VPX技术基础概论
新型VPX(VITA 46)标准是自从VME引入后的25年来,对于VME总线架构的最重大也是最重要的改进。它将增加背板带宽,集成更多的I/O,扩展了格式布局。
目前,VME64x已经不能满足国防和航空领域越来越高的性能要求和更为恶劣环境下的应用。许多应用,例如雷达,声纳,视频图像处理,智能信号处理等,由于受到VME64x传输带宽的限制,系统性能无法进一步提高。急需要一种新体制的总线,替代现有的VME64x总线,以提高系统传输带宽。
1. VPX标准概述
VITA 46基础标准由VITA46.0(基础协议)和VITA46.1(VME连接)描述,也称为VPX,并成功地于2006年一月引入。这是一个里程碑,因为我们可以确信VITA46标准已经设计和实现出来了。下一步是完成最终文档,并且提交ANSI(美国国家标准化组织)得到正式ANSI批准。
1.1 VPX高速串行总线
VPX总线是VME技术的自然进化,它采用高速串行总线替代并行总线是其的最主要变化。VPX采用RapidIO和Advanced Switching Interconnect等现代的工业标准的串行交换结构,来支持更高的背板带宽。这些高速串行交换可以提供每个差分对儿250MBytes/sec的数据传输率。如果4个信道最高1 GBytes/sec的理论速率。VPX的核心交换提供32个查分对儿,组成4个4信道端口,每个信道都是双向的(一发送差分对儿,一接收差分儿)。VPX模块的理论合计带宽为8 GB/sec。
当今基于VME总线雷达系统阵列中的每个系统处理器,都必须等待轮到该处理器获得总先后才能发送数据。这样不仅仅使处理器终止了对当前数据块的处理,同时还终止了处理器对输入数据的处理。
交换结构使所有数据流畅通无阻,来解决这一问题,这样减小了处理延迟和输入数据流的中断。
StarFabric是一个串行转换结构,他利用现有的VME-64背板链接嵌入式多处理器。可是,VME64X接口的物理特性限制限制了它将来的发展。在VITA46开发以前,雷达系统开始面临主卡的性能的制约。VME主卡其中两个最严重的限制是每个插槽上通过信号针的数据量限制,以及严重的功率浪费。VITA46通过采用高速连接器和支持先进的交换结构,着重解决了这两个问题。
由于采集的数据频率越高,图像效果越好。随着雷达数据管道变得越来越大,VPX将成为解决这些新需求的新技术。
1.2 VPX接插件
VPX采用了由Tyco公司开发出了模块化的VPX RT2连接器,该连接器内含可控阻抗,低插入损耗,在最高6.25 Gbaud下,串扰小于3%。Tyco公司生产的独特的新7排RT2连接器,与级联块儿和键一起,实现VITA 46模块和背板设计。VITA 46选择RT2连接器的目的是为了解决以下问题:
--- 连接器必须可以发送信号至少5 Gbits/sec
--- 连接器必须提供充足的I/O,适应现代主卡上日益增加的功能。
---连接器的尺寸必须能够满足VME标准长度,以便可以安装PMC模块,能够保证0.8英寸的板间距。
---连接器系统必须足够牢固,这样在军事/航空系统的恶劣环境中才能应用。
VPX技术介绍第一篇
VITA 46模块插入和拔出力量与VME64X模块相近。这是因为虽然VITA46拥有更多的接触点,但是Tyco公司的MultiGig RT2连接器使得每个接触点压力降低而又能保证充分的接触。以上结论都是建立在连接器机械结构评估和测试基础上得来的。
VITA 46 工作组对最终交付使用的VPX连接器,为VPX模块标准做了大量的测试认证。这些测试再现了一些最苛刻的环境测试,执行了板级标准。
主要环境参数测试包括如下:
- 振动及颤动
- 温度
-适度
- 沙尘
- 耐久
- 静电保护
1.3 VPX的I/O能力
VPX拥有着更多的I/O能力,其数量几乎是64X类型卡的两倍。所有的I/O针都有千兆传输能力,最高到6.25 Gig/Sec。并且有辅助的VITA 48标准选择,使得每个插槽可以插更高功率的板子。与传统的VME技术比VPX的针脚数要多,一般的6U VPX模块可以提供:
总共707个非电源电触电
总共464个信号:
64个信号,用于核心交换的32个高速差分对
104个信号,用于实现VME64的
268个通用用户I/O,其中包括128个高速差分对儿。
28个信号,用于作系统信号(重启,JTAG,寻址等),其余未使用。
VPX提供最高32个网络交换针,这些针的作用:
---得到更多的吞吐量
---提升性能
--实现网状拓扑结构
---减少插槽数
---无需交换插槽
---节省空间和降低重量
VPX技术介绍第一篇
1.4 VPX的电源改进
VPX改进了电源供电。5V最高可达115W,12V最高可达384W,48V最高可达768W。
如此大功率的电源,允许板子集成更多的功能。可选的更高的电压输入,可以减少背板的电流,降低重量和降低电子兼容问题产生。
2. VPX高速串行总线
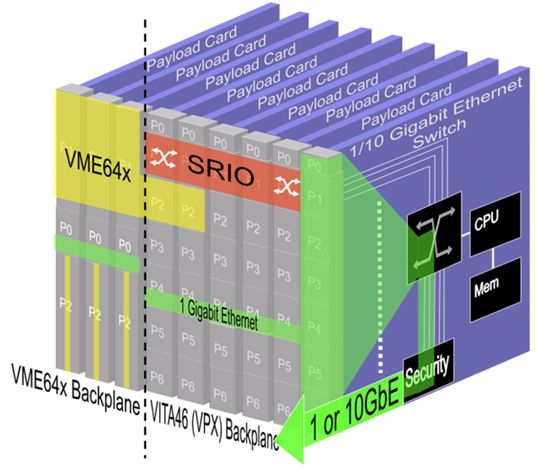
新串行交换结构技术使得军用和航空嵌入式计算机系统得到更高的性能,同时减少系统成本和重量。如今有多种高性能交换结构技术可供选择。这其中的三个——Gigabit Ethernet (GbE), Serial RapidIO (SRIO), and PCI Express (PCIe)尤其突出,优点最多。GbE是基于IP数据通信的标准,无论是平台间网络还是在同一个背板中的子系统。SRIO是DSP应用中高密度多处理簇互联的最好方式。第三种,PCIe事实上已经是,核心处理器到外围设备高带宽数据流传输应用的标准。图1展示了嵌入式系统的网络结构的概念。
因为不可能有一种网络交换技术可以满足国防和航空嵌入式应用领域中所有的需求,所以业界各大特种计算机公司提出了分层(hierarchy)解决方案——使用GbE作为平台间网络互联,并且使用SRIO和PCIe作为底板总线交换网络互联。使用这种方式,国防和航空系统集成商可以在他们系统中应用交换结构技术。
