论文品读:Learning both Weights and Connections for Efficient Neural Networks
https://arxiv.org/abs/1506.02626v3
这是一篇关于模型压缩的15年文章,到目前为止(18年11月)有450的被引
文章介绍了一种参数剪枝(weights pruning)方法,应该算是最基础的一种方法了,直接按照参数是否大于某个阈值来判断哪些参数是重要的,哪些参数是不重要。文章主要目的是想要压缩模型大小后将模型运行在能耗更小的内部SRAM里,在速度提升上文章没有过多强调。
在不降低精度的前提下,在VGG-16上取得了13倍的参数压缩率,从138M个参数到10.8M个参数。
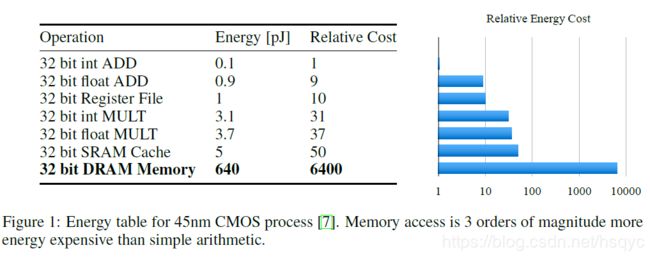
图1给出了同一处理器下各种操作所消耗能量的大小,主要看片内小存储的SRAM和片外小存储DRAM的能量消耗对比,可以看出在模型参数量很大的情况下,在进行运算的时候会大量访问DRAM,从而造成能量的大量消耗,这对移动端处理器是不能接受的。
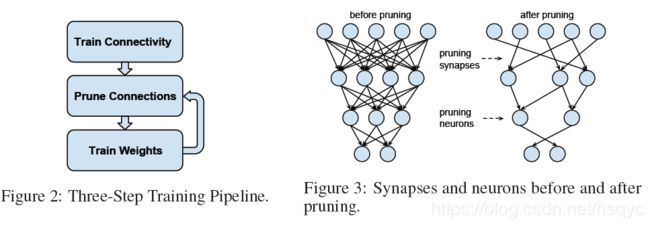
图2给出了剪枝的过程。第一步和平时一样训练网络。第二步剪枝,删除w低于阈值的神经元,如图3。第三步重新训练。第二、三步多次循环迭代。
有几个问题:
1.在第一步训练的时候,文章说“Unlike conventional training, however, we are not learning the final values of the weights, but rather we are learning which connections are important.”啥意思,不是把模型训练到在测试集上达到一定精度么?那训练到什么地步算是“learning which connections are important”?
2.第二第三步迭代循环是指每次迭代剪枝、重训练一层网络,然后多次迭代循环每一层网络?还是说对于一层网络,也要进行多次剪枝、重训练?我偏向于后者。那么迭代停止的条件是什么呢,是在测试集上达到一定精度么?

因为剪枝后在一定程度上相当于进行了drop-out了,所以剪枝后重训练的时候drop-out的概率应该小一点,这个概率应该跟剪枝前的drop-out概率、剪枝前后的神经元个数有关。等式2给出了剪枝后drop-out的概率Dr的表达式。其中D0表示剪枝前的drop-out概率,Ci由等式1给出,其中Ni表示当前层神经元个数,Ni-1表示上一层神经元个数。Cir表示重训练的Ci,Cio表示剪枝前的Ci。
3.3 Local Pruning and Parameter Co-adaptation
在重训练阶段,我们应该让那么没有被剪掉的参数保持不变。比如我们对FC1层进行剪枝后,应该保持其他层参数不变,只重新训练FC1层。
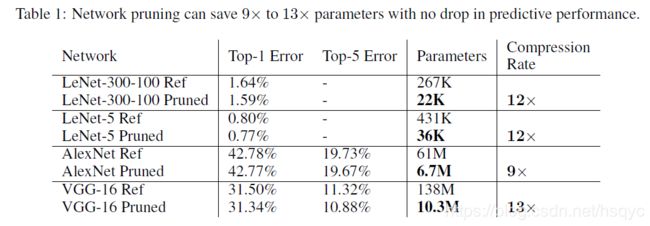
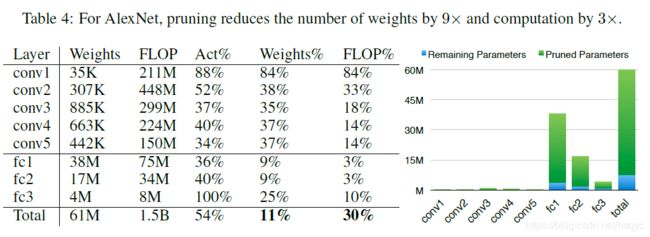
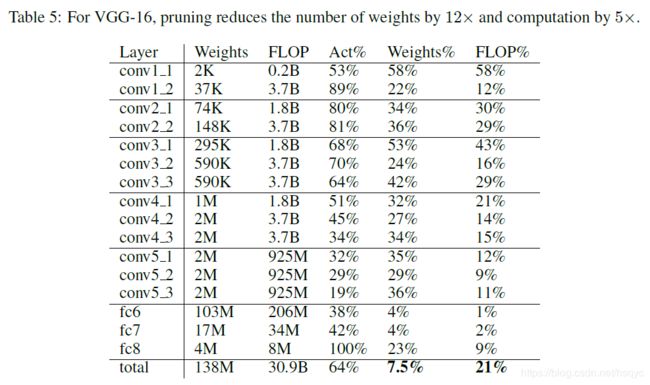
表一应该没什么好说的,剪枝前后的对比。LeNet是在MNIST上测试的,AleNet、VGG是在ImageNet上测试的
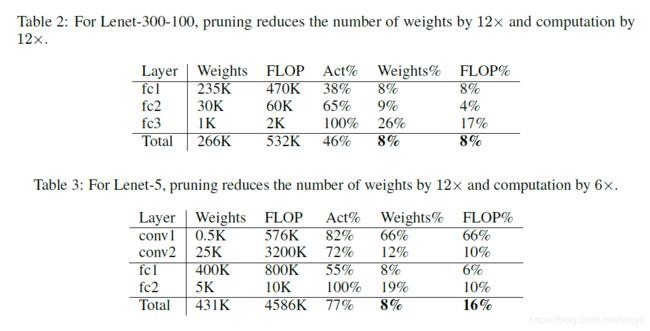
表2、3、4、5都是各个网络每层具体的剪枝的效果图。Weights、FLOP都是指剪枝前的,而Weights%、FLOP%都是指剪枝后的量为剪枝前的多少百分比.
但是这里的FLOP具体数值好像有点跟我们平时说的不一样。具体我也不是很清楚

