作者|SUBHASH MEENA
编译|VK
来源|Analytics Vidhya
概述
-
假设检验是统计学、分析学和数据科学中的一个关键概念
-
了解假设检验的工作原理、Z检验和t检验之间的区别以及其他统计概念
介绍
冠状病毒大流行使我们大家都成了一个统计学家。我们不断地核对数字,对大流行将如何发展做出自己的假设,并对何时出现“高峰”提出假设。
不仅是我们在进行假设构建,媒体也在这方面蓬勃发展。
几天前,我读到一篇新闻文章,其中提到这次疫情“可能是季节性的”,在温暖的环境下会有所缓解:
所以我开始想,关于冠状病毒,我们还能假设什么呢?
- 成人是否更容易受到冠状病毒爆发的影响?
- 相对湿度如何影响病毒的传播?
有什么证据支持这些说法,我们如何检验这些假设呢?
作为一个统计爱好者,所有这些问题都挖掘了我对假设检验基本原理的旧知识。本文将讨论假设检验的概念以及Z检验与t检验的区别。
然后,我们将使用COVID-19案例研究总结我们的假设检验学习。
目录
-
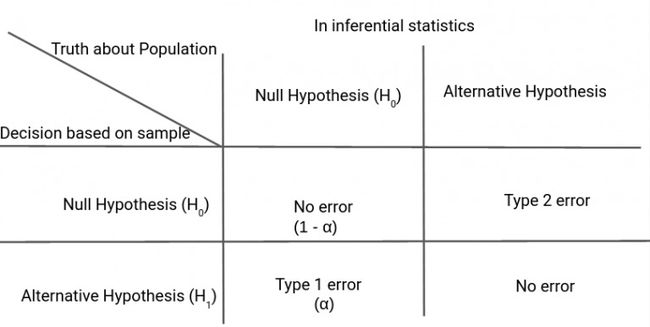
假设检验基础
- 基本概念-零假设、替代假设、类型1错误、类型2错误和显著性水平
- 进行假设检验的步骤
- 定向假设
- 非定向假设检验
-
什么是Z检验?
- 单样本Z检验
- 双样本Z检验
-
什么是t检验?
- 单样本t检验
- 双样本t检验
-
Z检验和t检验的决定
-
案例研究:Python冠状病毒的假设检验
假设检验基础