GbE,SRIO以及PCIe各有优势,如果将这些交换结构结合在一起应用于嵌入式军用系统中,将形成功一种新的能强大的结构。经过应用,主要的芯片,板子大量真实评估,以及主板整体设计,一种被称为VPX新的高性能底板问世。无论客户应用采用分布的、集中的,还是混合的网络拓扑结构,这种存在多种网络交换的计算平台,允许用户选择最合适的网络来满足系统需求设计。
GbE可以应用于松散耦合系统的链接,SRIO, PCIe,或两个结合使用适合于处理器,外围设备以及板卡之间的紧密耦合通信簇。用户可以使用1/10GbE交换网络建立Intra-Platform Network(IPN)来有效的传输IPv4/v6信息包,用户可以使用标准的电缆连接不同的系统,或者通过标准底板进行板子与处理器间传输(参看图1)。SRIO更适用于组建网状拓扑结构的数字信号处理器应用,PCIe更适用于核心处理器到外围设备的高带宽数据传输。
2.1高性能网络1/10 Gbe交换
以太网是目前最普遍的网络技术。几乎所有的网络通信的起始和重点都有以太网连接。这种商业领域广泛的应用正在影响军用市场,找到某种方式将网络中心引入加固国防应用市场。
Network Centric Warfare (NCW)学说的实现推动了高带宽、高可靠的IP网络的战场通信的发展。随着国防部对利用现有资源无缝连接到全球网络的迫切需求,1-GbE网络交换已经成为链接机箱和链接板子,组建今天高带宽IP平台网络的首选。
将来的技术转向1/10Gbe网络是很自然的事情,它是一种高速网络的解决方案,足可以满足日益增长的苛刻应用需求。为了满足有效地在平台资源间传输音频,视频,控制及管理数据的需求,支持IPv4/v6的1/10 Gbe提供了统一的方法来进行标准数据传输。
通过简单的在原来系统上增加交换机或PMC交换卡,在VME64x机箱里组建星型或双-星型网络来升级原有系统。采用VPX背板的新系统不仅可以允许1 GBE接口,还可以允许10 GBE接口通过背板路由,这样很容易增加网络带宽。
对于高性能网络,VPX系统采用类似于VME64X系统的集中交换结构,(例如一个VPX交换/路由卡或者一个X/PMC交换卡)通过GbE连接机箱中的板子,机箱可以采用铜或者光介质链接,组建分布式或集中式的网络拓扑结构(参看图2)。
VPX技术介绍第一篇
虽然有很多现行的GbE标准,其中的最流行的几个标准和特性包括:
1000BaseT,一般用于铜介质背板进行板间或处理器间通信。1000BaseSX(1 Gb/s)一般用于光介质传输。XAUI一般用于堆栈或者作为数据干路的10 GbE交换卡。
每个GbE接口是10 Mb/s, 100 Mb/s,和1 Gb/s自适应, 或者通过链接代理得到多种速率,提供高性能连接。
以太网未来的标准将会发展到背板上支持802.3ap (一个信道的1000Base,四个信道的10GBaseKX4以及一个信道的10GBaseKR)。
新一代1/10 GbE交换芯片将很快投入市场,每个口运行速度可以在1,2.5,5,和10 Gb/s。
优化的1和10 GbE NIC芯片即将投入市场,它可以通过远程直接内存访问(RDMA)和TCP卸载引擎(TOE)消除网络瓶颈(举例来说:一个10 GbE RDMA/TOE NIC芯片可以达到800-MBytes/s,并且占用最小的处理器周期进行大的数据传输)
由于采用RDMA和TOE技术减轻了1/10 GbE终端节点的瓶颈和TCP/IP协议握手所花费的处理器额外负载,使得GbE还可以应用到低延迟,高吞吐量和确定操作的嵌入式高性能聚合应用中。
在商业领域中,1 GbE 和10 GbE 能否迅速的应用到大多数主要的军用平台的决定因素,是降低成本提高性能。
2.2 串行RapidIO 发展壮大
SRIO, 高速串行交换结构技术,正在多处理器信号处理应用例如雷达,声纳,自动目标识别以及信号智能等高性能数据传输扮演越来越重要的角色。SRIO综合了许多的重要特性,使它比PCI Express和以太网更适合组建大量的处理器间通信的大型多处理器系统。采用传统的StarFabric或者Race++连接技术构造系统设计师们发现,他们的下一代产品如果使用基于SRIO产品开发会很容易成功。SRIO特性包括:
每组包括一个发差分儿送及一个接收差分儿(称为一个信道)1.25,2.5,或者3.125 Gb/s信号速率,每个信道单方向最高可以到312.5 Mbytes/s
每个SRIO口可以有一个或者四个信道,每个口单方向最高的理论数据速度为1.25Gbytes/s
8B/10B编码以,端对端封包CRC校验
四级优先权
采用消息和门铃方式进行有效的处理器间通信。用于高可靠应用的冗余路由。
SRIO在建立多处理器系统时,与同类产品相比较有很多不同。SRIO为点对点通信设计,支持寻址模型,支持消息传输等方式确保高效、快速的数据传输。串行RapidIO系统可以构造任意拓扑结构,这对构建变化多端的数据流DSP系统是非常重要的。
最近军事及航空信号处理市场最重要的变化是VPX模块格式的引入。VPX格式协议(包含VITA 46及附件VPXREDI/ VITA 48)利用现代高速串行接口的性能,建立了一个新的COST标准。VSO组织标准定义了VME-以及cPCI-兼容的3U-和6U-尺寸模型,使用当今高速串行网络比如说SRIO的信号速度的现代背板连接器。VPX标准基于"核心网络"连接器的概念,充当板间通信媒介,也就是我们常说的"交换串行背板"。在VPX中,核心网络包含4个四信道 SRIO口。在SRIO 3.125 Gb/s的信号速率时,VPX板可以访问5 Gbytes/s发送和5 Gbytes/s接收,总共10 Gbytes/s的通信带宽。当前,几个领先的嵌入式厂商包括Curtiss-Wright已经发布基于SRIO连接的VPX产品。
VPX技术介绍第一篇
2.3 PCI Express: 高性能接口
PCIe接口普遍应用于商用桌面电脑,笔记本及服务器中。在大量PC应用中,PCIe的普及有助于降低PCIe交换芯片和PCIe外围设备的成本。尤其最近,PCIe开始移植到先进的单板计算机和数字信号处理器模块中,部署于军用及航空应用设计中。由于在PC市场的普及,使得低成本成为优势,技术上说,PCIe确实是一种先进的连接技术。它的主要特性包括:
点对点通信:每个链接(点对点连接)可由1,2,4,8,16,或者32信道组成。
