python数据分析和建模须知
整理了python数据分析和建模需要掌握的基本分析方法和实现。
基础部分:Numpy, Pandas, Matplotlib,可以结合《利用python进行数据分析》这本书来学习,比较基础,也很简单,书中有实例,可以代码练习快速上手。
分析和建模部分:Scipy,Sklearn,可以结合官方文档和别人的笔记学习,比较容易掌握。
scipy学习:http://scipy-lectures.org/intro/scipy.html
sklearn 学习:https://scikit-learn.org/stable/
建议:scipy学习可以先读博客https://blog.csdn.net/gengkui9897/article/details/83111138,有主要方法介绍和代码实现,然后再去看上述推荐的scipy笔记补充。sklearn学习建议直接读上面的官方文档,写的很结构化很直观。
先放整理的知识结构导图,结合知识导图再去看详细的知识点,会更清晰容易理解。
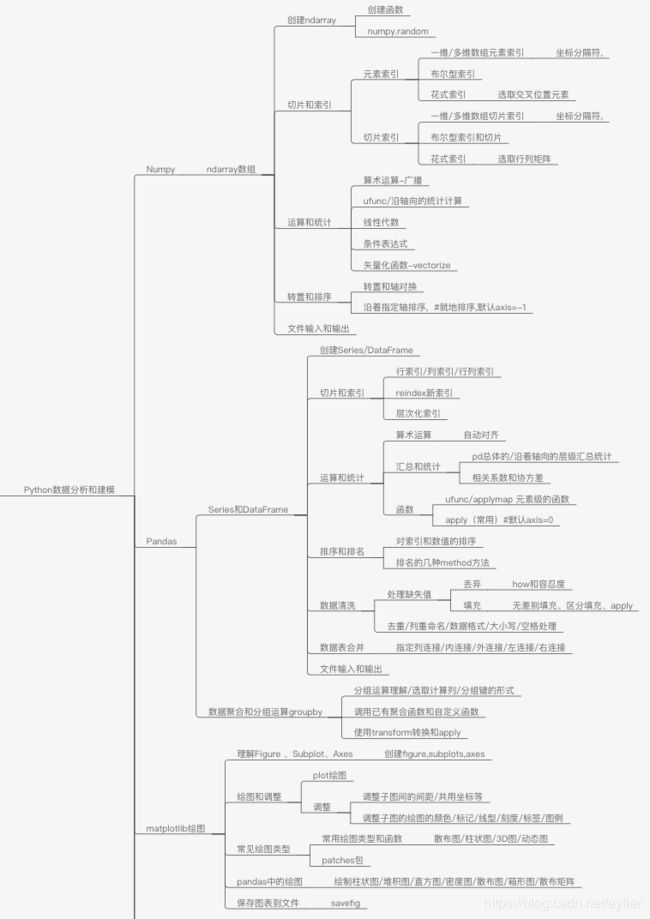
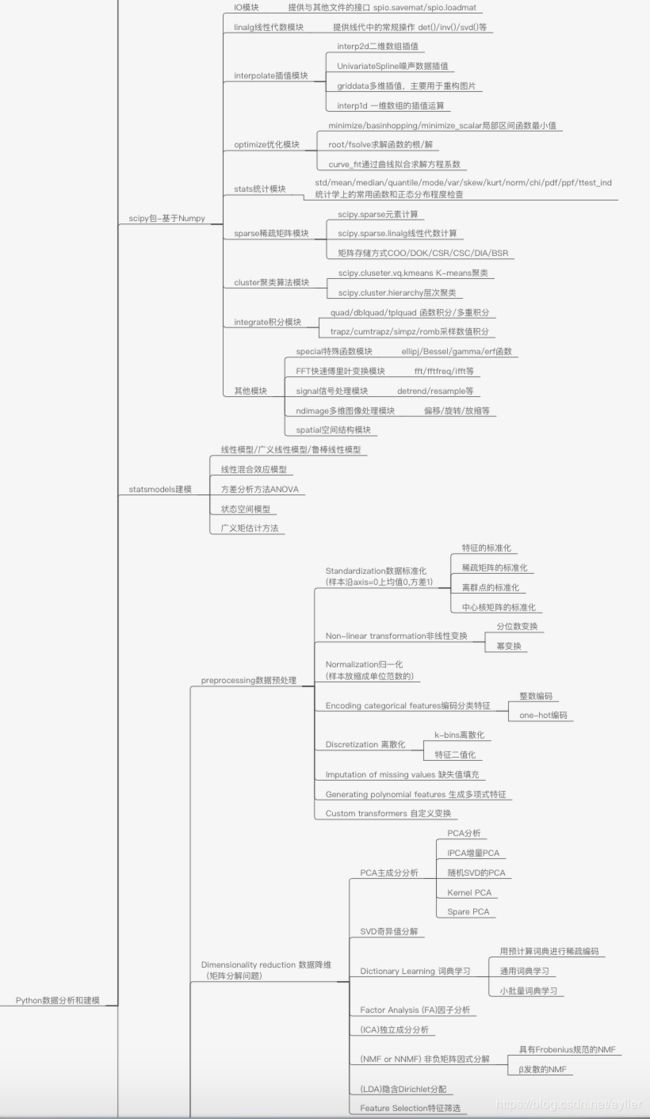
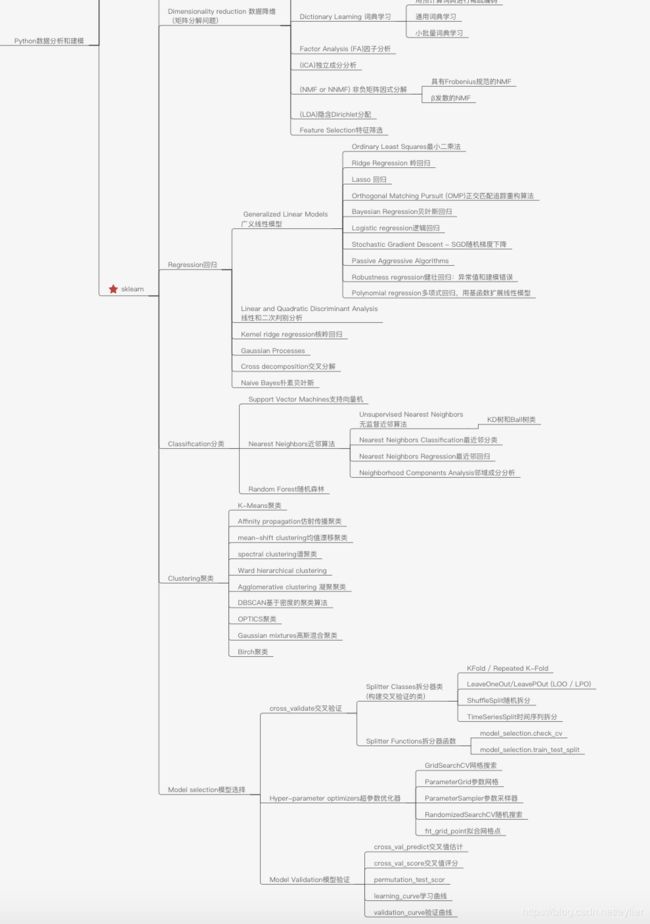
工具准备
文本编辑器:Sublime,Notepad++等都很好用。
代码编辑器:Pycharm,Ipython, Jupyter 或者Spyder等。
平时写代码习惯用Pycharm,文件编辑用Sublime。做这份文章整理时用的是Anaconda的Ipython做代码运行。
一、常用的python内置数据结构
python内置的一些数据结构array,list, tuple,dictory。
(1)array
array 是数组, 数组是只能够保存一种类型的数, 初始化的时候就决定了可以保存什么样的数.
