秒杀系统架构分析与实战~未整理完
https://mp.weixin.qq.com/s?__biz=MzAxNTY1NjQzMA==&mid=401277709&idx=3&sn=cae57ddab69bea54f08430278072164c&scene=21#wechat_redirect
1、秒杀技术挑战
1、对现有网站业务造成冲击
秒杀活动只是网站营销的一个附加活动,这个活动具有时间短,并发访问量大的特点,如果和网站原有应用部署在一起,必然会对现有业务造成冲击,稍有不慎可能导致整个网站瘫痪。
解决方案: 将秒杀系统独立部署,甚至使用独立域名,使其与网站完全隔离。
2、高并发下的应用、数据库负载
用户在秒杀开始前,通过不停刷新浏览器页面以保证不会错过秒杀,这些请求如果按照一般的网站应用架构,访问应用服务器、连接数据库,会对应用服务器和数据库服务器造成负载压力。
解决方案: 重新设计秒杀商品页面,不使用网站原来的商品详细页面,页面内容静态化,用户请求不需要经过应用服务。
3、突然增加的网络及服务器带宽
假设商品页面大小200K(主要是商品图片大小),那么需要的网络和服务器带宽是2G(200K×10000),这些网络带宽是因为秒杀活动新增的,超过网站平时使用的带宽。
解决方案: 因为秒杀新增的网络带宽,必须和运营商重新购买或者租借。为了减轻网站服务器的压力,需要将秒杀商品页面缓存在CDN,同样需要和CDN服务商临时租借新增的出口带宽。
4、直接下单
秒杀的游戏规则是到了秒杀才能开始对商品下单购买,在此时间点之前,只能浏览商品信息,不能下单。而下单页面也是一个普通的URL,如果得到这个URL,不用等到秒杀开始就可以下单了。
解决方案: 为了避免用户直接访问下单页面URL,需要将改URL动态化,即使秒杀系统的开发者也无法在秒杀开始前访问下单页面的URL。办法是在下单页面URL加入由服务器端生成的随机数作为参数,在秒杀开始的时候才能得到。
5、减库存的操作
有两种选择,一种是拍下减库存 另外一种是付款减库存;目前采用的“拍下减库存”的方式,拍下就是一瞬间的事,对用户体验会好些。
6、库存会带来“超卖”的问题:售出数量多于库存数量
由于库存并发更新的问题,导致在实际库存已经不足的情况下,库存依然在减,导致卖家的商品卖得件数超过秒杀的预期。
方案: 采用乐观锁
update auction_auctions setquantity = #inQuantity#where auction_id = #
2、秒杀架构原则
1、尽量将请求拦截在系统上游
传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小【一趟火车其实只有2000张票,200w个人来买,基本没有人能买成功,请求有效率为0】。
2、读多写少的常用多使用缓存
这是一个典型的读多写少的应用场景【一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%】,非常适合使用缓存。
3 秒杀架构设计
秒杀系统为秒杀而设计,不同于一般的网购行为,参与秒杀活动的用户更关心的是如何能快速刷新商品页面,在秒杀开始的时候 抢先进入下单页面,而不是商品详情等用户体验细节,因此秒杀系统的 页面设计应尽可能简单。
商品页面中的购买按钮只有在秒杀活动开始的时候才变亮,在此之前及秒杀商品卖出后,该按钮都是灰色的,不可以点击。
下单表单也尽可能简单,购买数量只能是一个且不可以修改,送货地址和付款方式都使用用户默认设置,没有默认也可以不填,允许等订单提交后修改;只有第一个提交的订单发送给网站的订单子系统,其余用户提交订单后只能看到秒杀结束页面。
要做一个这样的秒杀系统,业务会分为两个阶段,第一个阶段是秒杀开始前某个时间到秒杀开始, 这个阶段可以称之为准备阶段,用户在准备阶段等待秒杀; 第二个阶段就是秒杀开始到所有参与秒杀的用户获得秒杀结果, 这个就称为秒杀阶段吧。
3.1 前端层设计
首先要有一个展示秒杀商品的页面, 在这个页面上做一个秒杀活动开始的倒计时, 在准备阶段内用户会陆续打开这个秒杀的页面, 并且可能不停的刷新页面。这里需要考虑两个问题:
第一个是秒杀页面的展示
我们知道一个html页面还是比较大的,即使做了压缩,http头和内容的大小也可能高达数十K,加上其他的css, js,图片等资源,如果同时有几千万人参与一个商品的抢购,一般机房带宽也就只有1G~10G, 网络带宽就极有可能成为瓶颈,所以这个页面上各类静态资源 首先应分开存放,然后放到cdn节点上分散压力,由于CDN节点遍布全国各地,能缓冲掉绝大部分的压力,而且还比机房带宽便宜~
