Poco不能获取文本时处理
最近通过airtest进行自动化测试时,发现有些控件上面的数值不能通过poco里面的get_text(),或者attr(*args, **kwargs)方法获取到值,比如下图中显示100%这个控件的类型为android.view.View ,是绘制的图片。
要获取图片中的文字,自然想到了文字识别方法。


一、通过snapshot进行截图
注意截图返回的类型为2-tuple,第一个为base64编码的截图数据,第二个参数为类型。
截图时的width可以通过airtest的get_current_resolution()获取当前设备的屏幕分辨率。
snapshot(width=720)[源代码]
Take the screenshot from the target device. The supported output format (png, jpg, etc.) depends on the agent implementation.
| 参数: |
|
|---|---|
| 返回: |
|
| 返回类型: | 2-tuple |
(width, height) = device.get_current_resolution() #获取屏幕宽度、高度
(image_data, type) = poco_new.snapshot(width) #屏幕截取
image = base64.b64decode(image_data) #解码截屏数据
with open('1.jpg', 'wb') as f: #保存截屏为文件
f.write(image)
img = Image.open("1.jpg")
https://blog.csdn.net/wang785994599/article/details/96425280
经查找资料(https://stackoverflow.com/questions/8328198/pil-valueerror-not-enough-image-data)
得知该图片为jpg格式,包括了图片的原始(jpg压缩后的)数据和(jpg)文件头,而frombytes只能读取纯二进制数据,解决方法如下:(image_data, type) = poco_new.snapshot(width) #屏幕截取
image = base64.b64decode(image_data)
img = Image.open(BytesIO(image))二、对图片进行截取
Image.crop(box=None)[source]
Returns a rectangular region from this image. The box is a 4-tuple defining the left, upper, right, and lower pixel coordinate.
This is a lazy operation. Changes to the source image may or may not be reflected in the cropped image. To break the connection, call the load() method on the cropped copy.
| 参数: | box – The crop rectangle, as a (left, upper, right, lower)-tuple. |
|---|---|
| 返回类型: | Image |
| 返回: | An Image object. |
使用Image.crop对图片进行矩形截取,截取参数为矩形左上角和右下角的坐标。
如下图所示,整个屏幕的宽度和高度通过(width, height) = device.get_current_resolution()得到。
需要截取矩形框的x、y坐标信息通过attr('pos')获得,由于得到的信息是指在屏幕上的相对位置,还要分别乘以宽度和高度得到像素信息;矩形框的宽度和高度通过attr('size')获得,也需要分别乘以宽度和高度得到像素信息;
然后计算出矩形框的左上角、右下角坐标,单位为像素。

img = Image.open("1.jpg")
(width, height) = device.get_current_resolution()
(pos_x,pos_y) = content.offspring("xxxxxx").attr('pos')
(size_x, size_y) = poco.offspring("xxxxxx").attr('size')
(size_x, size_y) = (size_x* width, size_y* height)
image_crop = img.crop((pos_x*width - size_x/2,
pos_y*height - size_y/2,
pos_x * width + size_x / 2,
pos_y * height + size_y / 2))
三、对图片进行识别
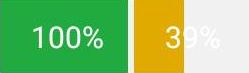

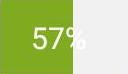
上面是截取得到的数字,可以看到绘图步骤是根据输入的数字,在一个固定高度和宽度的画布上绘制,从左边开始绘制的颜色块颜色根据数值大小颜色不同,颜色块宽度也根据数值大小而变化。在绘制完颜色块后,在图片正中加上百分比数字。
可以看到加的数字与画布底色非常接近,颜色块的颜色和宽度还根据数值变化,这就给数值识别带来了很大的难度。
如果能直接访问数字就好了,可惜poco不能访问到元素的这个属性。为了尝试识别图片中的数字,先把57%这个图片保存到了本地,然后尝试用不同的方法进行识别。
1、直接用tesserocr进行识别
可以用tesserocr或者pytesseract调用tesseract进行OCR(光学字符识别)
识别结果为“7a:”,不仅百分号没有识别正确,5也没有识别出来。
https://www.cnblogs.com/zhangxinqi/p/9297292.html
text = tesserocr.file_to_text('tmp.jpg')
print(text)
text = pytesseract.image_to_string(Image.open('tmp.jpg'))
print(text)2、通过python改变颜色
改变颜色的方法参考下面的文字,文中还提到灰度化和二值化。
这里手动进行了二值化,在RGB值之和大于550时判断为黑色,否则为白色。
灰度化:让像素点矩阵中的每一个像素点都满足下面的关系:R=G=B(就是红色变量的值,绿色变量的值,和蓝色变量的值,这三个值相等),此时的这个值叫做灰度值。
二值化:让图像的像素点矩阵中的每个像素点的灰度值为0(黑色)或者255(白色),也就是让整个图像呈现只有黑和白的效果。在灰度化的图像中灰度值的范围为0~255,在二值化后的图像中的灰度值范围是0或者255。
https://www.jb51.net/article/165410.htm
https://blog.csdn.net/weixin_42170439/article/details/92648390
img = Image.open('tmp.jpg')
array = np.array(img)
for row in range(len(array)):
for col in range(len(array[0])):
total = int(array[row, col][0]) + int(array[row,col][1]) + int(array[row,col][2])
if (total > 550) :
array[row, col] = [0, 0, 0]
else:
array[row, col] = [255, 255, 255]
image = Image.fromarray(array)
image.save('black.jpg')
text = pytesseract.image_to_string(Image.open('black.jpg'),'eng')
print(text)开始以为是图片的对比度不够,绿底白字不好分辨,为了改善识别将图片白色部分找出来变成黑色,其余部分变成白色。这样图片就是黑色和白色的了,如果能够识别,再将画布底色也改为白色。
通过RGB颜色分出来的图片如下图,可以看到57都变成了白底黑字,如果能够识别再将画布部分特殊处理就可以整个数字变为白底黑字。可惜处理后的图片仍然识别成了‘7a’,后面就没有再尝试将画布变为白底了。