import array
arr = array.array('i',[0,1,1,3]) #array.array(typecode,[initializer]) --typecode:元素类型代码;initializer:初始化器,若数组为空,则省略初始化器
(2)list , python内置的列表
alist = ['gao',2,'python'] #list 里面 几乎可以放任何对象,已经类型,无论是数字,还是字典,还是对象,还是列表,都可以同时放到一个列表里面. 索引是基于位置的。
*表示重复列表。['gao']*2 = ['gao','gao'].
切片或截取: alist[1:2]
list 对于两个列表 + 表示追加或扩展,类似于extend.
#函数
cmp(list1,list2), len(list), max(list), min(list), list(seq)
#方法
list.append(x) #末尾追加, list.count(x) #统计x在列表中出现次数,list.extend(seq) #追加,list.index(x) #查找x在数组中的第一个索引位置,
list.insert(index,obj) #插入, list.pop(index=-1) #移除,默认移除最后一个,list.remove(x) #移除第一个匹配项, list.reverse(),
list.sort(cmp=None,key=None,reverse=False)#对原列表就地排序
(3)dict字典
二、Numpy数据分析包
import numpy as np
ndarray多维数组:具有矢量运算和复杂广播能力的快速且节省空间的多维数组。每个数组有两个属性来确定,shape(表示数组是X*Y的维度),dtype(说明数组的元素数据类型)
(1)数组创建
函数:array,asarray,arange,ones,ones_like,zeros,zeros_like,empty,empty_like,eye,identity
a = np.array([1,2,3.5])
b= np.array([[1,2,3],[4,'a','b'],dtype=np.string_)
e=np.arange(15) #numpy内置的range的数组版. np.arange(start_num,end_num,step)
e1=np.arange(-5,5,0.5)
e2=np.arange(15).reshape((3,5)) or np.arange(15).reshape(3,5)
arr=np.random.randn(5,4,3) #正态分布的数据
numpy.random.randn(d0,d1,…,dn)是从标准正态分布中返回一个或多个样本值。
numpy.random.rand(d0,d1,…,dn)的随机样本位于[0,1)
ndarray的数据类型dtype有:int64,float64,object,unicode_,string_等
(2)切片和索引 --默认按照axis=0索引。
元素索引
[i]一维数组索引 a[N]
[ii]多维数组索引, 如3维的,a[2][3][4] 等于 a[2,3,4], a[2]是二维的数组,a[2,3]是一维的数组,a[2,3,4]是元素。a[:,3,4]
[iii]布尔型索引 , 如上a==2产生的ndarray, a[a==2], c3[a==2], a[a<3],会筛选出True位置索引对应的元素。布尔型索引必须和被索引的轴长度一致。
布尔判断还有还有不等号、负号 a!=2 , -(a==2), <,>等。多个布尔条件可以用 | 或 & 连接起来。 new_ndarr = (a==2) | (a==5)
[iv]花式索引,a[[1,5,3]]选取1,5,3行。a[[1,5,3],[0,3,2]] 选取(1,0),(5,3),(3,2)位置上的元素,元素索引。
a[:,[1,0,3]]选取列,注意:a[[1,5,3],[1]]=a[[1,5,3],[1,1,1]]
切片索引
[i] 一维数组切片 ,a[start:end:step]
[ii]多维数组切片 ,比如三维的数组,a[start:end:step,start:end:step,start:end:step],a[:,:2,::2]
[iii]布尔型索引和切片混用,c3[a==2,1:2], a[:,b=='a',:]
[iV]花式索引,a[[1,5,3]][:,[0,3,2]] 选取行列矩阵
#注意:通过布尔型索引或切片或者赋值是常用的方式。 data[col!='x'] = 7, data[data<0]=0。 花式索引会将数据复制到新数组中。
(3)转置和排序
[i]转置/轴对换 a=a.transpose((0,1,2)), a.T = a.transpose((2,1,0)) = a.swapaxes(2,0)。 与轴编号对应的坐标变换而已,很简单。
[ii]排序,就地排序 #沿着某个轴向排序 #沿着轴向坐标增加的值排序 a.sort(1)==a.sort(axis=1) #a.sort() a.sort() = a.sort(axis=最后轴)
(4)运算和统计
[i]与常数的运算 等于每个元素做运算 , +, -, *, / ,赋值运算= ,比较运算符等。如 a == 2 --> array([False,True,False,False],dtype=bool)
[ii]与ndarray间的 + - * 运算等于元素间的运算 ,对切片表达式的赋值操作也会广播到其选中的所有元素。
[iii]元素级数组函数ufunc
一个数组变量的: np.abs(a),np.floor(np.sqrt(a)),np.isnan(a), 等函数
两个数组变量的: np.maximum(a,b)#注意这里比较max时a,b要dtype类型相同,其他函数使用也要注意数据类型。 np.substract(a,b), np.less(c,d),np.equal(c,d)
[iv]对整个数组或某个轴向的数据进行计算: #对整个数组的 arr.mean() , arr.sum(),arr.std(),arr.min(),arr.max()
#对某个轴向上的值做统计 arr.sum(axis=1) 或者 arr.sum(1) #沿着轴1坐标增加求和,坐标 (0,0,0)+(0,1,0)+(0,2,0)+(0,3,0).得到的是余下轴shape的矩阵
