tensorflow tensorboard使用方法、应用场景和常见问题
详细介绍:
基础操作两方面:
第一方面:“制作”各种标量、记录节点,图标、图片等的记录汇集,sess.run从计算图得到一次汇集的记录。
关于sess.run(merged),可以把这个也当做计算图中得到了一个结果,只是不同用途。既然是计算图,就少不了要feed数据,feed的数据不同,得到的结果也就不同,如果使用了错误的feed数据,很可能得到的绘制结果也不符合预期,下边会有例子介绍!
剩下的也就是scalar和histgram对tensor形状的要求不同,输入错了自然报错(手动滑稽),image的话,也要先reshape到合适的形状。
第二方面:利用本graph初始化writer,把sess.run得到的记录通过writer写入文件,关闭writer。
唯一注意的就是那个global_step的意义,这个step也就是绘制图标的横轴坐标了,如果用普通的i,如果断点续训从头开始计算,那么图标也就绘制烂了,所以最好是用有记录的global_step,能够保证断点续训的图片绘制完整。
tf.summary.scalar/image/histogram()
merged = tf.summary.merge_all()
summary = sess.run(merged)
writer = tf.summary.FileWriter(logdir, graph=sess.graph)
writer.add_summary(summary, global_step=i)
writer.close()
两种合并方法,第一种全合并,比较简单;第二种指定,精简,比如同时观察训练集和测试集的准确率,参数之类的不需要也显示两份。
summary_ce = tf.summary.scalar('cross_entropy', cross_entropy)
summary_accuracy = tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
test_merged = tf.summary.merge(inputs=[summary_ce,summary_accuracy])
特殊用法:
同时显示训练集和测试集曲线
用两个writer,指定两个路径,分别记录训练集和测试集的准确率,运行tensorboard同时读取两个event文件。
#tensorboard --logdir = event1:"dir1",eventrun2:"dir2"
应用场景
应用:对比测试集与训练集的准确率
如果是带dropout的训练,不要在train同时得到accuracy,会出现准确率倒挂,训练准确率低于测试准确率(蓝线).
![]()