每个lane由一个传输和一个接收对儿组成,发信为2.5Gband,理论上数据速率为每信道每方向250Mbytes/s,或8信道总合数据速率为4 Gbytes/s。
每个数据位采用8B/10B编码和每个信息包端对端CRC提供充分的错误校验。
它的信息包承认协议,在错误时自动重发,提供端对端可靠数据传输不需要软件控制。
数据流划分优先次序
它的物理层强制位不规则性来降低EMI(消除长序列1或者0,目的是消除长电平,强制方波)
它的电信号层采用了pre-emphasis/de-emphasis来优化信号完整性,允许低印刷电路和接头原料成本
商业PC市场出现了基于PCIe的各种各样的板子,这些基于PCIe的模块的标准包括:
标准桌面PC的PCI Express卡
ExpressCard模块将替代现今的PCMCIA。
PICMG 3.4 (PCIe on AdvancedTCA)
PICMG EXP.0 (CompactPCI Express)
PICMG AMC.1 (PCIe on Advanced Mezzanine Card)
EPIC Express标准,来自PC/104 Consortium
由VITA标准组织(VSO)定义的,广泛应用于嵌入式军事/航空领域中,基于PCIe的模块标准,以前发布了几个版本。包括先前提及的VPX和VITA 42。VITA 42(也称为VMC"交换Mezzanine卡")是广泛应用在VME和CompactPCI PMC格式的扩展。VITA42通过在模块上增加两个高速接头,扩展了最初的PMC协议,VITA42.3补充协议定义了PCIe到新的XMC接头的映射。这样,兼容VITA42.3-主卡和mezzanine卡可以通过PCIe进行多个gigabyte/s交换数据,VITA42 可以应用于诸如高解析度图像引擎和G sample/秒模拟的数据采集模块等高级应用。
新的VPX模块标准同样采用了PCIe。图4是代表性的VPX模块,图解了Tyco Multigig RT2背板接头和两个VITA XMC插槽。
3. PowerPC处理器
如今国防和航空系统设计师们在选择他们下一代DSP系统结构时有着很多的选择。DSP和通用处理器市场充斥着各种构架的处理器,包括MIPs, X86, ARM和Power构架等产品,他们拥有不同的性能、功率和价格。在众多选择中,Power构架成为了能满足军用航空系统需求的少数处理器之一。为什么这个90年代初才引入的构架能一直牢牢把握这个特殊市场呢?他未来还能一直领导这个市场吗?Power构架的演变过程瞄准嵌入式应用,一直保持低功率、高性能的特点。该构架还将继续演变,以适应未来更复杂的应用。
3.1 Power构架的演变
最初的PowerPC构架是由苹果,IBM和摩托罗拉公司共同研制的,他针对IBM公司的RISC(Power)构架处理器进行了优化和增强。虽然最早的PowerPC构架针对桌面系统,但是他优化了指令系统结构(ISAs),使其适用不同的应用。Book E是其ISA指令集之一,他是针对嵌入式市场设计的指令集。他只包括一条Book,性能和功耗在嵌入式应用市场是同样的重要,该指令集很好的平衡了这两者,使处理器能够应用到A&D系统。从那时起,向量处理和电源管理的创新使得PowerPC构架又演化成Power构架,嵌入式系统设计师能够平衡性能和功率因素。
AltVec单指令多数据(SIMD)指令集是重要改进之一,并最终使其演化成Power构架。这个扩展功能于1999年引入,AltVec作为MPC74xx处理器的一部分,苹果公司的G4 Macintosh系列电脑采用了这款处理器。这个革命也为DSP世界带来了突破,用户除了专用DSP芯片有更多的选择,因为AltVec技术使得处理器内核进行向量处理。许多军事应用要求支持浮点运算,AltiVec技术可以提供,因为富电源算比定点运算效率更高,但一般需要额外的硬件。军事和航空应用不像一般的电子应用对成本非常敏感,这些应用对执行效率和支持浮点运算提出更高的要求。有趣的是直到Power.Org官方将AltiVec写进ISA2.0.3发布版本,在这之前他从来就没有作为PowerPC构架的一部分。
VPX技术介绍第一篇
表一
今天,对于很多航空和国防DSP应用,AltVec技术都是一种标准的实现方法。他支持多种实时操作系统。专用DSP芯片由于不支持标准的实时操作系统,采用专用DSP芯片比Power构架技术编程更加困难。Power构架允许系统集成师利用大量的第三方供应商提供的高级的工具。
Power构架另外一个重要的优点是低功耗。随着需求的增长,要求在VME和VPX系统中有限空间内部署更多的处理器,Power构架技术开发商开始在一个芯片内集成更多的处理器内核。例如Freescalse的 MPC8641D双核处理器就是这样的处理器。双核处理器可以释放出双倍的性能,但与两个单核处理器比较却降低了电源消耗。将更多的功能集成到一个芯片,板子上芯片数量降低从而提高了可靠性和性能。这也节约了板子空间,要知道班子空间对军事和航空设计师是非常重要的。另外,这样可以解决更高级的系统功率,因为单个芯片更强大,集成更多的功能。
3.2 今天A&D应用的革命
Power构架技术在不断的演化,满足SwaP(空间,重量和功率)日益增长的需求,适应雷达和信号处理等应用。我们可以发现Power构架技术关键的改进在于包含多个内存控制器。这些内置的内存控制器,降低了传输延迟,增加内存总线的带宽,从而提高了系统的速度。这在大量消耗DRAM开款的DSP系统中非常重要,因为这样的系统总是频繁的从DRAM中读数据,处理大量的输入数据。当高性能内核等待从内存读取输入数据时是不工作的,此时没有处理数据的能力。例如,研祥智能科技股份公司的VPX-1813引擎使用Power构架技术的MPC8640D处理器。采用DDR3 内存桥片,驱动125MHz DDR内存接口,峰值2GB/s。最新的 VPX DSP引擎使用DDR2内存,以两倍速度运行,并且拥有两个bank(Discovery III一个),这样内存速度提高了4倍。