#注意cumsum(),cumprod()不聚合,产生中间结果数组, arr.cumsum(0),arr.cumprod(1)
#对于布尔型的数组此类运算,True被转1,False转为0. (randn(100)>0).sum() #计算正值的个数。bools_arr.any() #是否存在True, bools_arr.all()#是否全True
[v]线性代数#矩阵乘法、分解、行列式等
点积:dot函数, np.dot(x,y)
#矩阵求逆、QR分解、求行列式、特征值/特征向量、奇异值分解、求解线性方程组ax=b,矩阵的幂、矩阵范数
numpy.linalg函数:diag,dot,trace,det,eig,inv,pinv,qr,svd,solve,lstsq
a=np.array([[3,1],[1,2]]), b=np.array([9,8]), x=np.linalg.solve(a,b) #解线性方程组
U,s,V = np.linalg.svd(a,full_matrices=False)
[vi]集合逻辑-结果均返回一维数组,不管比较的数组是几维。都是元素间的比较,不关心数组的维度是否一样。
np.unique(arr) #去重且排序,注意多维数组时会平展开返回一维数组
np.in1d(ndarray1,ndarray2) #判断ndarray1中的值在不在ndarray2中,每个值判断后返回一个布尔值。
np.intersect1d(x,y) , np.union1d(x,y), np.in1d(x,y), np.setdiff1d(x,y), np.setxor1d(x,y)
[vii]根据一维数组产生二维矩阵函数 np.meshgrid
(5) 数组运算的条件表达式 np.where(cond,True_value,False_value) , 如果cond为True,则取True_value中值,为False则取False_value 中值。
True_value/False_value可以是同维度数组,也可以是标量。
cond=np.array([True,False,True,False]) , x=np.array([1,2,3,4]) , y=np.array([2,3,5,6])
np.where(cond,x,y), np.where(a>2,2,0) , np.where(arr>0,2,arr)
#条件表达式更复杂的逻辑表示, np.where(cond1&cond2,0,np.where(cond1,1,np.where(cond2,2,3)))
(6)文件的输入输出
np.save('/Users/gao/Desktop/pad/some_file_name',arr) #保存数组到文件,会自动加上.npy的扩展名 #可以保存任意维度的数组
g = np.load('/Users/gao/Desktop/pad/some_file_name.npy') #读取.npy文件数据到数组
#指定分隔符、跳过列、对指定列使用转换器函数
np.loadtxt('test_file.txt',delimiter=';')
np.savetxt('/Users/gao/Desktop/pad/some_file_name',arr,delimiter=',') #arr是一维或2维的数组,超过就不可保存
(7) numpy.random函数
numpy.random模块对python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值的函数。
np.random.rand(d1,d2...) #生成[0,1)之间的随机浮点数或N维浮点数组
numpy.random.randn(d1,d2,...) #生成浮点数组,取数范围:正态分布的随机样本数
numpy.random.randint(low,high,size) #np.random.randint(10,size=(2,5)) 生成一个位于[0,10)区间内的size=(2,5)的整数2维数组
numpy.random.normal(size=(4,4)) #生成标准正态分布的4*4样本数组,需要生成大量样本值时numpy.random比内置的random要快
numpy.random.choice()
numpy.random.shuffle() #打乱顺序洗牌,就地操作,多维的按axis=0进行
numpy.random.permutation() #返回随机排列或随机排序的数组,多维的按axis=0进行。 np.random.permutation(10) , np.random.permutation(a)
numpy.random.RandomState():指定种子值使同样的条件下每次产生的随机数一样。np.random.RandomState(2019).randn(2,3)
numpy.random.seed ( ):用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed()值,则每次生成的随即数都相同.
三、pandas库
from pandas import Series,DataFrame
import pandas as pd
1、两个主要的数据结构,Series, DataFrame。
(1)Series , 类似于一维数组,由一组数据和索引组成。
[i]创建Series
a=Series([3,4,5,np.nan,1]) #这里Series会自动加上索引 ,索引默认从0开始
a= Series([3,4,5,1],index=['a','b','c','d']) #指定索引
a=Series(s) #通过字典创建Series, s={'Oh':350,'Tex':450,'Org':89}
#注意NaN ,NA, missing,None,np.nan表示缺失值。pd.isnull(a) , pd.notnull(a) 判断元素是否是缺失值
[ii]Series索引和切片
#类似于Numpy数组的索引。a.values #查看a的值 ,a.index #查看索引,
#方法1:index索引 val.Dan, val['Dan'] , val[['Dan','JJ']] #选取一组, val['Dan':'JJ'] #注意index的切片是两端包含的。注意区分行号的切片左包含右不包含
#方法2:行号索引 val[1] , val[[1,3]] , val[1:3] #尽管Series val是有index的,行号索引也可以.
