9.1 正则介绍_grep上
9.2 grep中
9.3 grep下
扩展
把一个目录下,过滤所有*.php文档中含有eval的行
grep -r --include="*.php" 'eval' /data/
在计算机科学中,对“正则表达式”的定义是:它使用单个字符串来描述或匹配一系列符合某个句法规则的字符串。
常用的工具有grep , sed ,awk 等,其中grep ,sed ,和 awk都是针对文本的进行操作的。
一,grep工具的使用
命令格式为 grep [-cinvABC] ‘word' filename
其常用选项如下所示:
1,-c :表示打印符合要求的行数
2,-i :表示忽略大小写
3,-n : 表示输出符合要求的行及其行号
4,-v :表示打印不符合要求的行
5,-A :后面跟一个数字(有无空格都可以),例如-A2表示打印符合要求的行以及下面两行。
6,-B :后面跟一个数字,例如-B2表示打印符合要求的行以及上面两行。
7,-C :后面跟一个数字,例如-C2表示打印符合要求的行以及上下各两行。
二,-A2会把包含halt的行以及这行下面的两行都打印出来:

说明:在CentOS7系统中,grep默认帮我们把匹配到的字符串标注为红色,这点还是挺贴心的。其实大家可以用which 命令查一下grep,会发现grep其实是grep——color=auto,这个选项就是颜色显示。
-B2会把包含halt的行以及这行上面的两行都打印出来

-C会把包含halt的行以及这行上下两行都打印出来

二,过滤出带有某个关键词的行,并输入行号,如下

说明:前面的数字显示为绿色,表示行号
三,过滤出不带有某个关键词的行,并输出行号,如下:

四,过滤出所有包含数字的行,如下:

说明:只要有一个数字就算是匹配到了
五,过滤出所有不包含数字的行,如下

说明:和上一列得结果正好相反,只要包含一个数字,就不显示。
六,过滤掉所有以#开头的行,如下:

说明:这里面是含有空行的。
七,过滤掉所有空行和以#开头的行,如下:

说明:在正则表达式中,^表示行的开始,$表示行的结尾,那么空行则可以用^$表示。如何打印出不以英文字母开头的行呢?我们先来自定义一个文件,如下所示:
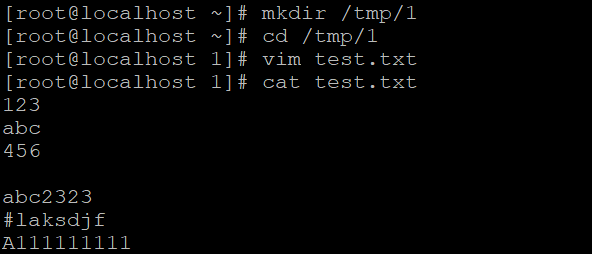

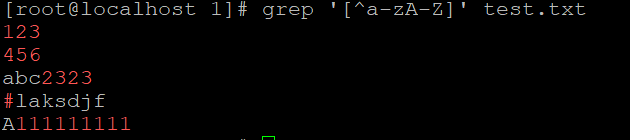
说明:[]的应用: 如果是数字就用[0-9]这样的形式(当遇到类似[15]的形式时,表示只含有1或者5),
如果要过滤数字以及大小写字母,则要写成类似[0-9a-zA-Z]的形式。
另外,[^字符]表示除[]内字符之外的字符。请注意,把^写到方括号里面和外面是由区别的。
八,过滤出任意一个字符和重复字符,如下:

. 表示任意一个字符,上例中,r.o表示把r与o之间有一个任意字符的行过滤出来。

*表示零个或多个*前面的字符。上例中,ooo*表示oo,ooo,oooo.....或者更多的o

上例中, .*表示零个或多个任意字符,空行也包含在内,它会把/etc/passwd文件里面的所有行都匹配到,你也可以不加 |wc -l 看一下效果。
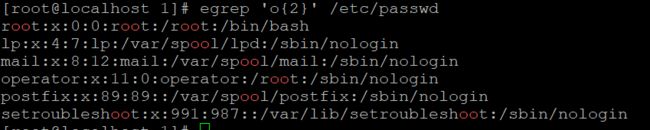
九,指定要过滤出的字符出现次数,如下

这里用到的符号 {},其内部为数字,表示前面的字符要重复的次数。需要强调的是,{}左右都需要加上转义字符 \。另外,使用“{ } 还可以表示一个范围,具体格式为 {n1,n2},其中n1 除grep工具外,还常常会用到egrep这个工具,后者是前者的扩展版本,可以完成grep不能完成的工作。 先把test.txt编辑成如下 和grep不同,这里egrep使用的是符号 + ,它表示匹配1个或多个+前面的字符,这个”+“是不支持被grep 直接使用的。包括上面 的 { } ,也是可以直接被egrep使用,而不用加 \转义: 
九(1),过滤出一个或多个指定的字符,如下:



九(2),过滤出零个或一个指定的字符,如下:



九(3),过滤出字符串1或者字符串2,如下

九(4),egrep中()的应用,如下:

这里用()表示一个整体,上列中会把包含rooo或者roto的行过滤出来,另外也可以把()和其他符号组合在一起,例如(oo)+就表示1个或者多个oo。如下: