TensorFlow训练模型的重载(不需要重定义原有的计算图)
前言: 当我们已经训练好一个网络之后,并且将模型保存了,那么当我们想在另一个电脑上使用怎么办,对于Keras来说非常简单,只需要直接load model,然后直接调用predict方法就可以了,但是TensorFlow毕竟封装性不如Keras好,那么当需要加载时我们还需要重新建立一遍计算图么?不用的,直接取我们想要的变量即可。看下面
其实我们只是不需要手动建立计算图,而是从.meta文件导入原来的计算图,然后取我们所需要的输入,输出,准确率,损失等变量就行了;
1、定义了如下的网络结构,并且在训练完毕后对模型进行了保存: (该网络结构只是为了举例)
tf.reset_default_graph()
###——————————————————定义神经网络——————————————————
with tf.name_scope('X_Y_input'):
X=tf.placeholder(tf.float32, shape=[None,time_step_train,input_size],name="x_input")
Y_=tf.placeholder(tf.float32, shape=[None,output_size],name="y_input")
with tf.name_scope('keep_prob'):
keep_prob = tf.placeholder(tf.float32,name="keep_prob")
with tf.name_scope('lstm'):
#输入层、输出层权重、偏置
w_in=tf.Variable(tf.random_normal([input_size,rnn_unit]),name="w_in")
b_in=tf.Variable(tf.constant(0.1,shape=[rnn_unit,]),name="b_in")
w_out=tf.Variable(tf.random_normal([rnn_unit,1]),name="w_out")
b_out=tf.Variable(tf.constant(0.1,shape=[1,]),name="b_out")
with tf.name_scope('lstm_input'):
input_x=tf.reshape(X,[-1,input_size])
with tf.name_scope('lstm_rnn'):
lstm_cell=tf.nn.rnn_cell.BasicLSTMCell(rnn_unit)
lstm_cell=tf.nn.rnn_cell.DropoutWrapper(lstm_cell,input_keep_prob=1.0, output_keep_prob=keep_prob)
cell=tf.nn.rnn_cell.MultiRNNCell([lstm_cell]*num_layer)
init_state=cell.zero_state(batch_size,dtype=tf.float32)
output_rnn,final_states=tf.nn.dynamic_rnn(cell, input_rnn_r,initial_state=init_state, dtype=tf.float32)
output_rnn_last=output_rnn[:,-1,:]
with tf.name_scope('lstm_out'):
pred_out=tf.matmul(output_rnn_last,w_out)+b_out
##——————————————————定义误差 学习率 和优化器——————————————————
global_step = tf.Variable(0,name="global_step")
with tf.name_scope('learning_rate'):
learning_rate = tf.train.exponential_decay(lr,global_step,len(batch_index_train),decay_rate, staircase=True)
with tf.name_scope('loss_mse'):
loss_mse=tf.reduce_mean(tf.square(pred_out-Y_))
tf.summary.scalar('loss_mse',loss_mse)
with tf.name_scope('train_op'):
train_op=tf.train.AdamOptimizer(learning_rate).minimize(loss_mse,global_step=global_step)
# train_op=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_mse,global_step=global_step )
#——————————————————定义全局变量保存器——————————————————
saver=tf.train.Saver(max_to_keep=20)2、重新导入模型:(不需要再重新定义一遍上述的图了额)
sess= tf.Session()
saver=tf.train.import_meta_graph(modelfile) # end with .meta 文件
graph=tf.get_default_graph()
tesor_name_list=[tensor.name for tensor in graph.as_graph_def().node] # 变量名
X=graph.get_tensor_by_name('X_Y_input/x_input:0') # 我们需要的输入
Y=graph.get_tensor_by_name('X_Y_input/y_input:0')
keep_prob=graph.get_tensor_by_name('keep_prob/keep_prob:0') # 需要的参数
pred_out=graph.get_tensor_by_name('lstm/lstm_out/add:0') # 我们需要的预测输出
module_file = tf.train.latest_checkpoint(model_parfile) # .meta 所在的文件夹名称
saver.restore(sess, module_file)
for step in range(batch_num):
prob=sess.run(pred_out,feed_dict={X:test[step*4096:(step+1)*4096],keep_prob: 1.0}) # 上述重新加载的参数在此处都用到了
*********************************
***************************其中里面的变量名列表是这样的:
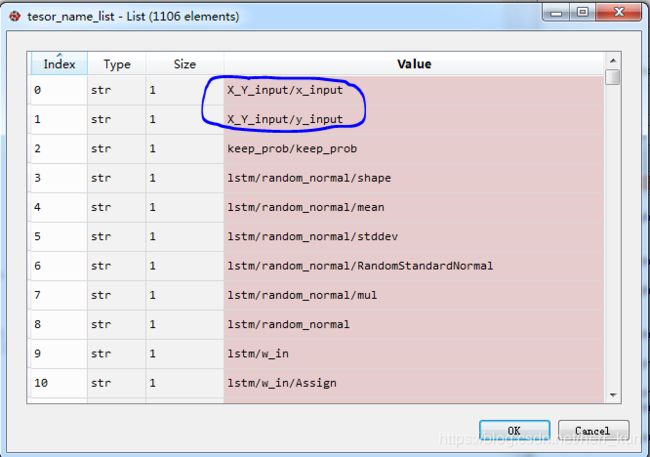
注意:当我们需要加载的模型为最新的模型的时候,上述方式是没有任何问题的,但是当我们想加载某一历史模型的时候,比如我们保存的模型文件夹是这样的,如下图:也就是里面也好几个历史模型,其中150批次是最新的,如果这里我们想加载第100批次的模型的时候(不同的批次之间他们的计算图是一样的,只是权重不一样),那么就可以修改上述代码为:(否则不修改的话就会造成每次我们都是加载的最新的权重)
#module_file = tf.train.latest_checkpoint(model_parfile) # 去掉该句
saver.restore(sess, module_file[:-5]) # 原来的module_file改为module_file[:-5],
#也就是加载该批次的权重,而不是从checkpoint文件中获取信息,查找最新批次的权重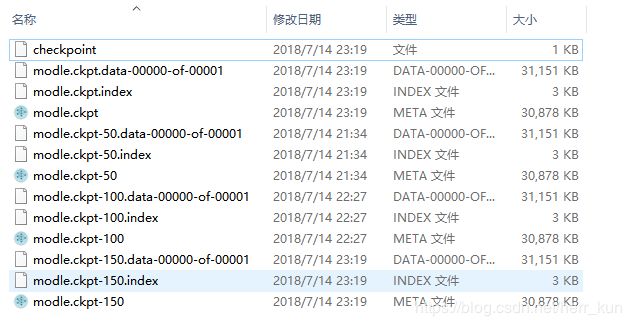
参考博客: https://blog.csdn.net/sjtuxx_lee/article/details/82663394