随着应用需求的不断变化,图像处理系统需要庞大的、可升级的多处理器系统。Power构架技术与x86构架处理器比较最大的优点在于内置支持Serial RapidIO互联技术。Serial RapidIO互联不像GbE和PCIe互联,他可以组建仲裁拓扑网络。Serial RapidIO使用终端和交换模式,是一种真正的点到点多处理网络技术。终端是处理器自己,他通过链接一个或多个Serial RapidIO交换器与其他终端通信。这些终端和交换器共同构成Serial RapidIO网络或互联。
Serial RapidIO不像其他互联技术,他不要求使用专门的拓扑结构,这是非常灵活的,能够组建很大的系统,最多可达65536个节点,这远远超出绝大多数COST系统需求。在多处理器应用中,理想的假定是系统中的处理器高速、平等的彼此互联,没有一个处理器具有特殊属性,不像PCI/PCI Express系统,有一个处理器作为根节点。MPC8641D的Serial RapidIO接口和支持Serial RapidIO的交换芯片,使得板子设计师采用新VPX(VITA46)标准发挥带宽优势。
3.3展望Power构架的未来
带着嵌入式市场的背景,Power构架在A&D市场已经有了很长的历史。Power.Org 组织于2004年被授权负责制定构架的开放标准和规范,Power构架技术的未来在很大程度上依赖于该组织。Power ISA 2.03已经发布了,向广大Power构架的开发商和最终用户提供了相应的路径。
虽然系统设计师在集成系统的过程中有很多的选择,但是Power构架具有许多关键性的优点,这些优点有助于简化板子的设计,降低功耗,提高复杂DSP应用的带宽。在过去,Power构架技术是低功率、高性能处理器,广泛用于国防、航空系统,它未来的发展是将向量处理,多内存控制器以及Serial RapidIO等交换互联技术结合在一起,形成一个高度集成的解决方案。它的发展还将为设计师们节省空间、降低重量和功耗,而这些恰恰是国防、航空系统的关键。可以预见,Power构架在未来的国防、航空DSP设计中仍将是最重要的处理器构架。
4. VPX与VME, VXS区别
很快迎来25周年的纪念,古老的VMEBus仍然不断演变以满足当前和下一代系统的需求。VITA41协议在保留VME32/VME64同时扩展了交换网络互联。VITA46采用了一百多个串行I/O,取代了传统的并行总线。VITA48增加了一些功能来实现二级维护,同时定义了液冷散热。
由于新的嵌入式国防和航空应用的出现,对带宽和散热技术提出了更高的要求。为了满足这些要求,近日开发出了新型主板结构协议。其中三个最重要的新型协议是VITA 41 VMEbus Switched Serial Standard (VXS),VITA 46和有关协议,以及VITA 48 Enhanced Ruggedized Design Implementation (ERDI)。
为了帮助系统用户理解这些新协议独特的优势和真实的差异,这里帮您比较一下他们多样的特性并突出每一个协议想要解决的问题。系统用户在选择一个系统架构时必须考虑的主要技术差异包括:
物理环境
处理器需求和系统内带宽
外部系统带宽和连接
保存过去的研发成果以及未来验证
技术实用性和成本
总的来看,我们需要特别关注背板连接。因为基本规范VME64X仍然是一个非常重要的技术并仍将使用很多年,我们也同样需要检验如何建立一个VXS,VITA46,和VITA48系统并将其带入VME64X。
4.1 广泛使用的VME
以上所有的三种新协议都兼容老的VME产品,这得用户可以利用以前开发的主板和软件,节约成本。
现今,VME总线技术在非常广阔的领域内应用,包括:
图像(医疗,军事)
工业控制
视频处理
模拟器(飞行,导弹)
雷达/声纳
电子情报
任务计算机
电信系统
不同应用领域有不同的需求。雷达系统可能需要放置在风冷环境或者喷气式战斗机的前端。任务计算机可以简单的收集、记录多个1553接口的输入,也可以接收多个前视红外线(FLIR)图像,分析并显示在多功能显示器上。电信系统可能需要所有的I/O在前面板,这样系统可以背对背放置在设备架子上,也可能需要所有I/O连接走背板布线保证整洁的面板,这样可以迅速确定系统中出问题的卡加以替换。,从而降低平均返修时间(MTTR)。
在空气流通或环境良好的环境中中,使用风冷1101.10机械协议。然而,在恶劣的环境,例如喷气式战斗机的前端需要使用导冷协议1101.2。
在系统内部带宽需求比较低时,协议VME总线就可以提供很好的解决方案。然而,当数据带宽很高时,例如多视频显示系统,或者在多处理器间有高运算负载和数据共享系统中,可以在VME总线主卡的J2连接器上增加二级数据总线例如RACEway,StarFabric或者SKYChannel来提供额外的带宽。但是,这种方式占用了其他I/O的背板插针,例如PMC I/O,1553,串行通道,GigE,以及其他的I/O协议。不幸的是,用户没有任何协议格式供参考,使用这些二级总线。
VITA 41,VITA 46和VITA 48协议为解决这些设计难题而制定的。然而,每个协议集中,解决这些I/O问题都有所不同。
4.2 VITA 41
VITA 41是为了满足高速数据总线需求,为10 GigE,Serial RapidIO,PCI Express,和高级转换连接等下一代高速串行互联开发的协议。这些串行协议的共同特点是都可以运行在2 Gbps。在这样的速度下,标准的VME总线连接器不能工作的。

与此同时,VITA 41特别注意了与老的VME硬件和老的VME主板的兼容问题。VITA 41背板仍然采用J1和J2连接器作为传统的VMEbus,不同的是它采用Tyco公司的7排RT2连接器代替原来的J0连接器。RT2连接器是一个高速差分连接器,提供30个差分对儿,其中16对儿作为高速连接定义。J0其它插针,其中一个针用于支持live insertion,剩下的保留将来使用(RFU)。
图1展示了20插槽的背板,背板上拥有两个交换卡。VITA 41卡采用一个中央交换调度(芯片)进行板间通信。16对差分信号被分为两个双向4信道串行端口。一个端口都连接VITA 41背板其中一个交换卡上,另一个解决连接到另一个交换卡上。这样在其中一个集中交换模块失效时,还有另一个冗余通信路径。