让我们举一个例子来理解假设检验的概念。
一个人因刑事犯罪正在接受审判,法官需要对他的案件作出判决。现在,在这种情况下有四种可能的组合:
-
第一种情况:此人是无辜的,法官认定此人是无辜的
-
第二种情况:此人无罪,法官认定此人有罪
-
第三种情况:此人有罪,法官认定此人无罪
-
第四种情况:此人有罪,法官认定此人有罪
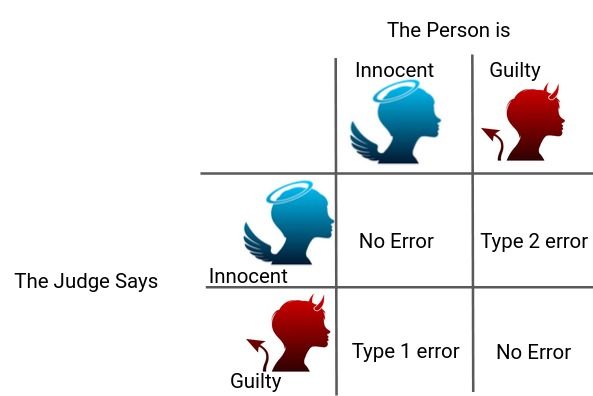
正如你可以清楚地看到的,在判决中有两种类型的错误。
- 第一种错误:当判决是针对无辜的人时
- 第二种错误:当判决是有利于有罪的人时
根据无罪推定,该人在被证明有罪之前被视为无罪。这意味着法官必须找到使他“毫无疑问”的证据。
这种“毫无疑问”的现象可以理解为概率(法官判定有罪|人无罪)应该很小。
假设检验的基本概念实际上相当类似于这种情况。
我们认为零假设是正确的,直到我们找到有力的证据反对它。那么。我们接受另一种假设。
我们还确定了显著性水平(⍺),这可以理解为(法官判定有罪|人是无罪的)在前面的例子中的概率。
因此,如果⍺较小,则需要更多的证据来拒绝零假设。别担心,我们稍后会用一个案例来讨论所有这些。
进行假设检验的步骤
进行假设检验有四个步骤:
-
设定假设
-
设定决策的重要程度和标准
-
计算测试统计
-
做决策
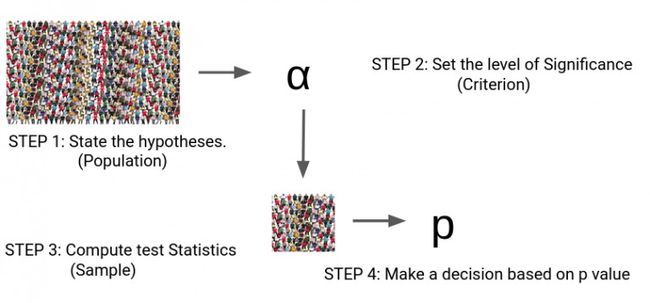
步骤1到步骤3是非常不言而喻的,但是我们可以根据什么在步骤4中做出决定?这个p值表示什么?
我们可以把这个p值理解为衡量辩护律师论点的标准。如果p值小于⍺,则拒绝零假设;如果p值大于⍺,则不拒绝零假设。
临界值,p值
让我们用正态分布的图形表示来理解假设检验的逻辑。
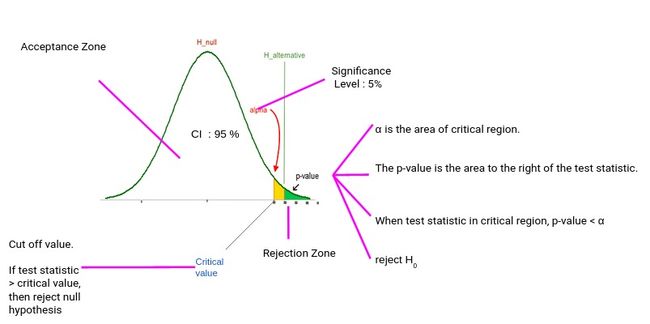
通常,我们将显著性水平设置为10%、5%或1%。
如果我们的测试分数在可接受范围内,我们就不能拒绝零假设。如果我们的测试分数在临界区,我们拒绝零假设,接受替代假设。
临界值是验收区和拒收区之间的截止值。我们将我们的测试分数与临界值进行比较,如果测试分数大于临界值,则意味着我们的测试分数位于拒绝区域,我们拒绝零假设。
另一方面,如果测试分数小于临界值,则意味着测试分数位于接受区,我们无法拒绝零假设。
但是,当我们可以根据测试分数和临界值拒绝/接受假设时,为什么我们需要p值?
p值的好处是我们只需要一个值就可以对假设做出决定。我们不需要计算两个不同的值,比如临界值和测试分数。
使用p值的另一个好处是,我们可以通过直接将其与显著性水平进行比较,在任何期望的显著性水平上进行测试。

这样我们就不需要计算每个显著性水平的考试分数和临界值。我们可以得到p值,并直接与显著性水平进行比较。
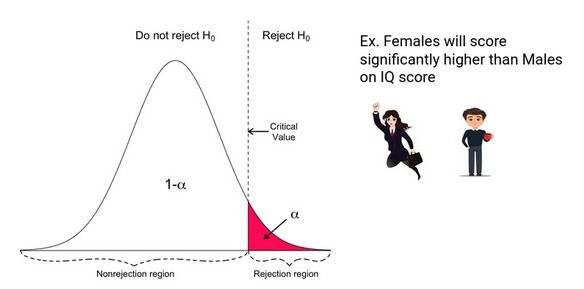
定向假设
在定向假设中,如果测试分数太大(右尾的测试分数太小,左尾的测试分数太小),则会拒绝零假设。因此,这种测试的拒绝区域由一个部分组成。
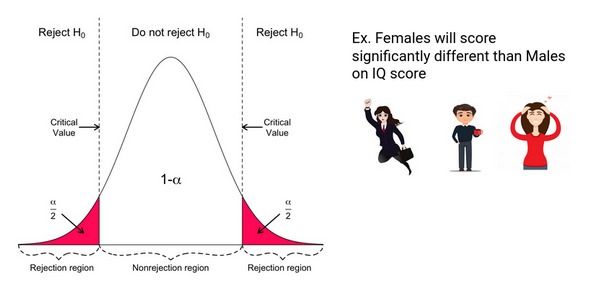
非定向假设
在非定向假设检验中,如果检验分数太小或太大,则拒绝零假设。因此,这种测试的拒绝区域由两部分组成:一部分在左侧,一部分在右侧。
什么是Z检验?
Z检验是检验假设的统计方法,当:
-
我们知道人口的变化,或者
-
我们不知道总体方差,但我们的样本量很大n≥30
如果样本量小于30且不知道总体方差,则必须使用t检验。
单样本Z检验
当我们想比较样本均值和总体均值时,我们执行单样本Z检验。
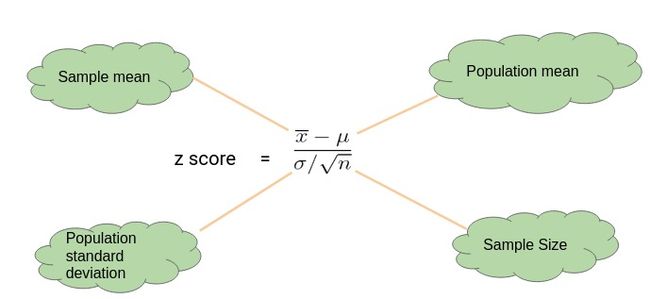
下面是一个了解单样本Z检验的示例
假设我们需要确定女生在考试中的平均分是否高于600分。
- 我们得到的信息是女生成绩的标准差是100。
- 因此,我们采用随机抽样的方法收集了20名女生的数据,并记录她们的成绩。
- 最后,我们还将⍺值(显著性水平)设置为0.05。