图4类似一个可视化的图。横坐标是输入图像28*28拉伸后的784个点,纵坐标是全连接层的300个神经元.蓝色的部分代表该位置的参数不为0.图像整体呈现一个28条带子的状态,这是因为输入图像的手写字符主要集中在图像的中央,所以有字符的这些点对应的权重会较大,而那些图像周围的点会倾向于为0.原文放进来吧

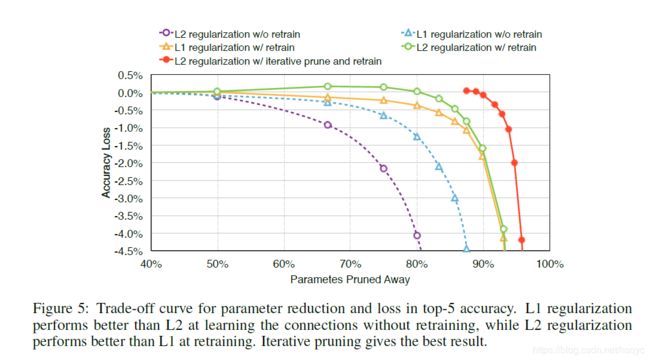
图5比较了是否重训练(紫圆圈和绿圆圈)、用L2还是用L1正则化(黄三角和绿圆圈、紫圆圈和蓝三角)、是否迭代剪枝(红圆圈和绿圆圈)。可以看出重训练、用L2正则、迭代剪枝的效果更好。关于正则,在作者发现在不重新训练的时候L1更好,重新训练的话L2更好。还有就是哪怕你只是剪枝,之后啥都不干,也能在不降低精度的情况下减掉50%的参数。图示当中的w/0意思应该类似without,w/的意思应该是with
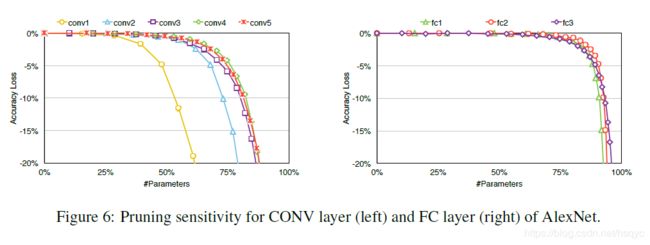
图6显示了每个层对剪枝的极限承受能力。相对来说,卷积层要比全连接层更敏感,能够裁剪的空间相对来说要少一点。尤其conv1最敏感,这是因为本身输入图像只是3通道的原图,冗余的信息相对来说要少一点。我们在对每个层设定裁剪阈值的时候要根据各个层的敏感程度,越敏感的阈值要设的更大一点。
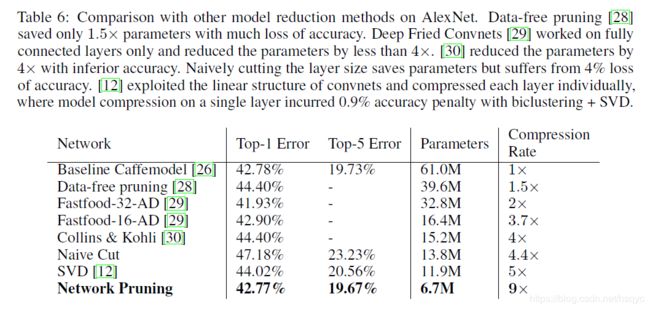
与其他一些裁剪方法的对比,作者的压缩率更高。但是没有给出速度的提升
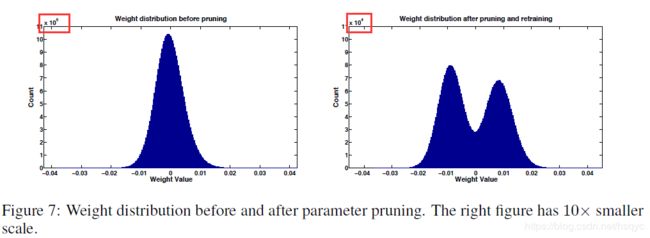
图7是裁剪前后的权重直方图,除了靠近0的权重的数量少了外,值得注意的是裁剪后权重的数量小了一个数量级。