厂商可以提供VITA-41,用在客户定制背板上。这可以满足需要很高带宽的应用,超出老的VME总线P0连接器2 Gbaud的限制。
图1


4.3 VITA 46
VITA 46协议使用了类似又不尽相同的方式来解决带宽问题(参看图2)。相同之处在于它使用RT2连接器,但不同的是,所有连接器都使用RT2连接器,因此使得所有的连接都支持高速差分信号。VITA 46协议在J2定义了32个差分I/O对儿,而VITA 41值定义了16对儿。
这种结构提供了一些很有趣的能力。VITA 41设计为双冗余中央交换,而VITA 46允许用户设计出分布式的网状交换系统,因此不会出现由于单独路径,或者模块的失效而导致系统瘫痪的情况。图2展示4个4信道端口连接到各个模块。当每个信道运行在3.125 Gbaud时,每个端口的双向带宽为2.5 Gbps(由于8B/10B译码会有20%的占用)。网状拓扑的优势在于能够开发出更紧凑、占用更小空间的系统,因为不再需要VITA 41中的两个中心交换槽了。
在尝试提升VME总线模块的带宽能力过程中,VITA 41使用高速差分RT2连接器代替了VME总线J0连接器。然而,这导致了用户I/O针的数量大大减少,从205减少到110。VITA 46通过替换VME总线J0和J1连接器,全部采用RT2连接器,在图2中表出。这样做有很明显的优势。最重要的优势是使用VITA46,用户的I/O数量从VITA 41的110个针增加到272个针。并且,这272个针中有256个是自定义的高速差分对儿,每个的数据传输速率可达10 Gbps。
为了利用这些附加的用户I/O针,VITA46.9定义了XMC和PMC用户针的协议映射。(XMC和PMC User I/O Mapping for VITA 46)。
图2

VITA 46还有一个超过VITA 41的优势。VITA 46其中的一个连接器P0,被设计为功能连接器。功能连接器连接电源,维护总线,和测试总线。电源支持:48 V @ 16 A 或者12 V @ 32 A,作为高功耗卡的主电源。
5 V @ 16 A 作为低功耗卡的主电源
+12 V @ 2 A 作为模拟以及PMC电压
?12 V @ 2 A作为模拟和PMC电压
3.3 V @ 2 A作为辅助电源使用
4.4 向后兼容
构造有效率系统的插槽数越多,就需要更多用户I/O,有多种向后兼容的方案。VITA 41和VITA 46都需要一个新的系统背板。VITA 41向后兼容的方案是使用传统的VME卡,但不使用VME总线上的J0连接器:VITA41采用VME协议的J1和J2连接器与老的VME总线卡通信。在这点上两个协议都是同样的。而VITA46的方案是使用一个混合背板,允许老的VME总线卡插入到系统中。图3展示了混合背板,该背板有五个老的VME槽和5个VITA 46槽。在VITA 46混合背板上,VITA46连接器和老的VME总线间通信遵循VITA46.1(VITA 46的VMEbus总线映射)。
图3

VITA41背板通过放弃VME总线J0连接器的方式,为老的VME卡提供兼容。如果老的卡使用J0连接器,VITA46背板必须要做一些修改,将老的VME总线模块与VITA41模块链接在一起。
4.5 3U VITA 46
VITA46背板拥有更多的插针数量,这一优点特别使用在小型系统中。
老的的3U VME总线系统不提供任何背板用户I/O。VITA46协议提供给系统用户3U解决方案,在VITA46 总线J1上给用户提供网状拓扑,允许用户使用J2作为用户I/O。
VITA46的J2采用的RT2查分连接器提供客户72个用户IO针。
4.6 VITA 48
VITA 48从本质上来说,是一个板型协议,补充了VITA46协议的其他功能。它采用VITA 46协议相同的连接器,并提供所有相同的带宽和用户I/O。除此之外,VITA48定义了二级维护协议,通过利用顶盖来保护模块电路。它同样定义了先进的制冷技术,例如液体循环制冷理论。
为了得到这些优势,VITA 48定义了每个模块的槽间距为1" (从0.8"增加到)。通过允许VITA 46模块插入VITA48背板和机箱,来实现向后兼容。
4.7 总结
三个新出现的协议各自有各自的特点,来解决不同的系统需求。表1将这些特性列出。
VME总线适用于系统内不带宽要求不高的系统,他在将来的很多年都会继续发展及应用。
VITA 41适合于需要比较高的系统内部带宽,同时不需要很多的背板I/O,系统物理空间也不受到限制的应用,这些系统多使用前面板I/O。
VITA 46适合于比较高的系统内部和背板带宽,同时在背板上需要大量的用户I/O针。VITA 46非常适合于系统物理尺寸受到限制的应用,3U VITA 46可在背板上提供用户I/O,而VITA41和VME总线没有。
VITA 48也同样适合于比较高系统内部和背板带宽,需要大量的用户I/O针的应用。然而,他的区别在于它为高功耗主板提供液体循环制冷机制。
5. 采用基于VPX总线的系统迎接航空任务计算应用的挑战
任务计算应用要求背板构架能够在恶劣的军事和航空环境中工作,并且能够为不同的系统提供可靠平台。最新的VPX背板标准使得系统集成商能够在加固平台上使用最最先进的技术。
在众多加固的、开放的嵌入式计算模块构建应用中,航空任务计算应用无疑是系统集成商们最具挑战的应用,任务计算机是软件高度密集的系统,他必须在恶劣的飞机工作环境下处理种类繁多的I/O,并提供可靠的操作。如今,系统集成商可以使用最新的VPX(VITA46)背板标准,利用现代的串行高速互联通信,提供众多高速I/O信号,实现这些目标。并且,VPX已经成功的通过了复杂的环境认证过程。

5.1 任务计算的挑战
无论是一个升级项目或是一个新的飞机系统,任务计算机都需要解决下面最常见的问题:
很多的I/O
通过配合多处理方案,提供强大的计算能力
有限的尺寸和重量限制
在恶劣的航空环境下工作
在电路板级支持二级维护的概念
要求支持多种I/O
很多I/O的需求
