自己动手写一个小型的TCP/IP协议
TCP/IP协议大家都知道,但真正理解的人不多,不如动手写一个小型的看看。
我知道看书很枯燥,看不懂,还打击大家的信心,不是我们的脑袋不如人,是我们的方法错了。
一切的技术都从应用中发展而来,所以要从下往上走,先动手完成一个任务吧。
需要准备的前提知识
linux驱动程序知识:原本理解网络协议是不一定非要懂linux驱动程序的,但由于这个例子是使用linux虚拟网卡作为基础,为了看懂源代码,需要简单了解。目前没有又短小又清楚的好文章推荐,以后可以补充。
虚拟网卡 TUN/TAP 驱动程序设计原理
http://www.ibm.com/developerworks/cn/linux/l-tuntap/
上面这个网址是我认为讲解比较清楚全面的文章,推荐一下。太网报头格式(L2层),ARP报头格式,ARP协议功能和实现流程。下面这个英文网址的文章我认为讲解还算比较好。
-
- 首先明白所谓7层协议栈各层的报头。这里不准备7层全部讲,就讲三层,包括以太网报头(L1层),IP报头(L2层),TCP/UDP(L3层)报头。讲多了,反而不容易理解。从一个个具体应用总结出整个协议栈的结构。
- 然后再来看一个实际截获的数据包。
- 最后看一下整个数据包,包括数据和三个报头,是如何生成的。分别由哪些协议生成和生成次序。包包生成之后,交给以太网驱动程序发走。

图1:IP报头结构
除掉 IP Option这个字段, IP报头一共20个字节,各字段的含义如上图所示。
下面再看一个实际截获的UDP数据包:

图2:一个实际截获的UDP数据包
- 以太网报头
有一个“类型”字段(上面的例子中是0800,代表是从IP协议层传送过来的数据包),其中各类型值的含义分别如下:
0x0600 XNS
0x0800 IP
0x0806 ARP
0x6003 DECnet
- IP报头
红色框框里面就是20个字节的IP报头,各字段的含义要仔细看。 UDP报头
IP报头
紧接着后面8字节的UDP报头。它是被上层的UDP协议加上去的。首先数据(有效载荷)当然是应用层(打比方EPSON打印机应用软件)生成的。(上面这个图是我的EPSON打印机软件和打印机的通信包)。EPSON打印机应用软件生成一个数据包,就丢给UDP层(L3),这个UDP协议就会在数据前面加个一个UDP的报头(上图中的蓝色框框)。然后UDP协议接着往下传递,传到了IP层(L2层),这个IP协议呢,又在前面加了一个IP报头。又接着往下传递,传递到了以太网卡层(L1层),又在前面加了一个以太网报头,然后整个数据包交给以太网驱动程序,这个数据包包括三个报头和要发送的数据(有效载荷),最后以太网驱动程序把整个数据包通过网线发送出去。
看完一个具体的例子,再来看整个协议栈。

ARP协议(Address Resolution Protocol )是一个特定的网络标准协议。它是可选的。工作在L2层 。
地址解析协议负责将更高级别的协议地址(IP地址)转换为物理网络地址。
http://network-panda.blogspot.jp/2015/06/brief-introduction-to-protocols-1-arp.html
http://www.tcpipguide.com/free/t_ARPMessageFormat.htm
当主机收到ARP数据包(无论是广播请求或点对点的回复),接收的设备驱动程序把这个包发送到ARP协议模块,ARP协议模块按如下的流程处理:
好了,到此为止,我认为该准备的基础知识已经准备好了。接下来动手实验吧。
让我们写一个TCP / IP协议栈,1:以太网、ARP
自己写TCP / IP协议栈可能看起来像一个艰巨的任务。事实上,TCP已经积累了超过三十年的寿命的规范。
然而核心规范,看起来是紧凑的,重要组成部分是:TCP报头解析、状态机、拥塞控制和重传超时计算。
最常用的2层和3层的协议,分别在以太网和IP层,相对TCP的复杂性而言显得简单很多。
在这个博客系列,我们将在Linux上实现一个最小的用户空间TCP / IP协议栈。
这些是纯粹的学习用,要深入学习,请更深层的学习网络和系统编程。
内容
TUN/TAP设备
以太网帧格式
以太网帧分析
地址解析协议
地址解析算法
结论
来源
TUN/TAP设备
为了拦截来自于内核的底层的网络数据,我们将使用一个TUN/TAP设备。
[Connie Note]
tun/tap 驱动程序实现了虚拟网卡的功能,tun表示虚拟的是点对点设备,tap表示虚拟的是以太网设备,这两种设备针对网络包实施不同的封装。
利用tun/tap 驱动,可以将tcp/ip协议栈处理好的网络分包传给任何一个使用tun/tap驱动的进程,由进程重新处理后再发到物理链路中。
简单说,一个TUN/TAP设备通常是由网络用户空间的应用程序用来分别操纵L3或L2层的数据。
一个流行的例子是tunneling,其中一个包被包裹在另一个数据包的有效载荷中。
TUN/TAP设备的优势是,它们很容易在用户空间的程序建立,它们已经被用于许多程序,如OpenVPN。
由于我们要从L2层建立自己的网络协议堆栈,我们需要一个TAP设备。我们那样实例化的那样:
/ *
*从内核文件/网络/ tuntap.txt取