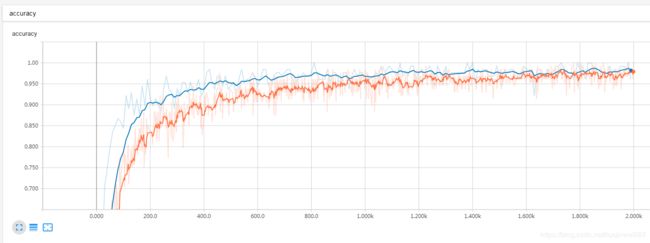
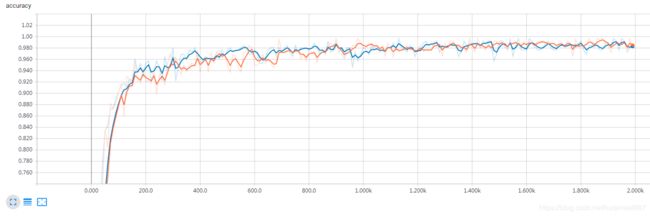
改完了也不能明显看到“训练准确率高于测试准确率”的情况
也有一方面原因是conv解MNIST太简单了,拉不开差距,test用的batch太小了,不容易反应整体,拉不开差距,因为机器性能的限制,一次不能运行整个测试集,summary是拿tensor,是tensor就得feed数据,feed数据就有size限制,又不可以在python里自己做循环和平均,这是个问题。
问题:两个event的显示颜色不如人意
因为运行参数等于dict形式,training排在testing后边,所以颜色调转。自己改改名字就好了
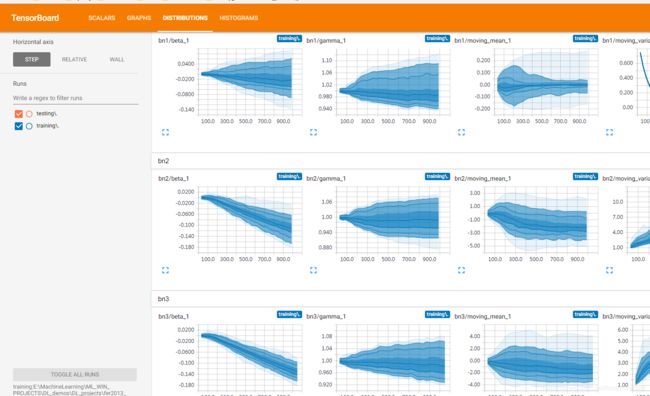
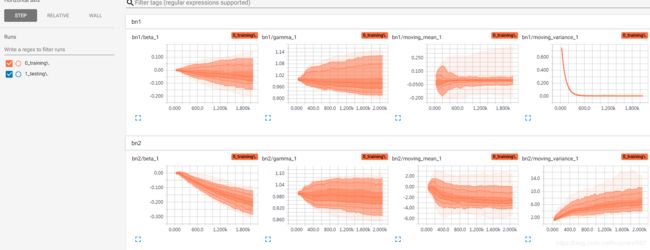
应用:利用命名空间分类查看
变量太多的时候,看起来会很混乱,使用命名空间就很有用了。
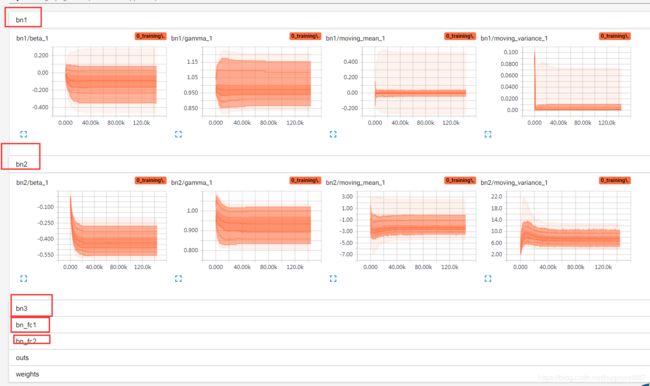
例如第二个FC对应的BN层,先get到tensor,然后把tensor添加到histogram,命名,加bf_fc2前缀
gamma = tf.get_default_graph().get_tensor_by_name(name='bn_fc2/gamma:0')
beta = tf.get_default_graph().get_tensor_by_name(name='bn_fc2/beta:0')
moving_mean = tf.get_default_graph().get_tensor_by_name(name='bn_fc2/moving_mean:0')
moving_variance = tf.get_default_graph().get_tensor_by_name(name='bn_fc2/moving_variance:0')
tf.summary.histogram('bn_fc2/gamma', gamma)
tf.summary.histogram('bn_fc2/beta', beta)
tf.summary.histogram('bn_fc2/moving_mean', moving_mean)
tf.summary.histogram('bn_fc2/moving_variance', moving_variance)
应用:增加GRAPH可读性
大多数时候,计算图中,除了主流程,还会有各种依赖关系和边角操作,增加图像复杂度,降低可读性,可以把无关操作从图中去除。

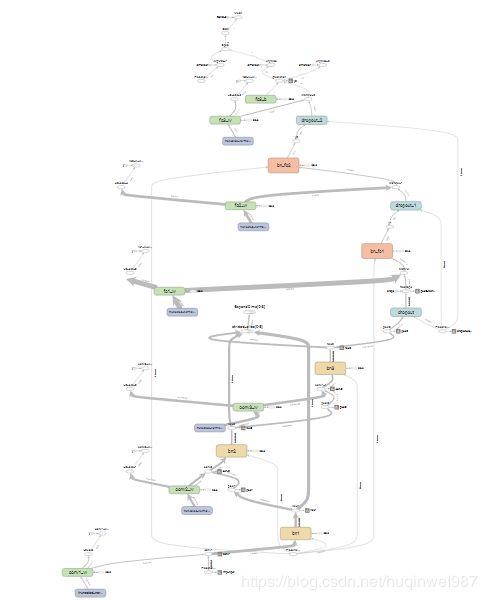