在本例中:
-
女生的平均分是641分
-
样本的大小是20
-
平均是600
-
标准差为100

由于P值小于0.05,我们可以拒绝零假设,并根据我们的结果得出结论,女孩平均得分高于600。
双样本Z检验
当我们想要比较两个样本的平均值时,我们执行两个样本的Z检验。
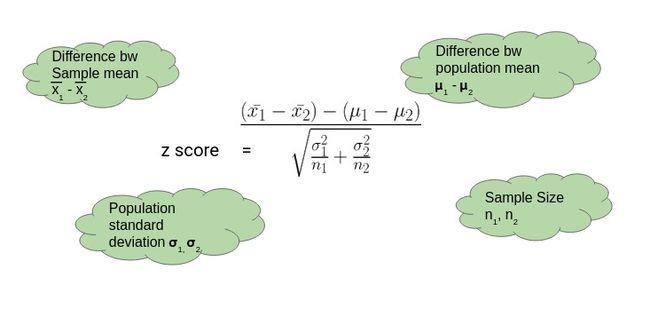
下面是一个了解双样本Z检验的示例
这里,假设我们想知道女生的平均分是否比男生高出10分。
- 我们得到的信息是,女生成绩的标准差是100,男生成绩的标准差是90。
- 然后采用随机抽样的方法收集20名女生和20名男生的数据,记录她们的成绩。
- 最后,我们还将⍺值(显著性水平)设置为0.05。

在本例中:
-
女孩的平均分(样本平均值)是641
-
男孩的平均分(样本平均值)为613.3
-
女生标准差为100
-
男生标准差是90
-
男女样本量均为20
-
平均分差异是10

因此,我们可以根据P值得出结论,我们不能拒绝零假设。我们没有足够的证据得出这样的结论:女生的平均分比男生高出10分。很简单,对吧?
什么是t检验?
t检验是检验假设的一种统计方法,当:
-
我们不知道总体方差
-
我们的样本量很小,n < 30
一个样本的t检验
当我们想要比较样本均值和总体均值时,我们执行一个单样本t检验。与Z检验的不同之处在于,我们这里没有关于总体方差的信息。
在这种情况下,我们使用样本标准差代替总体标准差。
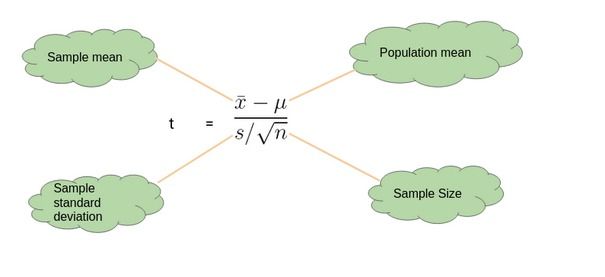
下面是一个了解单样本t检验的示例
假设我们想确定女生平均考试成绩是否超过600分。我们没有与女孩分数的方差(或标准差)相关的信息。为了进行t检验
- 我们随机收集了10名有分数的女孩的数据
- 选择我们的⍺值(显著性水平)为0.05进行假设检验。

在本例中:
-
女生的平均分是606.8分
-
样本大小是10
-
平均分是600
-
样本的标准差为13.14

我们的P值大于0.05,因此我们无法拒绝零假设,也没有足够的证据来支持这样的假设:平均来说,女孩在考试中的得分超过600分。
双样本t检验
当我们想要比较两个样本的平均值时,我们执行双样本t检验。

下面是一个理解双样本t检验的例子
这里,假设我们想确定,在考试中,男生的平均分数是否比女生高出15分。我们没有与女孩或男孩分数的方差(或标准差)相关的信息。为了进行t检验
- 我们随机收集了10名男女学生的成绩数据
- 我们选择⍺值(显著性水平)为0.05作为假设检验的标准

