并行设计模式:并行流水线与并行查找
流水线与指令重排
我们知道进程切换开销是很大的,CPU首先保存当前被中断进程现场,然后把系统堆栈指针保存到PCB中,接着去处理中断,选择下一个占用CPU的进程。引入线程的目的就是减少了系统的时空开销,因为现在多核处理器已经十分普遍,设想如果一个程序它只有一个线程,那么在一个双核处理器上运行该程序,那么同一时刻只有一个核在运行,另一个核就处于空闲状态,导致系统资源浪费。程序使用多线程,可以充分利用多核处理器,提高系统吞吐量和并发性,因为多线程发挥了多核CPU的优势,实现了真正的并行操作。
多线程并行执行虽然能提高效率,但是需要认真考虑,解决数据一致性的问题,即围绕原子性、可见性和有序性来保证多线程之间的合作。在这里,并行流水线中,我们重点关注的是有序性问题,在我们写代码的过程中,内心可能感觉,代码的执行顺序和行数顺序基本一样,由上到下依次执行。不过,JVM可能会在程序执行时,进行指令重排,即对现有指令的执行顺序进行重新排序,导致代码的执行顺序可能并不如程序员所想的那样依次执行。进行指令重排的原因,是为了提高CPU的效率,为什么这么说?假设指令是串行执行的,指令A是去存储器中读值,花费的时间比较多,假设用了20毫秒,那么排在指令A后面的指令B必须等待着20毫秒后,才能执行。但如果指令B执行的动作与指令A访问的值无关,且指令B也不会去访问存储器,只是在自己CPU的高速缓存中操作,那么就可以让指令B在等待指令A执行后,立刻执行,不用等待指令A的执行完成。流水线技术就是这样来的,利用每条指令可能访问或使用不同的硬件,调整指令的执行顺序来提高效率。
再举个明白点的例子:假设有以下指令:
LOAD R1,A;
LOAD R2,B;
ADD R3,R2,R1;
LOAD R4,C;
LOAD R5,D;
ADD R6,R5,R5;
指令load R1,A;把A的值读入到寄存器R1中,另一条指令load R2,B;把B的值读入到寄存器R2中,第三条指令是ADD R3,R2,R1;把寄存器R2和寄存器R1的值相加,然后读入到寄存器R3中,下同。由于第三条指令ADD R3,R2,R1;要等待寄存器R1和寄存器R2的值,导致下面的指令也要跟着一起等待(假设我们的代码是串行执行的),整段代码就慢了下来。可是我们看,下面的指令把C的值读入寄存器R3和把D的值读入寄存器R4,都不会对上面的ADD有影响,因为它们不会访问到寄存器R1到R3,所以,如果把指令重排,在ADD R3,R2,R1;指令执行等待后,接着执行C,D的值写入寄存器的指令,就能在可能发生等待的时候,去做其他的事情,不浪费等待的时间。
当然,指令重排不会总是发生的,它是有规则遵循的,具体大家可以自行查看“Happen-Before”规则,这篇日志不详细列出。
并行流水线
上面讲了一堆流水线和指令重排,我想表达的是,串行执行有时可能会浪费很多不必要的等待时间,如果把串行改成并行执行,就能节省很多时间,毕竟多核CPU早已成为趋势,能够胜任并发程序的执行工作。并行流水线就是一种并行模式,借鉴了流水线的方式,分工合作提升整体的效率。
来看个例子,假如程序要执行计算(A+B)/C-D,这个式子计算至少要分为三步:
- A+B;
- (A+B)/C;
- (A+B)/C-D;
假设代码只能串行执行,把整个计算过程放到一个线程上运算,可以看到,第一步A+B未完成,第二步就必须等待,等待第一步完成后,才去存储器读C的值出来与(A+B)做除法运算。同理第三步因为要等待第二步的结果,等待第二步完成后,再去读存储器D的值出来做减法运算,导致整个线程计算得很慢。如果我们参考流水线的方式,把这一条运算式子,分为三个线程去协同计算,线程A负责第一步计算A+B的值,得到结果后,传给线程B;线程B负责第二步取C的值出来,与(A+B)也就是线程A传来的结果做除法,得到的结果传给线程C;线程C显然要做的就是最后一步,取得D得值,然后把线程B发来的结果与D相减4s,得到最终结果。来看看代码实现:
package com.justin.parallelpipeline;
public class Data {
public double A, B, C, D;
public String resule;
public Data() {
}
public Data(double A, Double B, Double C, Double D) {
this.A = A;
this.B = B;
this.C = C;
this.D = D;
}
}
Data类数据,里面有A,B,C,D四个运算数和一个输出式子即结果的字符串。
package com.justin.parallelpipeline;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class AdditionThread implements Runnable {
//创建一个队列模拟接收从存储器读到值
public static BlockingQueue dataQueue = new LinkedBlockingQueue();