*/
int tun_alloc(char *dev)
{
struct ifreq ifr;
int fd, err;
if( (fd = open("/dev/net/tap", O_RDWR)) < 0 ) {
print_error("Cannot open TUN/TAP dev");
exit(1);
}
CLEAR(ifr);
/* Flags: IFF_TUN - TUN device (no Ethernet headers)
* IFF_TAP - TAP device
*
* IFF_NO_PI - Do not provide packet information
*/
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
if( *dev ) {
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
if( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ){
print_error("ERR: Could not ioctl tun: %s\n", strerror(errno));
close(fd);
return err;
}
strcpy(dev, ifr.ifr_name);
return fd;
}接下来,返回的文件描述符fd可以用来读写数据到虚拟设备的以太网缓冲。
标志IFF_NO_PI是至关重要的,否则,我们会添加到以太网帧不必要的数据包信息。你可以看看内核的设备驱动程序的源代码,并自己验证。
以太网帧格式
众多不同的以太网网络技术连接计算机到局域网(LANs)的主干网。与所有的物理技术一样,以太网标准已经发生巨大变化,从1980年由Digital Equipment公司和英特尔和施乐出版的第一个方案。
以太网的第一个版本是在今天的标准看来是很慢的,大概10Mb/s,采用半双工通信,这意味着你可以发送或接收数据,但不能在同一时间。这就是为什么一个媒体访问控制(Media Access Control )(MAC)协议必须被纳入组织的数据流。即使到今天,如果在半双工模式下运行一个以太网接口,载波侦听多路访问冲突检测(CSMA/CD)依然是必须的,因为MAC。
采用双绞线布线的100BASE-T以太网标准使全双工通信成为可能,也使通讯有了更高的吞吐速度。此外,同时增加了以太网交换机的人气,让CSMA/CD过时。
IEEE 802.33工作组维护着不同的以太网标准。
下一步,我们将看看以太网帧头。它可以被声明为一个C的结构体:
#include DMAC和Smac是相当不言自明的项目。它们分别包含通信方(目的和源)的地址。
重载项目ethertype,是一种2-octet项目,它的含义取决于它的值,可以是有效载荷的长度,也可以使有效载荷的类型。具体来说,如果该字段的值大于或等于1536,该字段表示有效载荷的类型(如IPv4,ARP)。如果值小于该值,则字段表示有效负载的长度。
ethertype字段后,以太网帧中可以有几种不同的标签。这些标签可以用来描述虚拟局域网(VLAN)、服务质量(QoS)的帧类型。以太网帧标签被排除在我们这次的代码之外,所以在我们的协议声明中,相应的字段也没有出现。
有效载荷字段包含指向以太网帧有效负载的指针。在我们的例子中,这将包含一个ARP或IPv4数据包。如果有效负载长度小于所需的最小48字节(不带标签),则将字节数追加到有效负载的最末端,以满足需求。
我们还需要包括if_ether.h 这个Linux头文件,它提供ethertypes和十六进制值之间的映射。
最后,以太网帧格式还包括帧校验字段,它是用循环冗余校验(CRC)来检查帧的完整性。在我们的例子中,我们将省略这一处理。
以太网帧的解析
结构声明的packed属性是一个细节,它告诉编译器不要优化数据结构的4字节对齐的内存布局。使用这个属性是由于我们“解析”协议缓冲区的方式,这是一种适当的协议结构数据缓冲区:
struct eth_hdr hdr = (struct eth_hdr ) buf;
一种便携式,稍微费力的方法,将手动序列化协议数据。这样,编译器可以自由地添加填充字节,以更好地适应不同处理器的数据对齐要求。
分析和处理以太网帧缓存的总体方案是简单的:
if (tun_read(buf, BUFLEN) < 0) {
print_error("ERR: Read from tun_fd: %s\n", strerror(errno));
}
struct eth_hdr *hdr = init_eth_hdr(buf);
handle_frame(&netdev, hdr);handle_frame功能使根据以太帧的ethertype 字段的值,决定其下一步的动作。
地址解析协议
地址解析协议(ARP)是用于动态映射一个48位的以太网地址(MAC地址)到协议地址(例如IPv4地址)。这里的关键是,ARP需要对应很多不同的L3协议,不仅仅是IPv4,还有像CHAOS这样的协议。这些被声明成16比特的协议地址。
通常的情况是,你知道在你的局域网中的一些服务的IP地址,但要建立实际的通信,也需要知道硬件地址(MAC)。因此,ARP是用来广播查询网络,要求IP地址的所有者报告其硬件地址。
