss的大小。
参考文献
Chen, Tianqi, and Carlos Guestrin. “Xgboost: A scalable tree boosting system.” Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016.
机器学习算法中GBDT和XGBOOST的区别有哪些?
李航. 统计学习方法[M]. 清华大学出版社, 2012.
周志华. 机器学习 清华大学出版社, 2016.
Tiny Gradient Boosting Tree(tgboost)
Introduction to Boosted Trees
How does xgboost handle instance weights
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者a358463121专栏:http://blog.csdn.net/a358463121,如果涉及源代码请注明GitHub地址:https://github.com/358463121/。商业使用请联系作者。