#方法3:布尔值索引 val[val<2] ,a[a>3] #布尔型过滤
[iii]运算
布尔型过滤、标量乘法、函数都会保持索引和值的对应。
(2)DataFrame,二维表格型的数据结构,类似于EXCEL,既有行索引又有列索引。
[i]创建DataFrame
可以传给DataFrame构造器的数据:二维ndarray、由数组/列表/元组组成的字典、Series组成的字典或列表、字典等。
<1>由等长列表或Numpy数组的字典生成
如 data={'state':['ohio','ohio','ohio','nevada','nevada'], 'year': [2000,2001,2002,2002,2002],'pop':[1.5,1.7,3.5,2.4,2.9]}
frame = DataFrame(data) #DataFrame的列是有序的,如果不指定列名,列会自动排序,如这里按照字母顺序,pop排在了前面。同时也自动加上了索引。
可以指定列名和索引,会按照指定的列名顺序排列,如果传入的列名不在数据中,会产生NA值。
frame = DataFrame(data,columns=['state','year','pop'],index=['Jayzhou','Yanzi','Dan','JJ','Yknow'])
<2>嵌套字典生成
如 pop={'Nezha':{201907:1.9,201908:9.8},'Lion':{201907:1.2,201908:2.1}}
frame = DataFrame(pop) #外层的字典Key被解读为列,内层的key解读为行。当然可以转置 frame.T 或指定索引
<3>Series组成的字典
如pdata={'ohio':a,'nevda':frame['state'][:4]}
[ii]查看\获取\索引\reindex\层次化索引
<1>行/列获取
列获取:通过字典标记或属性的方式,如frame['state'],frame.year , frame.columns #查看列名
行获取:位置、名称或索引。frame.iloc[0],frame.loc[0], frame.ix['Yanzi'] , frame.index #查看行索引
#行号获取: frame[:2]
#布尔型获取: frame[frame['a']>2] , frame[frame>2]
行列获取:loc[基于label的索引] , iloc[基于位置的索引]
obj.ix[val] #选取单行或一组行, obj.ix[:,val] #选取单列或一组列 , obj.ix[val1,val2] #同时选取行和列
frame.ix[data.three>5,:3] , frame.ix[1] #取第二行 , frame.ix[['Dan','JJ'],[1:3]]
<2>reindex 将一个或多个轴匹配到新索引
Index索引的方法和属性,可用于设置有关索引所包含的数据,append, diff,intersection,union,isin,delete,drop,insert,is_monotonic,is_unique,unique
对列重新索引: frame.reindex([201908,201907,201909],fill_value=0) #frame不改变,但会根据此处index重新返回一个DataFrame。
states = ['Tex','pop','year'] , frame.reindex(columns=states)
对行和列重新索引,插值只能按轴0进行:frame.reindex(index=['a','b','c'],method='ffill',columns=states)
利用loc标签的索引,frame.loc[[0,2],state], frame.ix[['a','b','c'],state] #注意行索引要在index中,超出的会报warning
#注意:reindex的插值处理方法method选项: ffill或pad 前向插值,bfill或backfill 后向插值 frame.reindex(range(6),method='ffill')
fill_value可引入缺失值的替代值,limit前向或后向最大的填充量。
<3>层次化索引
#Series : s1['a':'b'], s1.loc[['a','b'],[1,2]]
#DataFrame:
<4> 修改赋值:frame['debt']=np.arange(5) #新增一列并赋值。将数组或列表赋值给某列时,长度必须和DataFrame的长度相同。
frame['esten'] = frame.state=='ohio'
frame['debt']=val , val=Series([1.2,3.2,4.5,1.3],index=['Yanzi','Jayzhou','Dan','JJ']) #若将Series赋值给DataFrame的列会精准匹配index
<5>删除指定轴上的数据
drop方法:
删除行: frame.drop('a') , frame.drop(['a','c']) #a,c是index中值
删除列: frame.drop('year',axis=1) , frame.drop(['year','state'],axis=1) #按列轴向删除
[iii]运算和数据对齐
算术运算法: add , sub , div , mul
算术运算符: + , - , / , *
<1>算术运算时对不同索引的对象,数据会自动对齐。相同数据结构Series或DataFrame的运算是广播。
如两个Series相加时新的索引是索引的并集。两个DataFrame相加时索引和列都变成原来的并集。
DataFrame与Series间的运算会将Series的索引匹配到DataFrame的列,沿着列进行算术运算的广播。列或索引会是并集。
#1、对算术运算产生的NA值填充,方法有 add ,sub, div, mul, Series和DataFrame的运算都适用
s1.add(s2,fill_value=0) , df1.add(df2,fill_value=0) , df1.reindex(index=df2.index,fill_value=0)
#2、匹配行 ,沿着列广播运算
frame.sub(s1,axis=0)
<2>汇总和统计方法
#1、对一个pandas数据结构变量的汇总和统计方法:
count(),sum(),mean(),std(),median(),skew()#样本值的偏度,cummin(),cummax(),cumprod(),pct_change(),argmax(),idxmax()#最大值索引值,
argmin() #最小值的索引位置即第几行或第几列,idxmin()#最小值索引值, cumsum()#累计, describe()#多个汇总统计 等
会忽略np.nan做汇总统计,通过skipna选项可禁用忽略NA
s1.sum(), s1.sum(skipna=False), s1.describe()
frame.describe(), frame.sum() ,frame.pct_change(),frame.sum(axis=1,skipna=False)
frame.sum(level='color',axis=1), frame.sum(level=['color','state'],axis=1) #对于分层索引的,根据层级汇总统计
#2、对两个pandas数据结构变量的汇总统计
corr()#计算相关系数,cov()#协方差
Series之间:s1.cov(s2), s1.corr(s2) #计算s1和s2的相关系数,只计算index重叠的、非NA值,默认的是pierson相关系数。 --返回一个结果数值
DataFrame的列与列或行与行 或DataFrame的某行与Series: 均同上Series之间,frame.g.corr(frame.a) #a列与g列相关系数 ,frame.loc['n'].corr(frame.loc['a']), frame.a.corr(s1) #DataFrame的列与Series之间 ,--返回一个结果数值
DataFrame与Series之间:frame.corrwith(frame.a) #frame各列与a列的相关系数 ,frame.corrwith(s1) --返回一个结果值的Series
DataFrame自身的:frame.corr() #默认axis=0向的两两相关系数 ,frame.T.corr() #axis=1轴向的两两相关系数 --返回一个结果值的DataFrame
<3>函数
#1、Numpy的 ufuncs元素级的方法, np.abs(frame)
对于聚合函数frame.mean(), frame.sum(),frame.std() 等#默认按照axis=0进行
#2、元素级python函数-- applymap方法 #元素级,没有轴向之分
f= lambda x:x*2+1 , f=lambda x:'%.2f'%x #取两位浮点值做字符串
frame.applymap(f)
对于Series用法为: s1.map(f) 或者 s1.apply(f) ,没有 s1.applymap(f)
#3、apply方法(常用)
将函数应用到由各行/各列形成的一维数组上,axis=N,沿着这个轴向坐标增加
# 返回单一值:
f = lambda x:x.max() - x.min()
frame.apply(f) #默认沿着轴向axis=0计算
frame.apply(f,axis=1) #沿着轴向axis=1计算
#返回由多个值组成的Series
def f(x):
return Series([x.min(),x.max()], index=['min','max'])
frame.apply(f)
[iv]排序和排名
<1>对行、列索引排序
#Series
s1.sort_index() #字典顺序
#DataFrame
frame.sort_index() #默认 沿着轴axis=0 ,字典升序排列
frame.sort_index(axis=1, ascending=False) #沿着指定轴的索引排序
<2>对数值排序
#Series: s1.sort_values(ascending=False) #缺失值会被放到Series末尾