第二个是倒计时
出于性能原因这个一般由js调用客户端本地时间,就有可能出现客户端时钟与服务器时钟不一致,另外服务器之间也是有可能出现时钟不一致。客户端与服务器时钟不一致可以采用客户端定时和服务器同步时间,这里考虑一下性能问题,用于同步时间的接口由于不涉及到后端逻辑,只需要将当前web服务器的时间发送给客户端就可以了,因此速度很快,就我以前测试的结果来看,一台标准的web服务器2W+QPS不会有问题,如果100W人同时刷,100W QPS也只需要50台web,一台硬件LB就可以了~,并且web服务器群是可以很容易的横向扩展的(LB+DNS轮询),这个接口可以只返回一小段json格式的数据,而且可以优化一下减少不必要cookie和其他http头的信息,所以数据量不会很大,一般来说网络不会成为瓶颈,即使成为瓶颈也可以考虑多机房专线连通,加智能DNS的解决方案;web服务器之间时间不同步可以采用统一时间服务器的方式,比如每隔1分钟所有参与秒杀活动的web服务器就与时间服务器做一次时间同步。
浏览器层请求拦截
(1)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
(2)JS层面,限制用户在x秒之内只能提交一次请求;
3.2 站点层设计
前端层的请求拦截,只能拦住小白用户(不过这是99%的用户哟),高端的程序员根本不吃这一套,写个for循环,直接调用你后端的http请求,怎么整?
(1)同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面
(2)同一个item的查询,例如手机车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面
如此限流,又有99%的流量会被拦截在站点层。
3.3 服务层设计
站点层的请求拦截,只能拦住普通程序员,高级黑客,假设他控制了10w台肉鸡(并且假设买票不需要实名认证),这下uid的限制不行了吧?怎么整?
(1)大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?对于写请求,做请求队列,每次只透过有限的写请求去数据层,如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”;
(2)对于读请求,还用说么?cache来抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的;
如此限流,只有非常少的写请求,和非常少的读缓存 mis的请求会透到数据层去,又有99.9%的请求被拦住了。
1、用户请求分发模块:使用Nginx或Apache将用户的请求分发到不同的机器上。
2、用户请求预处理模块:判断商品是不是还有剩余来决定是不是要处理该请求。
3、用户请求处理模块:把通过预处理的请求 封装成 事务提交给数据库,并返回是否成功。
4、数据库接口模块:该模块是数据库的唯一接口,负责与数据库交互,提供RPC接口供查询是否秒杀结束、剩余数量等信息。
-
用户请求预处理模块
经过HTTP服务器的
分发后,单个服务器的负载相对低了一些,但总量依然可能很大,如果后台商品已经被秒杀完毕,那么直接给后来的请求返回秒杀失败即可,不必再进一步发送事务了
这里未整理
4、数据库设计
4.1 设计思路
数据库软件架构师平时设计些什么东西呢?至少要考虑以下四点:
1、如何保证数据可用性;
2、如何提高数据库读性能(大部分应用读多写少,读会先成为瓶颈);
3、如何保证一致性;
4、如何提高扩展性;
-
如何保证数据的可用性?
解决可用性问题的思路是=>冗余
如何保证站点的可用性?复制站点,冗余站点
如何保证服务的可用性?复制服务,冗余服务
如何保证数据的可用性?复制数据,冗余数据
数据的冗余,会带来一个副作用=>引发一致性问题(先不说一致性问题,先说可用性)。
- 如何保证数据库“读”高可用?
冗余读库
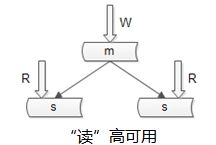
冗余读库带来的副作用?读写有延时,可能不一致
上面这个图是很多互联网公司mysql的架构,写仍然是单点,不能保证写高可用。
-
如何保证数据库“写”高可用?
