LinkedHashMap源码剖析
LinkedHashMap学习记录
0、简介
这篇又是一个学了忘,忘了学的JDK源码,今天抽空整理下自己的学习记录。LinkedHashMap和HashMap相比是多了可以按照插入顺序遍历的功能,下面开始分析下其具体的实现。此次主要记录以下几个点。
1、LinkedHashMap使用示例
2、LinkedHashMap构造函数及属性
3、LinkedHashMap核心方法分析
1、LinkedHashMap使用示例
下面使用LinkedHashMap的特性来做个示例
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("user1","zhangsan");
linkedHashMap.put("user2","lisi");
linkedHashMap.put("user3","wangmazi");
Iterator<Map.Entry<String,String>> iterator = linkedHashMap.entrySet().iterator();
while(iterator.hasNext()){
System.out.println(iterator.next().getKey());
}
}
}
output result
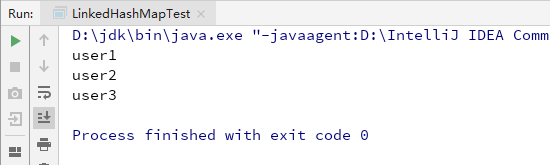
2、LinkedHashMap构造函数及属性
类关系图
构造函数
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
节点结构
// 这个是LinkedHashMap每个元素的数据结构
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
Entry的继承结构图
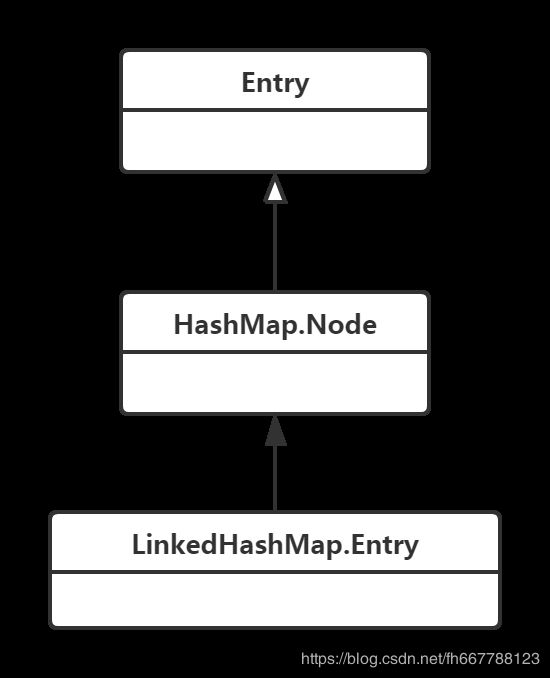
由Entry结构和before和after属性可知,LinkedHashMap节点之间有着双向链表的关系。
其他属性
// 链表头引用
transient LinkedHashMap.Entry<K,V> head;
// 链表尾部引用
transient LinkedHashMap.Entry<K,V> tail;
// 这个字段主要用来决定迭代顺序的
// 若为true,迭代顺序按照访问顺序排列(lru),最新的数据在链表末尾
// 若为false,则按照插入的顺序进行迭代访问
final boolean accessOrder;
3、LinkedHashMap核心方法分析
下面我们分析下LinkedHashMap如何维护链表结构的,当我们调用put方法时候实际调用的是HashMap的put方法,但是table内部放的节点数据类型都是LinkedHashMap内部的Entry数据类型,且创建新节点时候调用的是LinkedHashMap的newNode方法,下面就看看newNode的方法实现。
newNode
此方法是LinkedHashMap中添加一个新的节点时候维护链表要做的操作。链表一般是尾插法。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// linkNodeLast实现
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
// 先记录尾结点
LinkedHashMap.Entry<K,V> last = tail;
// 让尾结点为新的节点
tail = p;
// 如果原先尾结点为空,则说明链表没元素
// 则将头结点指向新加入的节点
if (last == null)
head = p;
else {
// 若原先的尾结点不为空,则说明链表不为元素不为0
// 将新加入节点的before节点设为原先的尾结点
// 将原先尾结点的after设为新接入的节点
p.before = last;
last.after = p;
}
}
下面我们再来看看获取指定元素的方法有什么小变化。
get(Object key) 或者 getOrDefault(Object key, V defaultValue)
public V get(Object key) {
Node<K,V> e;
// 默认还是调用HashMap的getNode()获取节点元素
if ((e = getNode(hash(key), key)) == null)
return null;
// 前面介绍过accessOrder属性的用处,若为true
// 说明遍迭代顺序要按照访问的顺序来,那么每次访问后就要更新链表元素位置
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果节点已经在尾部则不作操作
// 要不然将最新访问的节点放在链表尾部
if (accessOrder && (last = tail) != e) {
// 下面将节点移动到链表尾部很简单
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
当调用LinkedHashMap的remove()方法时候,其实是调用的HashMap的remove()方法,HashMap的remove()方法执行到最后会调用afterNodeRemoval(Node
afterNodeRemoval(Node
void afterNodeRemoval(Node<K,V> e) { // unlink
// 分别使用临时变量记录删除的节点、删除节点前一个节点、删除节点的后一个节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 把删除节点的前后节点置空,方便垃圾回收
p.before = p.after = null;
// 如果删除节点的前一个节点为空,则说明是头结点,所以更新头结点引用变量的值
if (b == null)
head = a;
else
// 删除节点前一个节点不为空,那么将删除节点前一个节点的after指针
// 改为删除节点的后一个节点
b.after = a;
// 如果删除节点的后一个节点为空,则说明删除的是尾结点,那么更新尾结点引用变量的值
if (a == null)
tail = b;
else
// 删除节点的后一个节点不为空,那么将删除节点的后一个节点的before
// 引用指向删除节点的前一个节点
a.before = b;
}
下面再来看看是如何获取LinkedHashMap的迭代器对象的实现
linkedHashMap.entrySet().iterator()
// 获取LinkedHashMap的entrySet
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
// 实际创建了一个LinkedEntrySet对象
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
public final Iterator<Map.Entry<K,V>> iterator() {
// 方法内部又创建了一个LinkedEntryIterator对象
return new LinkedEntryIterator();
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
// 这个是调用next方法的实现
public final Map.Entry<K,V> next() { return nextNode(); }
}
// LinkedHashIterator是LinkedHashMap的内部类
// 构造时候让它自己的next成员变量指向LinkedHashMap所维护的链表的头引用
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
// 当调用迭代器的next()方法实际是调用了下面这个方法
final LinkedHashMap.Entry<K,V> nextNode() {
// 从头指针向下遍历
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
// 遍历期间若有结构变化,抛出ConcurrentModificationException异常
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
总结
以上就是本次学习LinkedHashMap的全部记录,LinkedHashMap最大的特性就是可以按照键值对添加的顺序遍历,若有这个需求的地方使用LinkedHashMap就很方便。