任务计算机需要连接大量的系统,包括数据传感器(空速,高速,系统状态),导航子系统,敌我识别单元,雷达,导弹报警传感器,电子战传感器,光电/红外传感器视频,网络数据连,飞行人机界面输入,座舱显示,大容量存储接口,以及一些其他的设备。事实上,复杂的任务计算机需要连接20-30个不同系统。这些不同的数据接口使用不同的电信号级(RS-422, MIL-STD-1553, Fibre Channel, Ethernet, ARINC-429, DVI, 用户自定义高速接口等)。
RS-422和MIL-STD-1553等老的总线标准仍然在使用,与此同时,用于高分辨率数字视频传输的DVI以及用于大容量存储的Serial ATA等较新的标准,也越来越多的采用,使得信号速率到达multi-gibabit范围内。需要数以百计的I/O信号——这些信号中1Gbps或者更大的数据吞吐率的I/O越来越多,这极大的冲击着传统的任务计算系统。所有的这些I/O信号需要散布在系统内不同板级模块中。为了避免在系统中增加额外的专用I/O模块,板级I/O数量增长承受着巨大的压力。
5.2多处理器方案满足强大处理需求
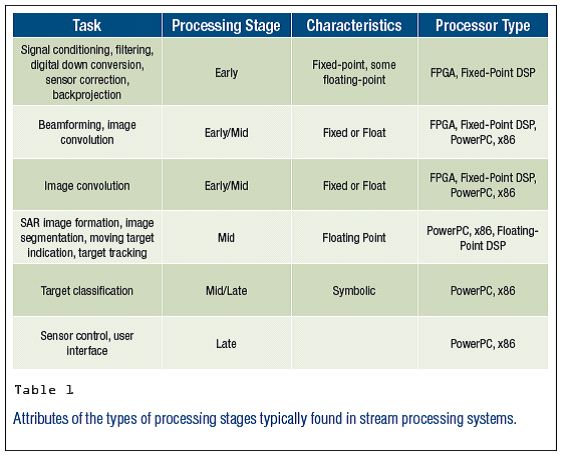
现今,现代航空电子任务计算是一种软件最复杂,嵌入式实时应用。操作飞行程序(Operational Flight Program, OFP)是由系统多功能属性驱动的,极为复杂的程序,他涉及众多工业领域,包括很多的数据源接收器,以及数百个处理任务。表一列出了主要的处理任务。
任务计算应用的复杂性还在于涉及很多处理类型,他们包括:
需要在某个固定的时间进行周期处理,例如60MHz的显示刷新率处理
需要进行异步的,基于需求的处理,例如处理飞行或数据链输入
需要高计算量的处理,例如视频处理
一些任务包含综合的,有限状态机逻辑
据估计,像F-16, F-18等先进飞机的OFP程序大小,其源代码高达5百万行。
5.3 系统的需求
进行这些处理需要多个处理器协调工作,OFP也必须拆成小的,易于管理的模块,方便维护和升级。任务计算的工程师们必将引领面向对象编程技术和用于数据共享的中间件的发展。图一展示了任务计算机软件用到的经典软件分层方法。这些软件层次进一步增加了处理量,对于多处理解决方案需要更强大的计算能力。
基于多处理解决方案,需要处理器间高效的通信手段,目前,通过在硬件层支持软件层用到的逻辑中间件总线实现,如图二所示。高性能,低延迟以及开放标准等特征也是受任务计算机开发工程师青睐的。这些特征可以通过在背板加入Serial RapidIO和Advanced Switching Interconnect(ASI)等互联利用现代高速互联技术,满足工程师们的要求。
5.4 尺寸和重量的限制
无论是超音速战斗机还是攻击直升机,发送攻击,超高的机动能力,任务计算机总是引领飞机在格斗范围内战斗。这迫使系统集成师寻找能够降低最终系统尺寸和重量的总线结构。对于升级现有飞机的电子设备,任务计算机必须采用传统的空间尺寸来实现新功能,这个尺寸一般是ATR标准大小。
5.5 恶劣环境下的性能
除了处理众多I/O,提供强大的处理能力,以及尺寸和重量限制外,系统集成师们设计的任务计算机必须在军用战术航空器中遇到的极端温度,冲击和振动的环境下仍能可靠的工作。振动一般在飞机是非常普遍的,他包括结构振动,引擎振动,枪炮振动,直升机主要是螺旋桨旋转振动,产生的总共随机振动负载大约是20G RMS或者更高。这要求内部的电路板与背板链接器链接足够紧密。
贯穿整个可更换模块的二级维护
一般认为,在整个生命周期内维护一个复杂的武器系统需要的成本要比最初装备成本高好几倍。维护系统成本的很大一部分是维修成本——这不仅仅包括实际的维修,还包括返修运输与备用件储备的后勤保障成本。
在军事服务中,通过直接在平台上拆除和更换可插拔处理板、I/O板等系统模块,减轻后勤保障负担的方法逐渐成为主流思想。这消除了传统的首先拆除系统级黑盒子,然后把它运回库房以备后续更换可插拔电路板的一步骤。围绕Line-Replaceable Modules (LRMs)这个概念设计出的系统,在LRM级储备备用件,取代了传统的在机箱级储备备用件。储备备用件的成本、数量和重量将会减少。
5.6 新VPX标准将会给我们带来什么?
VPX标准为满足客户军用、航空嵌入式计算系统的需要,支持系统级设计,他解决了任务计算机应用面临的诸多挑战。
VPX背板结构的主要元素包括:
基于Tyco公司开发的7排RT-2 MultiGiga连接器设计的高级连接器系统,他提供更多I/O,支持高速的串行链接,以及包含ESD(静电)保护结构
基于标准的0.8英寸厚度的3U和6U模块儿
扩展结构格式VPX-REDI(VITA-48)标准提供了一个顶盖儿和一个底盖儿,他与VPX与一起使得模块应用二级维护环境
FPGA应用于流处理——是很自然的选择
输入信号或图像数据的高性能流处理,要求FPGA能够进行可重配置(reconfigurable)计算,同时能够进行系统及设计,并能解决成本问题。
6. FPGA应用于流处理
许多军事和航空应用都要求对实时数据流,或图像数据流进行高速处理。I/O流处理一般包括滤波,信号调整,校验和采集。虽然一些流处理应用采用专用ASIC芯片,但是他非常不灵活,并且需要很长的设计周期和昂贵的成本,所以不是一个理想的解决方案。此外,为了满足处理需要,流处理应用一般需要解决系统问题,例如尺寸大小,重量,功率,开发周期,现场升级和重配置。
多计算系统一般采用具有灵活的通信网络,基于该系统中的RISC或DSP处理器,用于流处理系统是很自然的选择。但是,迫于系统成本的压力,国防和航空客户只能使用RISC或DSP处理器搭建他们的系统。而现代的FPGA拥有可重配置,很多的逻辑门数量,DSP单元和内置高速穿行口等优点,使得客户拥有更多的选择。
6.1流处理系统的特点
在一些流处理应用中,除了有一些回馈信息需要从后期处理阶段传回前期处理阶段,数据流动的主要方向还是单向流动。前期处理阶段更接近DSP处理,而后期处理更接近于符号处理。处理类型的不同,每个处理阶段使用的硬件有所区别,请参考表1
基于多计算系统的流处理是不同的。他包括I/O板(传感器接口或模数转换),FPGA处理板,用于浮点DSP运算和其他通用计算的四-PowerPC板,以及用于控制和设备I/O的单板计算机。请参考图一。FPGA计算引擎通过专用的串行链接链接系统输入设备。交换通信网络链接不同的处理单元。