#DataFrame: 对某列或某些列进行排序
frame.sort_values(by='e') 或者 frame.sort_values('e') #根据某一列排序
frame.sort_values(by=['a', 'b'], ascending=[False, True]) 或者 frame.sort_values(['a','b'],ascending=[False, True]) #根据某些列排序
<3>层次化索引的分级重排
<4>排名 rank(method,ascending,axis)
#Series
s1.rank() 等于 s1.rank(mehtod='average') #平均排名,排名不连续,默认升序
s1.rank(method='first') #按照出现顺序排名,排名不重复,排名连续
s1.rank(method='max',ascending=False) #按照分组最大排名,即排名重复时选最大的那个排名,此时排名不连续。升级序可选。
s1.rank(method='min',ascending=False) # 按照分组最小排名,即排名重复时选最小的那个排名,排名不连续。
#DataFrame
frame.rank(axis=1) #跟Series相同,只是可选择按轴向axis=1进行排名,默认axis=0
[v]处理缺失值
方法有:dropna #可通过阈值调整容忍度 , fillna(ffill,bfill),isnull,notnull
丢弃:frame.dropna(axis=1) ,s1.dropna() ,frame.dropna(thresh=3) #至少有3个非NA值。frame.dropna(how='all')#丢掉全部是NA值的或'any'出现过NA值的。
填充:frame.fillna(0) #无差别填充, frame.fillna({'g':1,'l':2}) #字典,分列选择填充, frame.fillna(0,inplace=True) #就地修改,否则都是返回新对象
frame.fillna(method='ffill',limit=2) , frame.fillna(frame.mean())#用平均值填充
[vi]其他Series
<1> Series去重
#Series的值去重 s1.unique(), 索引去重 s1.index.unique() .len(s1)==len(s1.unique())
<2>Series 统计数值出现频次
s1.count() #统计总数值量, frame.count() #每列出现数值量
pd.value_counts(s1,sort=False) 或者 s1.value_counts() #统计s1的数值出现频次,
DataFrame指定列统计数值频次:frame.a.value_counts()
DataFrame所有列的数值各自出现的频次: frame.apply(pd.value_counts).fillna(0) #用Series的value_counts和apply组合实现,没出现的填充0,默认NA
<3>Series判断数值是否在某个要求的子集中
s1.isin(s2) 或者 s1.isin(['Dan','JJ'])
[vii]文件导入导出
score=DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
score=DataFrame(pd.read_excel('/Users/gao/test_dataframe.xlsx',index_col=[0,1],header=[0,1])) #index_col行索引所在列号,header列索引所在行号
2、数据聚合和分组-groupby
[i]分组运算:split-apply-combie 拆分-应用-合并
拆分操作:沿着指定的轴(axis)执行,根据提供的一个或多个键进被拆分为多组。
应用操作:将函数应用到每个分组并产生一个或一组新值。
合并操作:执行结果被合并到最终的结果对象中。
分组键:类型不必相同,可以是长度与待分轴相同的列表或数组,DataFrame的某个列名的值,字典或Series,函数等,只要保证能将待分组的轴划分即可。
[ii]选取一个或一组列
df['data1'].groupby(df['key1']) #对df按照key1列分组,选取data1这列数据 或者 df.groupby(['key1','key2'])['data1'].mean()
[iii]通过list\字典\Series\函数进行分组
df.groupby(s1,axis=1).count()
df.groupby([len,key_list]).min() #混用函数、数组、列表和字典来分组
[iv]分组上调用已有的聚合函数和自定义的函数
<1>将自定义的聚合函数传入aggregate 或 agg方法
df.groupby('key1').agg(f)
df.groupby(['sex','smoker'])['tip_pct'].agg(['mean','std','peak_to_peak']) #应用多个统计函数
df.groupby('sex')['tip_pct'].agg([('thisismean','mean'),('thisisstd','std')]) #传入带有自定义名称的元组列表
df.groupby('tag').agg({'cpi':'sum','tbl':'mean'}) #对不同列应用不同的函数,使用字典传入列名和函数的映射。
df.groupby('tag').agg({'cpi':['sum','std','mean'],'tbl':'mean'}) #将多个函数应用于同一列,返回的结果是层次化的列。
df.groupby('tag',as_index=False).agg({'cpi':['sum','std','mean'],'tbl':'mean'}) #通过as_index=False禁用层次化分列
<2>在groupby上使用transform方法
#transform会将一个函数应用到各个分组,然后将结果放到分组的适当位置。transform是有着严格条件的特殊函数,传入的函数只能产生两种结果,要么是可以广播的标量值,要么是相同大小的结果数组。
people.groupby(key).mean() #相同分组的元素位置上放置对应的平均值
def demean(arr):
return arr-arr.mean()
people.groupby(key).transform(demean) #每个分组的位置的元素减去相应的分组的平均值
<3>apply (同上1中[iii](3)函数apply小节)
tips.groupby(['smoker','day']).apply(top,n=1,column='total') #def top(df,n=5,column='tip'):** ,top函数接受的参数放在函数名后。
tips.groupby(['smoker','day'],group_keys=False).apply(top,n=1,column='total') #禁止分组键,可以去掉分组键构成的结果层次化索引。
<4>分位数和桶分析
使用cut/qcut根据指定面元或样本分位数将数据拆分成多块,跟groupby结合起来,实现对数据集的分桶(bucket)或分位数(quantile)分析。
四、绘图和可视化-matplotlib
import matplotlib.pyplot as plt
#理解 Pyplot绘图结构
https://blog.csdn.net/matrix_laboratory/article/details/50698239
#参考博客,讲的很详细。Artists分为简单类型和容器类型两种。简单类型的Artists为标准的绘图元件,例如Line2D、 Rectangle、 Text、AxesImage 等。而容器类型则可以包含许多简单类型的Artists,使它们组织成一个整体,例如Axis、 Axes、Figure等。
1、理解Figure 、Subplot、Axes,以及如何创建和获取
Figure代表一个绘制面板,其中可以包涵多个Axes(即多个图表),Axes表示一个图表 ,一个Axes包涵:titlek, xaxis, yaxis。
(1)创建figure 和 subplot
<1> fig.add_subplot(nrows,ncols,index)
fig= plt.figure() #不能通过空figure绘图。要创建subplot或axes才可以。
ax1 = fig.add_subplot(2,2,1) #创建一个2*2的图像,且选中4个subplot中的编号是1的。
ax2 = fig.add_subplot(2,2,2) #要通过创建,才会在figure中绘出
ax3 = fig.add_subplot(2,2,3)
<2> plt.subplots(nrows,ncols,sharex=False,sharey=False)
fig, ax_lst = plt.subplots(2, 2) #创建一个figure,并且有2*2,4个绘图坐标区。这里ax_lst是一个2*2的Numpy数组。
对ax_lst索引,实现选取subplot。 ax_lst[0,0], ax_lst[0,1],ax_lst[1,0],ax_lst[1,1]
<3> fig.add_axes([left, bottom, width, height])
fig = plt.figure() #创建一个空的,没有任何绘图axes坐标区域的figure
ax = fig.add_axes([left, bottom, width, height]) #增加一个绘图坐标区域
<4>Artist的常用属性
Artist对象的所有属性都通过相应的 get_* 和 set_* 函数进行读写
fig.set_alpha(0.5)
fig.set(alpha=0.5, zorder=2) #用一条语句设置多个属性,使用set函数
plt.getp(fig.patch) #使用 matplotlib.pyplot.getp 函数可以方便地输出Artist对象的所有属性名和值。
#add_axes 和 add_subplot的区别是什么?
