使用深度学习从X射线图像检测由COVID-19引起的冠状肺炎(已开源)
最近世界卫生组织(W.H.O.)宣布2019年冠状病毒病(NCOV-19)是一种流行病,其特征是新型冠状病毒在全球范围内迅速蔓延。随着各国政府争先恐后地关闭边界,进行接触者追踪并提高对个人卫生的认识以努力遏制病毒的传播。
由于预计全世界每天的实际病例都会迅速增加,限制诊断的一个重要因素是病毒病理学检查的持续时间,这种检查通常在市中心的实验室中进行,而实验室通常需要耗时的精度。这引起了严重的问题,主要是这样的事实,即作为携带者的个人无法及早被隔离,因此他们能够在不受限制的行动的关键时期感染更多的人。另一个问题将是当前诊断程序的昂贵的大规模实施。可以说,最脆弱的人群是发展中国家偏远地区的人们,他们的医疗条件普遍较差,无法获得诊断。一次感染可能对这些社区有害,获得诊断至少将为他们提供抵抗该病毒的机会。


国外城乡差异不仅在于人数,还在于获得医疗资源的途径。在这种大流行时期,这种缺乏获取途径可能是致命的。
最近一项新研究展示了使用深度学习技术在计算机断层扫描(CT)扫描中扫描COVID-19的前景,并且已被推荐作为预先存在的诊断系统的实用组件。该研究在1119次CT扫描中使用了带有初始卷积神经网络(CNN)的转移学习。该模型的内部和外部验证准确性分别记录为89.5%和79.3%。主要目标是允许模型提取COVID-19中存在的放射学特征。
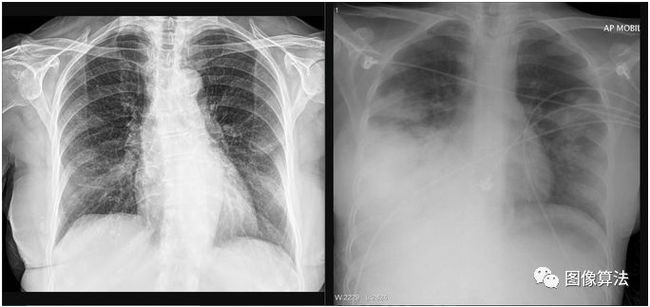
左:COVID-19阳性X射线。右:链球菌感染。(两者均被许可为CC-NC-SA)。两种图像均显示肺炎。有什么可以区分他们的?
图像被收集为正在构建的开源数据集,文章底部给出地址。
当研究在他们的模型上实现了惊人的准确性时,作者决定使用不同的体系结构训练和实现模型,以期提高准确性。作者决定在CT扫描中使用胸部X光片(CXR)的原因有两个:
-
与进行CT扫描相比,人们更容易获得CXR,特别是在农村和偏远地区。还将有更多潜在数据可用。
-
如果放射科医生和医学专业人员失去了感染病毒的能力(例如如果自己生病的话)。系统对于继续进行诊断至关重要。
与CT扫描作为诊断源相比,使用CXR的主要障碍是缺乏可以通过视觉确认的COVID-19细节。在CT扫描中很难看到COVID-19症状,例如肺结节。我想测试具有足够图层的模型是否可以检测质量较低但实用的图像。因此,我的模型是关于Resnet CNN模型是否可以使用相对便宜的CXR有效检测COVID-19的概念证明。

COVID-19肺部扫描数据集目前有限,但是我发现用于该项目的最佳数据集来自COVID-19开源数据集。
它包括来自公开研究的报废的COVID-19图像,以及具有各种引起肺炎的疾病(例如SARS,链球菌和肺孢子虫病)的肺部图像。如果您拥有存储库可以接受的任何适当的扫描图像,以及它们的引文和元数据,请帮助构建数据集以改进将依赖于此的AI系统。
作者仅在查看CXR的后前视图(PA)时训练了我的模型,CXR是X射线扫描的最常见类型。 在Resnet 50 CNN模型上使用了转移学习(在Resnet 34上经历了几个时期之后,我的损失激增了),并且总共使用了339张图像进行训练和验证。所有的实现都是使用fastai和Pytorch完成的。
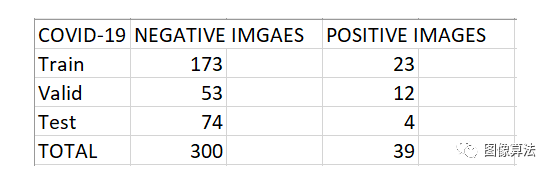
由于缺少COVID-19图像,数据严重扭曲。在将数据随机拆分25%之后拍摄。从一开始就将测试集设置为78。
鉴于在撰写本文时缺少可用的公共数据,数据严重歪斜(COVID-19为35幅图像,非COVID-19为226幅图像,其中包括正常和患病的肺部图像)。我决定将所有非COVID-19图像归为一组,因为我只有针对不同疾病的稀疏图像。我使用来自该Kaggle数据集*的健康肺部X射线图像来增加标记为“其他”的X射线扫描的大小,然后将数据随机分割25%。训练集由196张图像组成,验证集由65张图像组成,测试集由78张图像(完全由额外的数据集组成)组成。已验证外部数据集不包含来自开源数据集的任何重复图像。根据我建立其他分类器的经验,所有图像的大小都调整为512 x 512像素,因为它的效果要优于1024 x 1024像素。