图一
表一
6.2使用 FPGA做前期处理
在流处理系统中,现代FPGA技术非常适合做前期处理。Xilinx Virtex-5提供了很大的用户可用面积,专门的浮点DSP单元和高速串口。该FPGA采用65纳米工艺,可以有效的减少漏电电流和静态功率消耗。65纳米工艺还减少了节点电容,并且采用1V核心电压,这些都有助于减少动态功率消耗。
ExpressFabric结构拥有增强的查找表(lookup table, LUT)结构,该查找表结构有6个输入。DSP48E DSP块,拥有25个18-bit乘法器,增强了FPGA浮点运算能力。这些乘法器可以排列成管道或瀑布结构,增加不同滤波器算法的吞吐量。
该FPGA的LXT版本拥有24条高速、低功耗的串行通道,速度从100Mbits~2.3Gbit/s不等,支持很多高速串行I/O标准。此外,还提供Aurora和RapidIO协议的软核,还包括千兆网和PCI Express使用的专用硬件模块。
用于流处理应用的商用平台可以利用Virtex-5 LXT系列的高级特性完成高速早期流处理。例如,基于双LXT版本FPGA板子的高速串行口可以连接背板,子卡插槽,两个FPGA,在这些I/O路径间建立4个信道。每个FPGA使用18对儿(36针)离散LVDS信号链接链接背板,用于并行传输或自定义I/O。
板载多个SRAM和SDRAM bank,确保FPGA 应用能够拥有足够的内存带宽用于存储和访问滤波器模块,暂存运算数据等。当每个内存映射成多口模式时,开发人员拥有很大的灵活进行并行或管道FPGA设计。
6.3将FPGA集成到系统中
这样的FPGA节点用于前期流处理运算。当该节点物理上链接到包含DMA引擎的通信网络时,FPGA节点缺乏通用处理器管理复杂数据传输的灵活性。
例如,DMA的建立和控制一般由外部的通用处理器节点进行处理。支持AltiVec功能的Power构架(PowerPC)Freescale 8641D处理器,可以完成这些任务。初次还可以完成配置FPGA、快速重构,处理器间同步任务、动态调整滤波系数等计算参数的功能。
其中许多任务经过背面控制总线,需要避免打断SRIO总线上传输的数据流。这些功能一般通过操作系统或板级支持包(BSP)函数调用初始化。或者通过通信中间层进行初始化。
流处理应用中的中期和后期处理阶段一般采用PowerPC通用处理器处理,板载PowerPC处理器,除了处理FPGA命令和控制任务,还可以类似四-DSP或单板机里的处理器节点,参与中后期处理。这些处理阶段通常包含浮点向量计算,使用8641D中AltiVec单元进行处理。在这个体系中的板载PowerPC处理器都会得益于丰富的系统和中间软件,用户可以从复杂的集成工作解脱出来,通过抽象出硬件细节,开发出更简化的应用程序代码。
开发的加固的、商业板子满足了流处理应用的需求,它采用6U VPX/VPX-REDI格式,板子上有两块LXT FPGA和一个双核8641D PowerPC处理器(如图二)。
图二,CHAMP-FX2
当流处理应用使用这样的板子时,一般是采用不间断循环传输或者下一个可得处理器传输样式,从FPGA向多处理系统中其他处理器发送数据,FPGA工具集提供驱动和软件库,管理这些复杂数据传输策略,以及节点配置,温度和电流传感器管理,总线访问控制等板载功能接口,这个工具集还提供IP块库,仿真环境,BSP,算法库和中间件等。
CHAMP-FX2的FXtools工具集中的IP库提供DMA引擎。这些引擎有的支持轮转传输。有的支持下一个可得处理器(next-available-processor)传输下一个可得处理器一般传输采用PowerPC驱动的连续链DMA模型,或者采用数据驱动的SRIO终端块儿模型。因为,这些数据传输的建立和控制都非常复杂,所以需要使用通用处理器进行控制。
该板子也支持通信中间件,进程间通信(IPC)库,该库针对FPGA版本的处理引擎进行了扩展,使用户通过调用IPC提供的,相对高层次的API函数,管理FPGA 引擎的数据缓冲区和数据传输。IPC利用命名缓冲区(named buffer),同步和数据传输对象,通过掩盖底层硬件细节的方式,将IPC移植到下一代高速串行技术,从而简化系统集成的工作量。
7. 将FPGA和交换网络应用到系统中
随着军事和航空市场的发展,需要在有限的板子空间和电源电源内,设计出更强大的计算机,满足日益增长的计算需求,这将是一个很大的挑战。为了满足更高的需求,将带有交换网络的FPGA集成到系统中是一个可行的解决方案。
在嵌入式国防和航空领域中,对于相对狭小的嵌入式商业市场,客户对计算性能需求的增长超过了摩尔定律预言的处理器性能的增长,雷达和智能信号处理等应用对计算性能要求尤其高。
作为COST供应商,CWCEC公司一直在致力于满足客户日益增长的计算需求。除了考虑系统性能的提升,他们还需要考虑成本问题,成本问题往往决定了实际系统装备数量。以前,在平衡系统性能和有限的资金问题时,客户总是被迫要么自己设计芯片,要么牺牲系统性能和功能。
FPGA曾经由于成本太高和过于复杂不给于考虑,但是今天,它将提供给客户更多的种选择,来满足性能/功能与应用环境/成本的需求。
随着计算能力需求的增加,客户对使用FPGA开发性能更强大的应用越来越感兴趣。与ASIC相比FPGA具有相对灵活和可重配置的优点。以前,单个FPGA元器件要比集成电路芯片(ASIC)昂贵,而且,FPGA也不容易集成到一个大的系统中。
直到现在,还有前端I/O处理等问题仍然局限着FPGA的使用。近些年COST供应商进行了一些探索改进FPGA产品,包括:增加FPGA门数,用于开发和集成用的软件,这些改进使得FPGA 越来越流行。图一展示Viretex-5 LXT最新FPGA,该FPGA为不同平台提供了解决方案。
图一
作为使用FPGA的用户,在选择FPGA用于应用加速之前,需要考虑很多重要的问题。包括:
算法是否容易在FPGA中实现?
从通用处理器转移到FPGA会给系统带来哪些好处?
从FPGA输入和输出的是什么数据流?
我该如何将FPGA集成到我的大系统中并保证其正常工作?