(2)绘图和调整
参考 https://matplotlib.org/faq/usage_faq.html
[i] plot绘图
ax1.plot(x, y) #将x,y坐标的数据绘制到ax1绘图区中。x = np.arange(0, 3 * np.pi, 0.1) , y = np.sin(x)
[ii]设置子图的绘图范围
ax.get_xlim(), ax.get_ylim() ,ax.set_xlim([0,50]) ,ax.get_ylim([-50,50]) #查看和设置一个子图的X轴/Y轴绘图范围
[iii]调整边距和子图的间距 subplots_adjust(self,left=None,bottom=None,right=None,top=None,wspace=None,hspace=None)
#left/right 子图在figure中距左侧相对位置,left
fig,axes=plt.subplots(2,2,sharex=True,sharey=True) #子图使用相同的X/Y轴刻度
fig.subplots_adjust(wspace=0,hspace=0) #使用subplots_adjust调整子图间距
[iiii]调整子图背景颜色,绘图颜色、标记、线型、刻度、标签和图例等
<1>指定颜色和线型
ax.plot(x,y,linestyle='--',color='g') 或者 ax.plot(x,y,'g--') #颜色通过指定缩写词或其RGB值的形式使用,linestyle参考plot文档
#线型图可以加上一些标记marker,以强调数据点。
ax.plot(randn(30).cumsum(),'ko--') 或者详细的指定:ax.plot(randn(30).cumsum(),color='k',linestyle='dashed',marker='o')
<2>图标装饰-刻度、标签、图例
ticks =ax.set_xticks([0,250,500,750,1000]) #重设x轴刻度
labels = ax.set_xticklabels(['one','two','three','four','five'],rotation=30,fontsize='small') #刻度替换成标签
ax.set_title('my first plot') #给绘图加上标题
ax.set_xlabel('state') #给x轴加上标签
ax.plot(randn(1000).cumsum(),'g--',label='$y=cumsum(x)$') #通过label设置图例
ax.legend(loc='best') #loc将图例设置在哪里,plt.legend(bbox_to_anchor=(num1, num2), loc=num3, borderaxespad=num4)
ax.text(x,y,'hello',family='monospace',fontsize=10) #在指定(x,y)坐标加上文本注解
ax.annotate(label,xy,xytext,arrowprops,horizontalalignment,verticalalignment) #注解工具annotate,给数据添加文本注解,而且支持带箭头的划线工具
(3)常见绘图函数和模块
<1> 绘图及常见的图表类型-散点图/柱状图/等高线/3D图/动态图/子图
ax1.plot(x,y)
ax1.plot(np.random.randn(50).cumsum(),'k--') #plt.plot() 绘图,'k--'是线性选项,这里是黑色虚线图
ax2.bar(x,y,facecolor='#9999ff',edgecolor='white')#柱状图,柱颜色,柱边框颜色
ax3.scatter(np.arange(30),np.arange(30)+3*randn(30)) #散点图
ax2.hist(np.random.randn(100),bins=20,color='k',alpha=0.3)
<2> matplotlib.patches包
rect=plt.Rectangle((0.2,0.75),0.4,0.15,color='k',alpha=0.3)
circ = plt.Circle((0.7,0.2),0.15,color='b',alpha=0.3)
pgon = plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.4]],color='g',alpha=0.5)
ax.add_patch(rect) #添加块
ax.add_patch(circ)
ax.add_patch(pgon)
(4)pandas中的绘图 -绘制柱状图/堆积柱状图/直方图/密度图/散布图/箱形图/散布矩阵
Series / DataFrame都有一个用于生成各类图表的plot方法。默认生成线型图。
s=Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10))
s.plot()
df = DataFrame(np.random.randn(10,4).cumsum(axis=0),columns=list('ABCD'),index=np.arange(0,100,10))
df.plot() #自动创建图例
(5)将图表保存到文件
fig.savefig('/Users/gaohilda/Desktop/pad-adv/figpatch.pdf',dpi=400,bbox_inches='tight') #或者.png, dpi:分辨率,bbox_inches设置tight会裁剪空白。
六、scipy
Scipy是基于Numpy设计的包,它包括统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解器等。
import numpy as np
from scipy import stats
1、scipy.io: IO模块。提供与其他文件的接口,如matlab文件、IDL文件、Wav(音频)文件、ARFF文件
[1]读取Matlab文件
from scipy import io as spio
a = np.ones((3,3))
文件保存 spio.savemat('file.mat',{'a',a}) #保存对象用字典形式,.mat是matlab文件格式
[2]读取图片文件
from scipy import misc
misc.imread('fname.png')
import matplotlib.pyplot as plt
plt.imread('fname.png')
2、scipy.linalg: 线代模块。提供各种线性代数中的常规操作
from scipy import linalg
linalg.det() #计算行列式
linalg.inv() #计算逆矩阵
uarr,spec,vharr = linalg.svd(arr) #奇异值分解SVD