上:训练有2个时期的第一次迭代。培训损失远高于验证损失,这是不合时宜的明显信号。下:训练的第二次迭代。所有列均与左侧的列相同。
使用fastai的fit_one_cycle政策实施来运行前几个时期,表明适应不足从一开始就是一个问题。我决定增加纪元的数量,并获得学习率的范围。在其余的培训中,我奉行积极的策略,即以大量的时间段进行训练,然后使用fastai的lrfinder重新调整学习率,然后继续以较高的时间段进行训练,直到训练损失下降到与验证损失相当的水平为止。
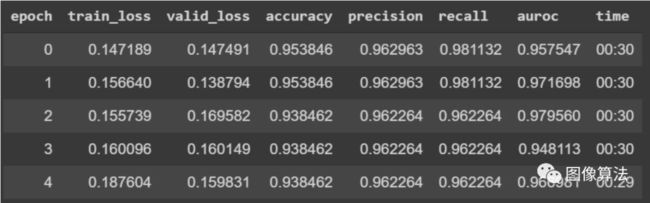
最后,经过数十次迭代,我设法将训练损失降低到与验证损失相似的水平,同时保持了较高的准确性。该模型的最终内部验证准确度记录为93.8%。
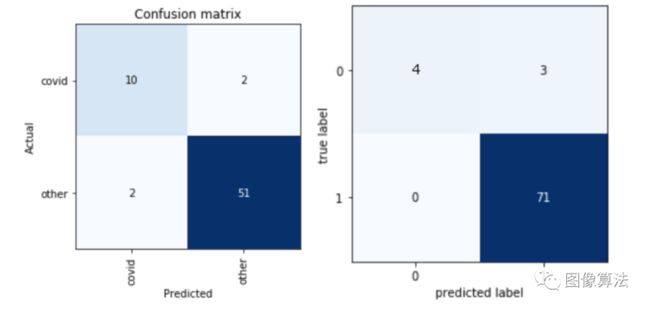
左:该模型在验证集上运行良好,带有一些误报(FP)和误报(FN)。右图:模型在测试集上运行,FN数为零,但三个FP。偏斜分布确实会影响True阳性结果,并且需要更多数据进行验证。列代表与左侧混淆矩阵相同的标签。
如上面的混淆矩阵所示,该模型在验证集上的表现非常好,对于误报和误报只有两种情况。继续测试数据,在78张图像中,正确预测了75张,外部验证准确率为96.2%。尽管我们在测试数据中得到了3个误报,但是对于所有这些情况,模型的预测都接近50%。这表明它混淆了X射线图像的某些功能,但结论对COVID-19呈阳性并不能起决定性作用。然而,最令人惊讶的事情是它预测了正确的阳性病例。该模型从未在这些图像上进行过训练,但仍设法以99%的确定性预测图像中的肺部对COVID-19呈阳性。
对于深度学习模型在对COVID-19扫描进行分类时,这是前所未有的准确性,但这只是一个明显缺乏X射线数据的初步实验,尚未得到外部卫生组织或专业人员的验证。尽管我更担心误报,但将来我会针对误报对模型进行调整,但目前由于数据不足而无法进一步调整。
同样,该模型是一种概念验证,但如果进一步发展,则具有巨大的潜力来解决现有的有限诊断范围和未来可能出现的人力短缺问题。它可以帮助阻止这种大流行的蔓延,并创造新的方法来预防未来的大流行。
作者提供了代码模型和结果,供研究人员使用。一旦有更多数据可公开访问,我计划通过在更加平衡的数据集上对其进行测试来更新模型。作者还计划实现GRAD-CAM,以可视化方式查看模型重点关注的功能。
作者在训练后意识到,训练和测试图像中有很大一部分来自小儿患者,这可能会影响该模型在成人扫描中的性能。但是,其性能仍然需要更多数据进行验证。该模型还可以通过将来的培训进行改进。
作者对阳性病例进行上采样以解决这些图像的不足,并且应该包括更多细菌性和病毒性肺炎的图像,以使其更加健壮。如果您尝试改善模型,请执行此操作。
由于对COVID-19的放射学标记物的研究是一个活跃的研究领域,仍然有很多发现,因此我在解释结果时要谨慎,因为该模型已识别出COVID-19所独有的正确特征。
相关数据集:
https://github.com/ieee8023/covid-chestxray-dataset
https://github.com/ajsanjoaquin/Pneumothorax
https://github.com/ajsanjoaquin/COVID-19-Scanner/blob/master/NCOV_test_results.csv
开源代码:
https://github.com/ajsanjoaquin/COVID-19-Scanner
更多论文地址源码地址:关注“图像算法”微信公众号