ARP数据包的格式相对比较简单:
struct arp_hdr
{
uint16_t hwtype;
uint16_t protype;
unsigned char hwsize;
unsigned char prosize;
uint16_t opcode;
unsigned char data[];
} __attribute__((packed));ARP报头(arp_hdr)包含一个2-octet字段 hwtype,它取决于链路层类型。这是在我们例子中,它的值一直是 0x0001。
2-octet字段protype表示协议类型。在我们的例子中,这是IPv4,相应值是0x0800。
hwsize 和 prosize字段都是1-octet大小,它们分别表示硬件尺寸和协议字段。在我们的例子中,这些是6字节的MAC地址,和4个字节的IP地址。
2-octet字段opcode 表示ARP报文类型。它可以是ARP请求(1)、ARP应答(2),RARP请求(3)或(4)RARP应答。
data字段包含ARP报文的实际载荷,并在我们的例子中,这将包含IPv4的具体信息:
struct arp_ipv4
{
unsigned char smac[6];
uint32_t sip;
unsigned char dmac[6];
uint32_t dip;
} __at字段smac和dmac分别包含发送者和接收者的6字节的MAC地址。 sip 和 dip分别包含发送者和接收者的IP地址。
地址解析算法
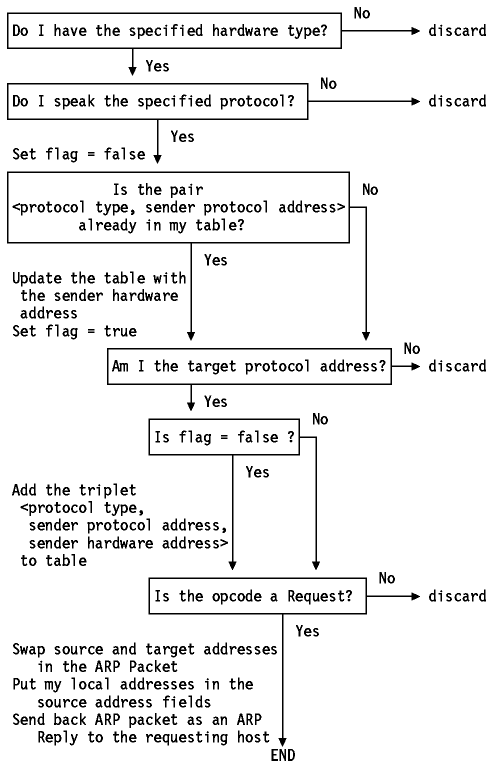
原始规范描述了这个简单的算法来解决地址的解析
?Do I have the hardware type in ar$hrd?
Yes: (almost definitely)
[optionally check the hardware length ar$hln]?Do I speak the protocol in ar$pro?
Yes:
[optionally check the protocol length ar$pln]
Merge_flag := false
If the pair is
already in my translation table, update the sender
hardware address field of the entry with the new
information in the packet and set Merge_flag to true.
?Am I the target protocol address?
Yes:
If Merge_flag is false, add the triplet to
the translation table.
?Is the opcode ares_op$REQUEST? (NOW look at the opcode!!)
Yes:
Swap hardware and protocol fields, putting the local
hardware and protocol addresses in the sender fields.
Set the ar$op field to ares_op$REPLY
Send the packet to the (new) target hardware address on
the same hardware on which the request was received.
即,翻译表用于存储ARP协议的结果,使主机可以看看他们是否已经在他们的高速缓存条目。这避免了冗余ARP请求滥发网络
该算法在arp.c中实现了.
最后,一个ARP实现最终的考验就是看它是否正确的回复ARP请求
[saminiir@localhost lvl-ip]$ arping -I tap0 10.0.0.4
ARPING 10.0.0.4 from 192.168.1.32 tap0
Unicast reply from 10.0.0.4 [00:0C:29:6D:50:25] 3.170ms
Unicast reply from 10.0.0.4 [00:0C:29:6D:50:25] 13.309ms[saminiir@localhost lvl-ip]$ arp
Address HWtype HWaddress Flags Mask Iface
10.0.0.4 ether 00:0c:29:6d:50:25 C tap0
内核的网络堆栈识别了从我们自定义的网络协议栈来的ARP应答,填充它的ARP缓存中的虚拟网络设备的条目。成功!
结论
以太网帧的处理和ARP的最小实现相对容易,可在几行代码完成。而鼓励意义是相当高的,因为你可以在Linux主机的ARP缓存有自己制作的以太网设备!
该项目的源代码可以在GitHub找到。
在接下来的文章中,我们将继续实现 ICMP echo和 reply (ping) 和IPv4数据包解析。
如果你喜欢这个文章,你可以分享给你的粉丝,并在Twitter上跟踪我!