np.allclose( uarr.dot(np.diag(spec)).dot(vharr), arr)
3、scipy.interpolate:插值模块。是离散函数逼近的重要方法,利用函数在有限个点处的取值情况,估算出函数在其他点处的近似值。要求曲线通过所有的已知数据,拟合函数一般基于最小二乘法尽量靠近所有样本点穿过。当样本数据变化归因于一个独立的变量时,使用一维插值;反之样本数据归因于多个独立变量时,使用多维插值。
计算插值由两种基本的方法:
1、对一个完整的数据集去拟合一个函数
2、对数据集的不同部分拟合出不同的函数,而函数之间的曲线平滑对接。这种方法也就做仿样内插值法。当数据拟合函数形式非常复杂时,是非常强大的工具。
from scipy import interpolate
[1] from scipy.interpolate import interp1d #1d数组的插值运算,这是一个类,不是函数
interp1d(x,y,kind='linear',...) #x,y是已知的数据点,kind是插值类型
kind可选值和作用:
'zero', 'nearest' : 阶梯插值,相当于0阶B样条曲线
'slinear','linear' :线性插值,用一条直线连接所有的取样点,相当于一阶B样条曲线
'quadratic','cubic' : 二阶和三阶B样条曲线,更高阶的曲线可以直接使用整数数值指定
[2]噪声数据插值
UnivariateSpline(x,y,s=0)函数对含有噪声的数据进行插值运算
参数s是平滑向量参数,被用来拟合还有噪声的数据。如果参数s=0,将忽略噪声对所有点进行插值运算。
[3]from scipy.interpolate import interp2d #2d数组插值
interpolate.interp2d(x, y, fvals, kind='cubic') #fvals是(x,y)坐标点的数值
[4]多维插值
多维插值主要用于重构图片,interpolate模块中的griddata()函数有很强大的处理多维散列取样点进行插值运算的能力
griddata(points,values,xi,method='linear',fill_value=nan)
points表示K维空间中的坐标,values是points中每个点对应的值,xi是需要进行插值运算的坐标,method参数有三个选项:'nearest','linear','cubic',分别对应0阶、1阶以及3阶插值。
4、scipy.optimize: 优化模块。 里面有各种优化算法,包括用来求有/ 无约束的多元标量函数最小值算法,最小二乘法,求有/无约束的单变量函数最小值算法,还有解各种复杂方程的算法
from scipy import optimize
scipy.optimize.curve_fit() #通过曲线拟合来求解曲线方程系数
scipy.optimize.minimize() #给定一个x0,寻找该点附近的一个局部最小值
scipy.optimize.minimize(f, x0=1, bounds=((-3, 10), )) #可以指定寻找最小值的区间bounds
scipy.optimize.basinhopping() #返回一个局部区间函数的最小值
scipy.optimize.fmin_bfgs() # 返回一个局部区域的最小值,采用BFGS优化算法(Broyden–Fletcher–Goldfarb–Shanno algorithm)
scipy.optimize.minimize_scalar() #专门用来找只有一个变量的函数的最小值
scipy.optimize.root() #求函数的根,即f(x)=0的解,这里只会返回一个根
scipy.optimize.fsolve() #函数求解
5、scipy.stats: 统计模块。提供一些统计学上常用的函数.-均值/标准差/偏度/峰度/正态分布程度检验/某一百分比处的数值.
通过scipy.info(stats) 获取scipy.stats模块的详细介绍
scipy.stats.norm 正态连续随机变量,其概率密度函数是 exp(-x**2/2)/sqrt(2*np.pi)
scipy.stats.norm.fit() #返回一个分布的均值和标准差
print(scipy.stats.norm.__doc__) #查看文档说明, dir(scipy.stats.norm) #查看方法和属性
scipy.stats.norm.rvs(size=5) #产生5个随机变量
scipy.stats.ttest_ind(a,b) #T-test检查两个分布是否显著不同
scipy.stats.normaltest() #normaltest检验
scipy.stats.kstest() #ktest
参考博客:https://blog.csdn.net/weixin_33733810/article/details/87025284
非冻结分布的参数估计的主要方法:
fit:分布参数的极大似然估计,包括location与scale
fit_loc_scale: 给定形态参数确定下的location和scale参数的估计
nnlf:负对数似然函数
expect:计算函数pdf或pmf的期望值。
loc, std = stats.norm.fit(samples) #极大似然估计拟合sample可能的分布形态
6、scipy.integrate: 积分模块。可以求多重积分,高斯积分,解常微分方程
res, err = scipy.integrate.quad(np.sin, 0, np.pi/2) #np.sin函数在[0, np.pi/2]上的积分
scipy.integration提供多种积分的工具,主要分为以下两类。
对给出的函数公式积分:quad dblquad tplquad fixed_quad quadrature romberg
对于采样数值进行积分:trapz cumtrapz simpz romb
7、scipy.sparse: 稀疏矩阵模块。提供了大型稀疏矩阵计算中的各种算法
scipy.sparse.rand(N, N) #创建稀疏矩阵
scipy.sparse.linalg.eigsh() #计算特征值
几种矩阵存储方式:coo/dok/csr/csc/dia/bsr
9、scipy.cluster: 聚类算法模块
scipy.cluster.vq.kmeans(obs,k_or_guess,iter=20,thresh=1e-05,check_finite=True) #k-means聚类
scipy.cluster.vq.kmeans2() ???
scipy.cluster.vq.vq(obs, code_book, check_finite=True) #返回观察对象最邻近的质心位置索引,和其距离
whitened???
scipy.cluster.hierarchy() #层次聚类 ??