客户的这些问题的答案决定如何将基于FPGA COST解决方案开发的子系统集成进目标系统,快速有效的实现应用算法。对于系统集成,如果采用FPGA方案,第一步需要决定这些子系统的构成是否合适,是否能提高系统性能。
有两个规则指导客户作出决定:算法是否大量采用并行处理?算法是否采用定点运算?例如系统包含1维和2维卷积运算,有很多的滤波器(FIR, IIR, comb等),矩阵分解,数字降频转换,以及一些波速形成等,这样的应用可以使用FPGA实现。系统性能可提高10倍到20倍(实际采用算法不同,提高得倍数也不同)。
当系统希望采用COST FPGA板时,首先要考虑硬件,和板子的I/O系统。对于系统集成商I/O系统是非常重要的,他将决定数据放到FPGA进行处理,然后输出显示或者作进一步处理。
采用高速串行口将FPGA 连接到串行交换网络,是今天的FPGA的重大改进,例如RapidIO。这个发展趋势将提供简单的,高速的,双向数据通道,使得数据可以高速传输。例如,Xilinx公司的Virtex-II Pro, Virtex-4和Virtex-5都支持高速串行口。
举一个例子说明COST FPGA板如何实现串行口链接。下图是Curtiss-Wright公司近来发布的6U 基于VPX总线的CHAMP-FXII(参考图二),板子上有两块Virtex-5 FPGA,每一个FPGA 拥有一个4信道的串行口,连接到板载的串行RapidIO交换芯片上。串行RapidIO交换芯片拥有4个4信道Serial RapidIO口,通往背板组成交换网络。每一个口可以提供双向2.5GB/s带宽。这些高速串行数据通道可以链接像CHAMP-AV6四PowerPC DSP引擎,或VPX-185单板机等其他RapidIO 互联的VPX硬件模块。FPGA物理上集成了Serial RapidIO交换网络,所以数据流可以进和出FPGA,使系统保持高效的处理。
图二
现代高性能FPGA 除了提供逻辑单元外,还提供很多其他特性,如分布式的RAM,
block RAM,数字时钟管理,DSP模块和硬处理核。一些适合在FPGA中实现的算法可能需要很多临时内存用于存储,但是需要的内存数量超过FPGA所能提供的内存,这种情况是非常普遍的。这种情况下需要使用额外内存(这里指SDRAM)。因此,客户需要寻找COST解决方案,使用内存选项(memory option),平衡输入输出数据流带宽,进行高效的存储和取回。
有些算法需要小的,快速的随机内存存取。SRAM适合这种算法。但是,还有一些算法进行大块数据传输,SDRAM比较合适。为了确保适应上述两种算法,客户应选择拥有很多SRAM和SDRAM的bank的COST FPGA板,为附加内存设计和利用提供足够的灵活。
CHAMP-FXII上的每一个FPGA拥有两个SDRMA bank,总共512MB,以及4个SRAM bank,总共32MB。CHAMP-FXII采用的SDRAM双向带宽可以达到2.2GB/s,SRAM双向带宽可以达到4.4GB/s,所以不会产生数据流瓶颈。这些内存是双口的,给客户应用提供更多的灵活性。
选择COST FPGA板另外的关键因素是:
用于中断,客户总线接口,设备控制等的离散I/O
测量板子和处理器温度传感器
测量FPGA应用电流流向的电流传感器
用于FPGA位流存储的SPROM或flash
简化集成工作的FPGA工具
COST FPGA能够提供的开发工具集是仅次于板子硬件的一个重要因素。专用硬件开发工具集是COST解决方案的一个极其重要的因素,因为他将简化,加速应用算法整合到板子硬件过程,加快FPGA板整合进多计算系统的过程。这对算法加速问题尤为重要,因为一般是首先考虑通用处理或者基于DSP处理,然后考虑基于FPGA的处理。
COST板供应商一般提供软件驱动和库,IP块儿及其仿真testbench等开发工具集。有很多第三方IP块儿(例如,www.xilinx.com/ipcenter),但是这些块儿没有经过特殊的优化,不能满足客户的需要。进一步复杂的IP块儿集成目前还没有标准的接口。因此,集成现有商业块儿改进应用性能仍然是很困难的。
为了解决上述问题,一些COST供应商的开发工具集提供优化IP块。例如,Curtiss-Wright的统一Fxtools工具集提供优化的通用内连块接口。这样客户可以专注于实现自己的算法,不需要花费时间优化第三方IP块儿。
很多COST FPGA应用于恶劣环境中。因此,验证IP块儿也应该达到主卡设计的温度范围。这将确保装备时,这些优化过的,验证过的IP块能够工作在宽广的温度范围内,并且成功的满足性能和时序要求(在很多军事系统中温度范围是-40° C 到 85°)。
7.1处理器间通信
系统设计师使用厂商提供的块儿集成应用,并完成仿真后,集成的下一步是建立处理器间通信,应用命令与控制。与PowerPC等通用处理器相比,FPGA缺少指挥数据移动,设置处理模型的资源,以及其他重要的命令和控制功能。
系统工程师们使用外部处理资源解决这些限制。这些外部资源应该拥有丰富的库函数,这些库函数具有高层次的命令功能。系统工程师使用这些乏味的、容易出错的库函数,设置寄存器和创建控制结构体(如高级DMA引擎)。库函数应该提供给系统工程师们简单,易于上手的函数,处理复杂的DMA命令控制,同步和其他系统任务。
使用专门为FPGA设计的高级处理器间通信中间件解决方案是减少集成时间的另一个好方法。中间件通过管理内存映射,DMA引擎建立,终端服务程序和处理器间同步等任务简化集成时间,提供简单的、应用程序级API。
Curtiss-Wright公司的统一IPC软件是一款用于COST FPGA板子的处理器间通信解决方案。统一IPC中间件将缓冲区,信号量和DMA命令抽象成命名对象,就像PowerPC方式一样,因此,可以简化数据传输编码。在系统级调试阶段,处理和缓冲区可能在系统中移来移去,这种情况下使用IPC无需重新编写代码,因为中间件能够自动解决新位置的问题,这是IPC另外一个好处。当使用FPGA用作算法加速时, FPGA更像是系统中的一个处理单元。
处理器与FPGA的搭配,除了原来提到的简化数据传输,还有另外一个好处。例如,Virtex-5尤其适合搭配Freescale的双核8641处理器,因为二者使用相同的RapidIO网络互联,除此,8641还有两个单独的连接通道,连接到Virtex-5。第一个是可选择的映射接口,该接口能够将不同位流源存储到本地的flash,SDRAM内存或者远程文件系统中。通过运行在PowerPC上应用发出指令,迅速将位流加载到FPGA中。这对系统适应多模式要求非常重要的。8641提供的第二个连接是本地命令总线。8641使用专门的命令与控制,寄存器设置等访问该总线,不会破坏进/出FPGA的数据流。
7.2权衡所有因素
准备在一个大而复杂的系统中,使用FPGA作为算法加速时,有很多因素需要权衡。当考虑COST解决方案时,系统集成师应该了解COST供应商解决了哪些问题,能够给集成商带来那些特色和灵活。