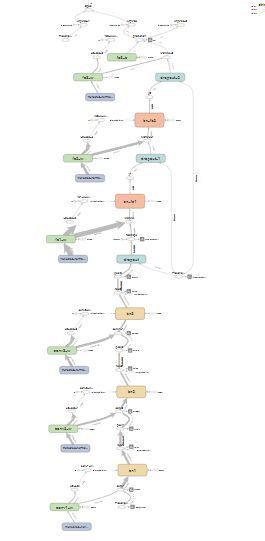
应用:验证ReLU“最优”bias初始值
初学可能不知道bias改初始化成什么,看过些代码可能认为biases初始化为0.1合适,但是不看图是不知道为什么的。
通过tensorboard打印biases的分布,可以看到想要的答案。
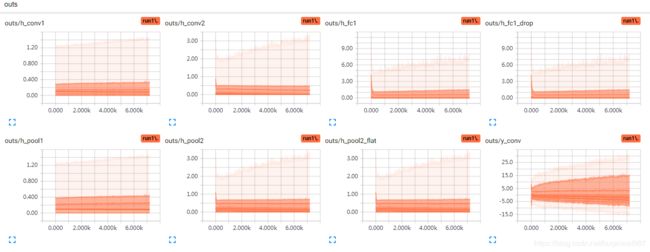
如下:两层conv(32,64),ReLU激活,两层fc(包括输出层,1024,10),识别MNIST。
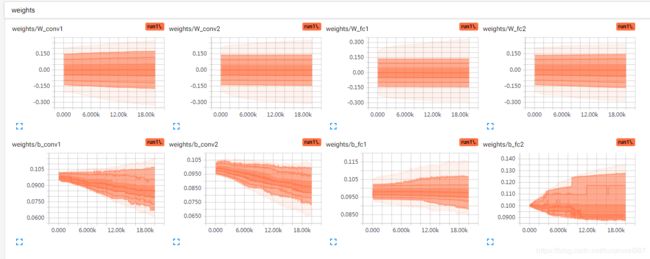
W初始化0,b初始化0.1,W的分布很稳的在0附近。
batch=256,20000步,b有所下降,但是也没接近0
其他不动,biases初始化变成0.2
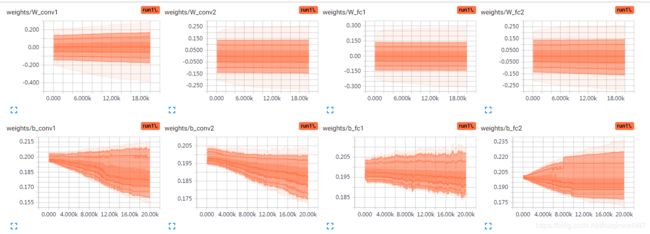
其实按比例看的话,0.2和0.1趋势差异并不明显,因为我也没空无限训练下去,20k截止。
初始化biases为0.0:
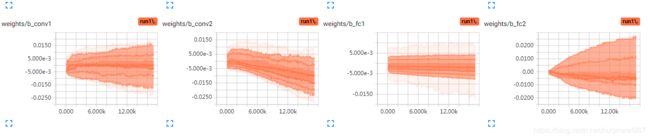
也没什么上升趋势,证明0.1不一定代表最优,但是这个模型也只是个例。总之,训练之后的biases比较趋近0~0.2这个范围。
虽然初始0也没上升到0.1的趋势,但是也不能用0,0有另一个缺点,ReLU负轴输出0,正轴斜率是1,w和b都是0的话,正反都输出0,不利于训练。
biases初始化0.0和0.1的各层输出分布:不能从图形上直接说0.0很不好,但是对比0.1,仔细看纵坐标,确实0.1的初始化初期输出的分布更广泛一些,而训练之后的输出分布,也是趋向于更宽泛。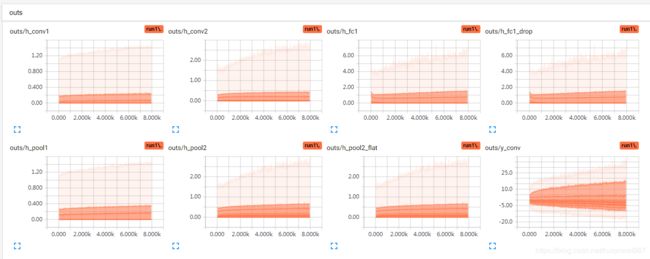
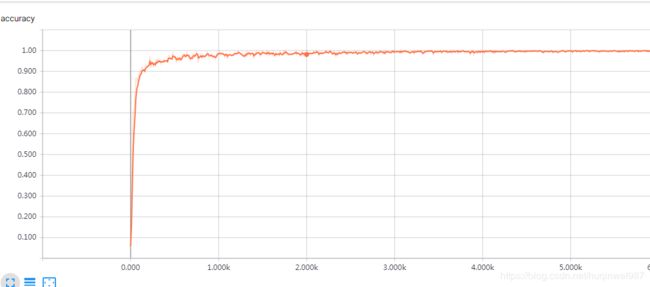
准确率变化区别不明显
前边用的ReLU(0.1针对ReLU),作为对比,用sigmoid试一下(缩减步数):
初始化0.0(有变负数趋势)
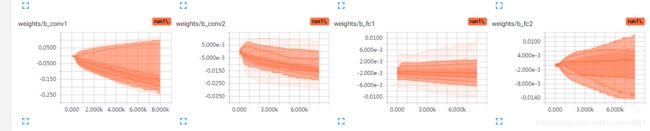
初始化0.1(第一层有明显的变负趋势,后边不明显)

结论:
所以,0.1是一个自然选择,并且人工trade-off的值。
第一层影响比较大,趋势明显,后边的逐渐不明显,如果有BN,可能进一步衰减。
考虑到模型宽容度过高,很早准确率就封顶,实验效果也不好,还有不同的模型,复杂模型和简单模型也不一样,情况太多,没法测完,有机会再完善。
但是很明显,0.1也不是真理,每一个模型,每一层,都多少有些不一样。
todo:更进一步,为什么恰巧是0.1?可以观察用不同的数据集不同的标签,比如20个标签或者5个标签,是否都是0.1附近最优?