在本例中:
-
男生的平均分是630.1
-
女生的平均分是606.8分
-
平均相差15分
-
男生成绩的标准差是13.42
-
女生成绩的标准差为13.14

因此,P值小于0.05,因此我们可以拒绝零假设,并得出结论:在考试中,男孩平均比女孩多15分。
Z检验和T检验的决定
那么我们什么时候应该做Z检验,什么时候应该做t检验呢?如果我们想掌握统计学,这是我们需要回答的一个关键问题。
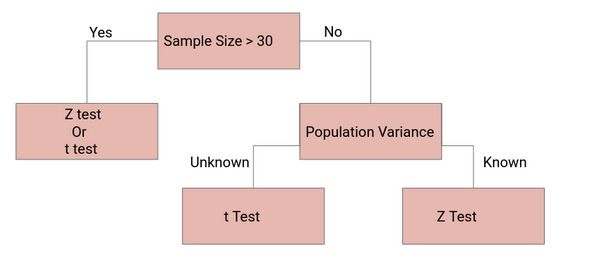
如果样本量足够大,那么Z检验和t检验将得出相同的结果。对于大样本,样本方差是对总体方差的较好估计,因此即使总体方差未知,我们也可以使用样本方差的Z检验。
同样,对于大样本,我们有很高的自由度。由于t分布接近正态分布,z分和t分之间的差异可以忽略不计。
案例研究:用Python对冠状病毒进行假设检验
现在让我们为冠状病毒数据集实现两个样本Z测试。让我们把理论知识付诸实践,看看能不能做好。你可以在这里下载数据集。
https://drive.google.com/file/d/1SJHiTq9QH3GX4CHKtODY3pcmmtxx0bB9/view?usp=sharing
这个数据集取自John Hopkin的存储库,你可以在这里找到它的链接。
https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_daily_reports
此数据集具有以下特征:
- Province/State
- Country/Region
- Last Update
- Confirmed
- Deaths
- Recovered
- Lattitude
- Longitude
我们还使用Python的Weather API-Pyweatherbit添加了纬度和经度的温度和湿度特性。
关于COVID-19的一个普遍看法是,温暖的气候对日冕爆发更有抵抗力,我们需要通过假设检验来验证这一点。那么,我们的零假设和替代假设是什么呢?
-
零假设:温度不影响COV-19的爆发
-
替代假设:温度确实影响COV-19的爆发
注:在我们的数据集中,温度低于24表示寒冷气候,高于24表示炎热气候。
import pandas as pd
import numpy as np
corona = pd.read_csv('Corona_Updated.csv')
corona['Temp_Cat'] = corona['Temprature'].apply(lambda x : 0 if x < 24 else 1)
corona_t = corona[['Confirmed', 'Temp_Cat']]
def TwoSampZ(X1, X2, sigma1, sigma2, N1, N2):
from numpy import sqrt, abs, round
from scipy.stats import norm
ovr_sigma = sqrt(sigma1**2/N1 + sigma2**2/N2)
z = (X1 - X2)/ovr_sigma
pval = 2*(1 - norm.cdf(abs(z)))
return z, pval
d1 = corona_t[(corona_t['Temp_Cat']==1)]['Confirmed']
d2 = corona_t[(corona_t['Temp_Cat']==0)]['Confirmed']
m1, m2 = d1.mean(), d2.mean()
sd1, sd2 = d1.std(), d2.std()
n1, n2 = d1.shape[0], d2.shape[0]
z, p = TwoSampZ(m1, m2, sd1, sd2, n1, n2)
z_score = np.round(z,8)
p_val = np.round(p,6)
if (p_val<0.05):
Hypothesis_Status = 'Reject Null Hypothesis : Significant'
else:
Hypothesis_Status = 'Do not reject Null Hypothesis : Not Significant'
print (p_val)
print (Hypothesis_Status)
0.180286
Do not reject Null Hypothesis : Not Significant
因此。我们没有证据否定我们的零假设,即温度不影响COV-19的爆发。
虽然我们无法找到温度对COV-19的影响,但这个问题只是作为我们在本文中所学的概念性理解。COVID-19数据集的Z检验有一定的局限性:
-
样本数据可能不能很好地代表人口数据
-
样本方差可能不是总体方差的好估计量
-
一个州应对这种流行病的能力的变化
-
社会经济原因
-
某些地方的早期突破
-
一些国家可能出于地缘政治原因而隐瞒这些数据
因此,我们需要更加谨慎,进行更多的研究,以确定这种流行病的模式。
结尾
本文采用逐步回归的方法,对假设检验、1型误差、2型误差、显著性水平、临界值、p值、非定向假设、定向假设、Z检验和t检验的基本原理进行了研究,并对一个冠状病毒病例进行了两样本Z检验。
原文链接:https://www.analyticsvidhya.com/blog/2020/06/statistics-analytics-hypothesis-testing-z-test-t-test/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/