基于EfficientDet的医学图像检测(肺炎、肺结节、肺结核等)(VOC2007)
EfiicientDet既快又准的检测算法实战
- 关于EfficientDet 算法收集的信息
- 关于EfficientDet 算法的架构
- 再补充一点复合缩放的内容
- 动手做实验
- 前期准备
- 训练开始
关于EfficientDet 算法收集的信息
paper链接,由谷歌出品,必属精品,建议小伙伴们啃一啃paper。
非官方keras开源代码,目前还没有官方开源代码,在github上有大佬开源了,也有pytorch版本的,需要的小伙伴可以自行在github上搜索。
官方tf代码来了
efficientNet的权重文件 kaggle链接,由于在github上的EfficientNet权重我尝试了各种姿势下载,都是巨慢无比,因此找到了这个资源,分享给大家。
机器之心介绍,机器之心评价EfficientDet是目前既快又好的目标检测算法。
关于EfficientDet 算法的架构
研究者观察到,近期出现的 EfficientNets [31] 效率超过之前常用的主干网络。于是研究者将 EfficientNet 主干网络和 BiFPN、复合缩放结合起来,开发出新型目标检测器 EfficientDet,其准确率优于之前的目标检测器,同时参数量和 FLOPS 比它们少了一个数量级

图1:特征网络设计图。a)FPN 使用自上而下的路径来融合多尺度特征 level 3-7(P3 - P7);b)PANet 在 FPN 的基础上额外添加了自下而上的路径;c)NAS-FPN 使用神经架构搜索找出不规则特征网络拓扑;(d)-(f) 展示了该论文研究的三种替代方法。d 在所有输入特征和输出特征之间添加成本高昂的连接;e 移除只有一个输入边的节点,从而简化 PANet;f 是兼顾准确和效率的 BiFPN。
基于 BiFPN,研究者开发了新型检测模型 EfficientDet。下图 2 展示了 EfficientDet 的整体架构,大致遵循单阶段检测器范式。研究者将在 ImageNet 数据集上预训练的 EfficientNet 作为主干网络,将 BiFPN 作为特征网络,接受来自主干网络的 level 3-7 特征 {P3, P4, P5, P6, P7},并重复应用自上而下和自下而上的双向特征融合。然后将融合后的特征输入边界框/类别预测网络,分别输出目标类别和边界框预测结果。

图 2:EfficientDet 架构。它使用 EfficientNet 作为主干网络,使用 BiFPN 作为特征网络,并使用共享的边界框/类别预测网络。
再补充一点复合缩放的内容
三种网络调节方式:增大感受野w,增大网络深度d,增大分辨率大小r,三种方式示意图如下:
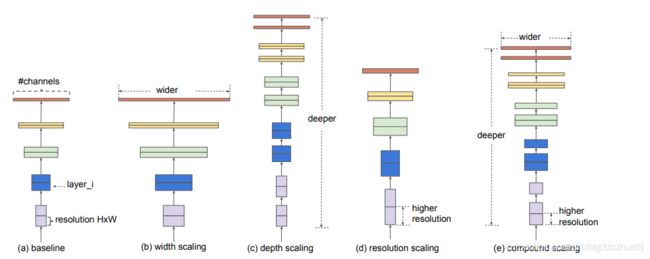
其中,(a)为基线网络,也可以理解为小网络;(b)为增大感受野的方式扩展网络;©为增大网络深度d的方式扩展网络;(d)为增大分辨率r的方式扩展网络;(e)为本文所提出的混合参数扩展方式;
动手做实验
前期准备
1、github上down下来代码
git clone https://github.com/xuannianz/EfficientDet.git
2、编译动态库
代码贡献者给出的代码是在python3.6版本下编译的,如果你是3.7版本,或者别的版本,则需要重新编译动态库,动态库如下图所示:
需要编写setup.py脚本
from distutils.core import setup
from Cython.Build import cythonize
import numpy as np
setup(
name='compute_overlap',
ext_modules=cythonize('compute_overlap.pyx'),
include_dirs=[np.get_include()]
)
python setup.py执行,则会新的动态库。

3、将train.py脚本中的在线下载权重文件更改为提前下载好
权重文件可以在博文开始的时候提供的kaggle链接下载,b0-b7都有。
# load pretrained weights
if args.snapshot:
if args.snapshot == 'imagenet':
# model_name = 'efficientnet-b{}'.format(args.phi)
# file_name = '{}_weights_tf_dim_ordering_tf_kernels_autoaugment_notop.h5'.format(model_name)
# file_hash = WEIGHTS_HASHES[model_name][1]
# weights_path = keras.utils.get_file(file_name,
# BASE_WEIGHTS_PATH + file_name,
# cache_subdir='models',
# file_hash=file_hash)
model_name = 'efficientnet-b{}'.format(args.phi)
weights_path = './'+'{}_weights_tf_dim_ordering_tf_kernels_autoaugment_notop.h5'.format(model_name)
print(weights_path)
# weights_path='./efficientnet-b4_weights_tf_dim_ordering_tf_kernels_autoaugment_notop.h5'
model.load_weights(weights_path, by_name=True)
4、voc类别需要填写自己训练数据的类别名称
# voc_classes = {
# 'aeroplane': 0,
# 'bicycle': 1,
# 'bird': 2,
# 'boat': 3,
# 'bottle': 4,
# 'bus': 5,
# 'car': 6,
# 'cat': 7,
# 'chair': 8,
# 'cow': 9,
# 'diningtable': 10,
# 'dog': 11,
# 'horse': 12,
# 'motorbike': 13,
# 'person': 14,
# 'pottedplant': 15,
# 'sheep': 16,
# 'sofa': 17,
# 'train': 18,
# 'tvmonitor': 19
# }
voc_classes = {
'active_lesions': 0,
'calcifications_cords': 1,
'pleural_calcifications': 2,
'pleural_effusion': 3
}
训练开始
训练分为两阶段式,第一阶段是冻结backbone
执行命令如:
python3 train.py --snapshot imagenet --gpu 0 --random-transform --phi 3 --compute-val-loss --freeze-backbone --batch-size 16 --steps 200 --snapshot-path checkpoints/snap pascal /data/train_data/VOC2007
第二阶段是冻结BN层,其余全部层开始训练
执行命令如:
python3 train.py --snapshot .h5 --gpu 0 --random-transform --phi 3 --compute-val-loss --freeze-bn --batch-size 2 --steps 1500 --snapshot-path checkpoints/snap_2stage pascal /data/train_data/VOC2007
本阶段由于参数较多,batch_size很难设大,可以尝试不要将backbone全部参与训练,可以依然冻结部分。代码修改处在train.py脚本中,修改如下:
if args.freeze_backbone:
#分别对应b0-b6要冻结的层数,也是网络的全部层数
# 227, 329, 329, 374, 464, 566, 656
for i in range(1, [227, 329, 329, 374, 464, 566, 656][args.phi]):
print("i______:",i)
if i<250:
model.layers[i].trainable = False
else:
model.layers[i].trainable = True
实验结果:
训练了一批肺炎数据,目前最好的指标如下:
> val数据
> num_fp=2.0, num_tp=337.0 340 instances of class Pneumonia with
> average precision: 0.9911 mAP: 0.9911
>
> test数据
> num_fp=2.0, num_tp=33.0 35 instances of class Pneumonia with
> average precision: 0.9343 mAP: 0.9343
效果图
若要真正达到临床使用,还有很多路要走