冗余写库
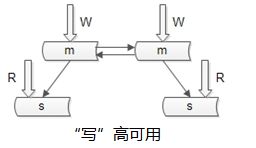
采用双主互备的方式,可以冗余写库带来的副作用?双写同步,数据可能冲突(例如“自增id”同步冲突),如何解决同步冲突,有两种常见解决方案:
-
两个写库使用不同的初始值,相同的步长来增加id:1写库的id为0,2,4,6…;2写库的id为1,3,5,7…;
-
不使用数据的id,
业务层自己生成唯一的id,保证数据不冲突;
实际中没有使用上述两种架构来做读写的“高可用”,采用的是“双主当主从用”的方式:
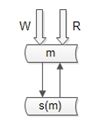
仍是双主,但只有一个主提供服务(读+写),另一个主是“shadow-master”,只用来保证高可用,平时不提供服务。 master挂了,shadow-master顶上(vip漂移,对业务层透明,不需要人工介入)。这种方式的好处:
- 读写没有延时;
- 读写高可用;
不足:
-
不能通过加从库的方式扩展读性能;
-
资源利用率为50%,一台冗余主没有提供服务;
那如何提高读性能呢?进入第二个话题,如何提供读性能。
-
如何扩展读性能
提高读性能的方式大致有三种,第一种是
建立索引。这种方式不展开,要提到的一点是,不同的库可以建立不同的索引。
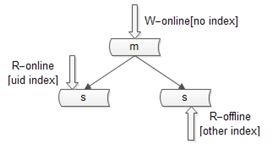
写库不建立索引;
线上读库建立线上访问索引,例如uid;
线下读库建立线下访问索引,例如time;
第二种扩充读性能的方式是,增加从库,这种方法大家用的比较多,但是,存在两个缺点:
实际中没有采用这种方法提高数据库读性能(没有从库),采用的是增加缓存。常见的缓存架构如下:

上游是业务应用,下游是主库,从库(读写分离),缓存。
实际的玩法:服务+数据库+缓存一套

业务层不直接面向db和cache,服务层屏蔽了底层db、cache的复杂性。为什么要引入服务层,今天不展开,采用了“服务+数据库+缓存一套”的方式提供数据访问,用cache提高读性能。
不管采用主从的方式扩展读性能,还是缓存的方式扩展读性能,数据都要复制多份(主+从,db+cache),一定会引发一致性问题。
-
从库越多,同步越慢;
-
同步越慢,数据不一致窗口越大(不一致后面说,还是先说读性能的提高);
- 如何保证一致性?
主从数据库的一致性,通常有两种解决方案:
方案 1. 中间件
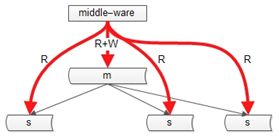
如果某一个key有写操作,在不一致时间窗口内,中间件会将这个key的读操作也路由到主库上。这个方案的缺点是,数据库中间件的门槛较高(百度,腾讯,阿里,360等一些公司有)。
方案 2. 强制读主
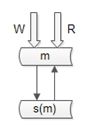
上面实际用的“双主当主从用”的架构,不存在主从不一致的问题。
第二类不一致,是db与缓存间的不一致:

常见的缓存架构如上,此时写操作的顺序是:
(1)淘汰cache;
(2)写数据库;
读操作的顺序是:
(1)读cache,如果cache hit则返回;
(2)如果cache miss,则读从库;
(3)读从库后,将数据放回cache;
在一些异常时序情况下,有可能从【从库读到旧数据(同步还没有完成),旧数据入cache后】,数据会长期不一致。解决办法是“缓存双淘汰”,写操作时序升级为:
(1)淘汰cache;
(2)写数据库;
(3)在经验“主从同步 延时窗口时间”后,再次发起一个异步淘汰cache的请求;
这样,即使有脏数据如cache,一个小的时间窗口之后,脏数据还是会被淘汰。带来的代价是,多引入一次读miss(成本可以忽略)。
除此之外,最佳实践之一是:建议为所有cache中的 item设置 一个超时时间。
- 如何提高数据库的扩展性?
原来用hash的方式路由,分为2个库,数据量还是太大,要分为3个库,势必需要进行数据迁移,有一个很帅气的“数据库 秒级扩容”方案。
如何秒级扩容?
首先,我们不做2库变3库的扩容,我们做2库变4库(库加倍)的扩容(未来4->8->16)
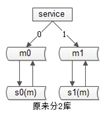
服务+数据库是一套(省去了缓存),数据库采用“双主”的模式。
扩容步骤:
第一步,将一个主库提升;
第二步,修改配置,2库变4库(原来MOD2,现在配置修改后MOD4),扩容完成;
原MOD2为偶的部分,现在会MOD4余0或者2;原MOD2为奇的部分,现在会MOD4余1或者3;数据不需要迁移,同时,双主互相同步,一遍是余0,一边余2,两边数据同步也不会冲突,秒级完成扩容!
最后,要做一些收尾工作:
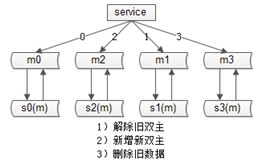
这样,秒级别内,我们就完成了2库变4库的扩展。
-
将旧的双主同步解除;
-
增加新的双主(双主是保证可用性的,shadow-master平时不提供服务);
-
删除多余的数据(余0的主,可以将余2的数据删除掉);
之后未整理