8、scipy.spatial: 空间结构模块。提供了一些空间相关的数据结构和算法,如Delaunay三角剖分,共面点,凸包,维诺图,Kd树等
10、scipy.special: 特殊函数模块。里面有各种特殊的数学函数,可以直接调用,如贝塞尔函数
scipy.special.jn() #Bessel函数
scipy.special.ellipj() #Elliptic函数,Jacobian elliptic function
scipy.special.gamma() #Gamma function
scipy.special.erf() #Erf函数,计算高斯曲线下面积
11、scipy.fftpack: FFT(快速傅里叶变换)模块。可以进行FFT/ DCT/ DST
scipy.fftpack.fft() to compute the FFT
scipy.fftpack.fftfreq() to generate the sampling frequencies
scipy.fftpack.ifft() computes the inverse FFT, from frequency space to signal space
12、scipy.signal: 信号处理模块。包括样条插值,卷积,差分等滤波方法,还有FIR/IIR滤波,中值、排序、维纳、希尔伯特等滤波器,各种谱分析算法
scipy.signal.resample(): resample a signal to n points using FFT
scipy.signal.detrend() #去掉线性趋势部分
13、scipy.ndimage: 多维图像处理模块。提供一些多维图像处理上的常用算法
八、sklearn
Scikit-Learn是 Python下强大的机器学习工具包,它提供了完善的机器学习工具箱,包括数据预处理、数据降维、分类、回归、聚类、预测和模型分析等。Scikit-Learn依赖于 Numpy、 Scipy和 Matplotlib.
对于sklearn的模型推导式model,都适用 model.fit().
<1>对于监督学习:
model.fit(X,Y) #训练模型。X是数据,Y是标签.
model.predict(X_new) #对新的数据集进行标签预测。
model.predict_proba(X_new) #预测新的数据在每个分类标签上的概率。最高概率的分类标签用 model.predict()返回。
model.score() #对于分类或回归问题,都会有一个分支返回,分值越近于1,拟合的越好,越接近于0,拟合的越差。
<2>对于无监督学习
model.fit(X) #训练模型
model.predict() #预测分类标签
model.transform() #对于给定的无监督模型,将新的数据转换到新的
1、Preprocessing 数据预处理
from sklearn import preprocessing
<1>Standardization数据标准化--使样本沿axis=0方向上mean=0, std=1的处理。
对于特征的标准化、稀疏矩阵的标准化、离群点的标准化、中心核矩阵的标准化。
[i]preprocessing.scale() 将数据处理成沿axis=0方向上mean=0, std=1
[ii]preprocessing.StandardScaler() 先在训练集上计算mean/std,在测试集上调用TransformerAPI后才变换成标准的形式
[iii] preprocessing.normalize()
[iv] preprocessing.MinMaxScaler() 矩阵的标准化
[v] MaxAbsScaler(), maxabs_scale() 专门用于稀疏数据的标准化
[vi] robust_scale/ RobustScaler 离群点的标准化
<2>Non-linear transformation非线性变换
分位数变换和幂变换 quantile transforms and power transforms,单调变换。
[i] preprocessing.QuantileTransformer() / preprocessing.quantile_transform() 映射成值为0-1的均匀分布
[ii] preprocessing.PowerTransformer(method='box-cox') #映射成高斯分布。method默认是yeo-johnson
<3>Normalization归一化 --将样本放缩成具有单位范数的处理。
[i] preprocessing.normalize(X,norm='12') #归一化 ,norm可选'11','12' .
preprocessing.Normalizer() #transform API 接口时
<4> Encoding categorical features编码分类特征--当特征不是连续值给出,而是分类描述的时候,重新将特征编码。
preprocessing.OrdinalEncoder() #用整数将特征重新编码。值是离散的,常会被解释成有序的。
preprocessing.OneHotEncoder() #one-hot编码,把N类的分类特征转成二进制的0-1编码
<5> Discretization 离散化
[i]k-bins离散化
preprocessing.KBinsDiscretizer(n_bins=[,,,] ,encode='ordinal' )
[ii] Feature binarization 特征二值化
preprocessing.Binarizer()
sklearn.neural.network.BernoulliRBM()
<6>Imputation of missing values 缺失值填充
<7>Generating polynomial features 生成多项式特征
from sklearn.preprocessing import PolynomialFeatures
<8> Custom transformers 自定义变换
from sklearn.preprocessing import FunctionTransfomer
<?>特征工程
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier()
2、Dimensionality reduction 数据降维 --矩阵分解问题
<1>Principal component analysis (PCA)主成分分析
在scikit-learn中,PCA/IPCA是一个transformer对象,可以用fit方法在测试集上学习到n个主成分,然后可以将新的数据集映射到这些主成分上。
[i]Exact PCA and probabilistic interpretation提取主成分及概率解释 --缺点:只支持批处理,有内存限制
[ii]Incremental PCA 增量PCA(IPCA) ---大数据量时替代PCA的方法
from sklearn.decomposition import PCA, IncrementalPCA
ipca = IncrementalPCA(n_components=n_components, batch_size=10)
X_ipca = ipca.fit_transform(X)
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
[iii] PCA using randomized SVD 使用随机SVD的PCA
SVD奇异值分解
[iv] Kernel PCA核的主成分分析
[v] Sparse principal components analysis (SparsePCA and MiniBatchSparsePCA)稀疏主成分分析
<2>Truncated singular value decomposition and latent semantic analysis截断(SVD)奇异值分解和潜在语义分析
<3>Dictionary Learning 词典学习
[i]Sparse coding with a precomputed dictionary用预计算词典进行稀疏编码
[ii] Generic dictionary learning通用字典学习
[iii] Mini-batch dictionary learning 小批量字典学习
<4>Factor Analysis (FA)因子分析
<5>Independent component analysis (ICA)独立成分分析
<6>Non-negative matrix factorization (NMF or NNMF) 非负矩阵因式分解
[i]NMF with the Frobenius norm 具有Frobenius规范的NMF
[ii]NMF with a beta-divergence β发散的NMF
<7> Latent Dirichlet Allocation (LDA)隐含Dirichlet分配--文本处理算法
3、Regression 回归
<1>线性回归
from sklearn.linear_model import Linearregression #导入线性回归模型
model= Linearregression() #建立线性回归模型
print (model)
model.fit(X,Y)
4、Classification 分类
<1>朴素贝叶斯分类
from sklearn.naive_bayes import GaussianNB
<2>KNN分类
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,weights='uniform',) #knn模型
<3>决策树与随机森林
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
<4>支持向量机
from sklearn.svm import SVC
model = SVC()
5、Clustering 聚类
<1>k-means聚类
6、Model Selection 模型分析