3、通过HSV识别颜色
下面的文章通过HSV转换后识别图片颜色获取图片轮廓
https://blog.csdn.net/qq_41895190/article/details/82791426
https://blog.csdn.net/a19990412/article/details/81172426
https://blog.csdn.net/hjxu2016/article/details/77833336
#二值化,不属于color_dict[d][0]~color_dict[d][1]范围的像素变为黑色。属于color_dict[d][0]~color_dict[d][1]范围的像素变为白色。
mask = cv2.inRange(hsv,color_dict[d][0],color_dict[d][1])
cv2.imwrite(d+'.jpg',mask) #保存图片
#将一个灰色的图片,变成要么是白色要么就是黑色。大于规定thresh(127)值就是设置的最大值(255,也就是白色),小于thresh(127)的像素设置为黑色。由于前面已经通过cv2.inRange将图片变为了黑白,所以这里处理后和处理前是一样的。
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1] #
binary = cv2.dilate(binary,None,iterations=2)
#找图片轮廓,cv2.findContours()函数接受的参数为二值图,即黑白的(不是灰度图)。
img, cnts, hiera = v2.findContours(binary.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
既然能够获取图片中的轮廓,则也可以试试获取图片中的数字,根据前面介绍的白色HSV范围是[0,0,221]~[180,30,255],转换的时候发现转换后的图片是全黑的,因此放宽了白色的HSV范围到[0,0,180]~[180,90,255],转换后的图片基本与直接改变颜色得到的图片一致,识别出来的文字还是‘7a’,看来问题出在文字识别上面,不可能这么简单的图片识别不出数字。
frame = cv2.imread('tmp.jpg')
hsv = cv2.cvtColor(frame, cv2.COLOR_RGB2HSV)
mask = cv2.inRange(hsv, np.array([0,0,180]), np.array([180,90,255]))
cv2.imwrite('black' + '.jpg', mask)
text = pytesseract.image_to_string(mask) #Image.open('white.jpg'))
print(text)
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('black' + '.jpg', binary)
text = pytesseract.image_to_string(binary) # Image.open('white.jpg'))
print(text)4、通过画布显示宽度得到大致数字
前面通过OCR识别图片中数字的方法失败了,后来又想到既然颜色块的大小就反映了数字的大小,那可以通过剩余画布所占的百分比反推出颜色块的大小。
通过photoshop获取画布底色为(241,241,241),由于颜色块和画布交界部分画布颜色有渐变部分,所以将画布颜色放宽到(220,220,220),取5~15行的像素进行分析,如果RGB值均大于门限则判断为画布,最后得出颜色块比率为58.6,与数值57比较接近。可以通过该方法定量的判断出数字的大小。
total = 0
white = 0
img = Image.open('tmp.jpg')
array = np.array(img)
for row in range(5, 15):
for col in range(len(array[0])):
total = total + 1
if (array[row, col][0] > 220) and (array[row, col][1] > 220) and (array[row, col][2] > 220):
white = white + 1
rate = 100 - white * 100 / total
四、提升执行速度
1、freeze
根据博文介绍,freeze()得到的是当前poco实例的一个静态副本,用freeze可以加快查找速度
https://blog.csdn.net/saint_228/article/details/89638300
freeze()[源代码]
Snapshot current hierarchy and cache it into a new poco instance. This new poco instance is a copy from current poco instance (self). The hierarchy of the new poco instance is fixed and immutable. It will be super fast when calling dump function from frozen poco. See the example below.
有一点要注意的是,freeze只是将当前结构的静态副本保存,如果通过freeze.snapshot截图,则截的图是snapshot时的时间,而不是freeze时的截图。
frozen_poco = poco.freeze() frozen_poco.snapshot(width)
2、将数据先获取,再集中处理
本来是获取一次数据处理一次,后来改为将数据先存入列表再集中处理,加快了处理速度。
3、尽量少截图
用poco.snapshot截图一次大概要0.2秒,如果多次截图时间肯定会变长。