基于机器学习的攻击检测(二)下-lstm实现
基于机器学习的攻击检测(二)下-lstm实现

ReLuQ
交叉学科就像交叉特征一样有趣
1 人赞同了该文章
上一篇我们讲了一下lstm的简单结构以及正向传播的过程,那么这一期回归我们的目标,使用lstm来检测攻击
我们知道,循环神经网络的一大优势就是他能够保存一些结构化数据的序列信息并对对其作较好的理解,那么对于我们的攻击,是否也可以这样做呢?
看看我们在:基于机器学习的攻击检测(一)中所举的例子:
- http://www.aaa.com/ccc/?id=1/**/aNd/**/1>0
- http://www.aaa.com/ccc/?search=
- http://www.aaa.com/ccc/?dict=../../../etc/passwd
我们使用万法归一的思想,这就是一个一个的文本啊!只不过不是 i am a boy这种人类语言而是计算机语言罢了,但是不管是人类语言还是计算机语言,他都就需要遵从一定的规则和规范,比如说一个url,它的完整语法应该是一个:
协议+域名+路径+端口+用户名/密码
来组成的
或者对于一个参数id 他的正常值是1,2,3,4这样的数字,突然多出来一个union select 1,那肯定是有问题的呀(或者说不符合一定规则的)
基于这个思路,我们将请求url单纯的当作一个文本内容,来进行二分类任务,也是完全可以的呀
或不多说,上代码
首先导入我们的常用库:
import os
import sys
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
#import urlparse
import urllib
from urllib.parse import urlparse
import math
from sklearn import preprocessing
from sklearn.utils import shuffle
import gensim
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense,Embedding
from keras.layers import LSTM
from gensim.models import Word2Vec
接下来,我们把标签单独提出来当作一个pandas.Seris保存:
def getlabel(x):
if x == 0:
return 0
elif x == 1:
return 1
然后就是lstm的数据预处理啦,一般来说我们带入lstm的数据肯定不能是i am a boy这种,这谁受得了2333
一般的处理方法叫做词嵌入技术(word embedding),包括n-gram,word2vec,doc2vec等都属于这种方法,他们的目的就是将文本信息变成数值特征向量
比如 一句话 i am a boy ,经过embedding之后应该形如:
注意每一行的x1,x2,x3,x4都是不一样的,他们可能是1*4的数值矩阵,也可能是1*n的
在代码中我们使用gensim库来进行word2vec的embedding
def getw2v(url_list,label_list):
stop = []
w2v_list = []
for i in range(0,url_list.size):
tmp = []
name = url_list[i]
for j in range(0,len(name)):
tmp.append(name[j])
w2v_list.append(tmp)
model = Word2Vec(w2v_list,min_count = 5)
model.wv.save_word2vec_format('word2vec.txt',binary=False)
label_vect = []
wv_vect = []
for i in range(0,url_list.size):
name = url_list[i]
tmp = []
vect = []
for j in range(0,len(name)):
if name[j] in stop:
continue
tmp.append(model[name[j]])
if j >= 49:
break
if len(tmp) < 50:
for k in range(0,50-len(tmp)):
tmp.append([0]*100)
vect = np.vstack((x for x in tmp))
wv_vect.append(vect)
label_vect.append(label_list[i])
wv_vect = np.array(wv_vect)
label_vect = np.array(label_vect)
return wv_vect,label_vect
上述代码将文本通过训练word2vec将出现的单个字母或字符表达成一个1*100维度的矩阵,并将结果存入txt文件
之后我们对每一个url请求,依次将其中的每一个单词对映成一个1*100的矩阵,当然,由于lstm需要输入定长的数据,因此对于每一个请求,我们值截取前50个字符构建矩阵,多余50的则舍弃这部分,对于不到50长度的url请求,通过补足相应个数的1*100的0矩阵来使其长度为50
接下来就是读取我们的数据集并作相应处理:
normal_data = pd.read_csv('normal.csv')
abnormal_data = pd.read_csv("risk.csv")
normal_data['label'] = normal_data['url'].map(lambda x:getlabel(0)).astype(int)
abnormal_data['label'] = abnormal_data['url'].map(lambda x:getlabel(1)).astype(int)
abnormal_data = abnormal_data.drop(['id','risk_type','request_time','http_status','http_user_agent','host','cookie_uid','source_ip','destination
train_data = pd.concat([normal_data,abnormal_data],axis = 0)
train_data = shuffle(train_data)
w2v_word_list,label_list = getw2v(train_data['url'].values,train_data['label'].values)
之后我们随心所欲地划分测试集和验证集
x_train = w2v_word_list[0:8000]
y_train = label_list[0:8000]
x_test = w2v_word_list[8000:]
y_test = label_list[8000:]
最后我们构建一个单层的lstm模型,包含128个神经元
dropout=0.2表明在每一次训练都会随机丢失20%的权重,这一方法一般用于防止过拟合,增加模型的泛化能力。我们训练50个epoch来看一看结果
model = Sequential()
model.add(LSTM(128,dropout=0.2,recurrent_dropout=0.2))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
print('training now......')
model.fit(x_train,y_train,nb_epoch=50,batch_size=32)
print('evalution now......')
score,acc = model.evaluate(x_test,y_test)
print(score,acc)
最终结果如下
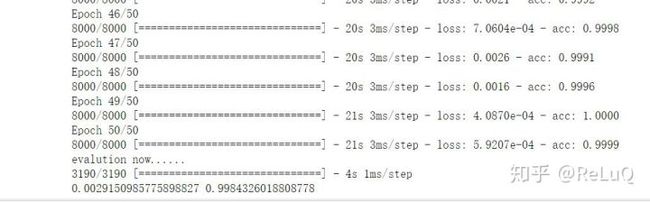
发布于昨天 01:48