Data data = new Data();
public static final long startTime = System.currentTimeMillis();
public static boolean isRunning = true;
//加法运算
@Override
public void run() {
while(isRunning) {
try {
data = dataQueue.take(); //拿到数据
data.B = data.A + data.B; //把A+B的结果保存到变量B中
//把加法结果传到除法线程的队列中去
MultiplyThread.additionResultQueue.add(data);
} catch(InterruptedException e) {
e.printStackTrace();
}
}
}
}
在加法线程中,我们用一个BlockingQueue队列保存主线程传进来的Data数据,然后使用take()方法(还记得这个方法吧?就是当BlockingQueue队列为空时会进行线程等待。)从队列中拿出一个Data数据,把里面的double变量A和B相加,结果放到B总,然后把Data数据传到第二步,即除法线程中去。
package com.justin.parallelpipeline;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class MultiplyThread implements Runnable {
//创建一个队列存放加法线程传来的结果
public static BlockingQueue additionResultQueue = new LinkedBlockingQueue();
Data data = new Data();
public static boolean isRunning = true;
//除法运算
@Override
public void run() {
while(isRunning) {
try {
data = additionResultQueue.take();
data.C = data.B / data.C;
SubtractionThread.subtractionResultQueue.add(data);
} catch(InterruptedException e) {
e.printStackTrace();
}
}
}
}
除法线程类似,也需要一个BlockingQueue队列additionResultQueue来接收加法线程传过来的第一个结果,结果存放在了data.B变量中。接着除法线程要做的就是take()方法拿到这个数据,然后运算B/C(此时变量B的值是(A+B)),除法结果存放到变量C中,最后再传递到减法线程。
package com.justin.parallelpipeline;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class SubtractionThread implements Runnable {
//创建一个队列存放除法线程传来的结果
public static BlockingQueue subtractionResultQueue = new LinkedBlockingQueue();
Data data = new Data();
public static long endTime;
//减法运算
@Override
public void run() {
while(true) {
try {
data = subtractionResultQueue.take();
data.D = data.C - data.D;
System.out.println(data.resule + data.D);
//达到最大计算次数后,通知另外两个线程停止
if(data.A == 999) {
MultiplyThread.isRunning = false; //除法线程停止
AdditionThread.isRunning = false; //加法线程停止
endTime = System.currentTimeMillis() - AdditionThread.startTime;
System.out.println("consumeTime = " + endTime + "ms");
break;
}
} catch(InterruptedException e) {
e.printStackTrace();
}
}
}
}
减法线程,拿到data后,执行最后的减法运算,并把算式字符串result输出,本条式子运算完毕。第21行是特殊情况判断,假设所有算式都运算完了,那么就设置另外两个线程的停止标识符,同时自己break结束。
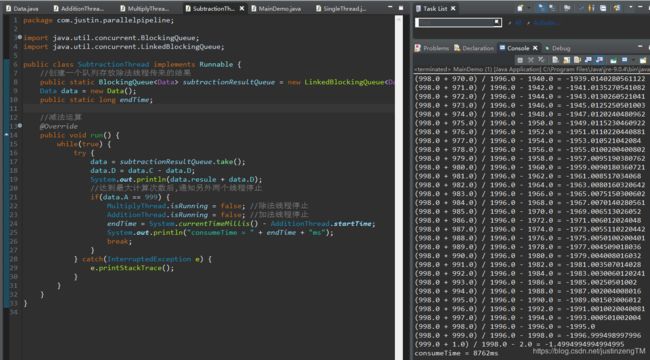
可以看到,多线程协同运算消耗时间8762毫秒,如果让单线程来做这件事情:
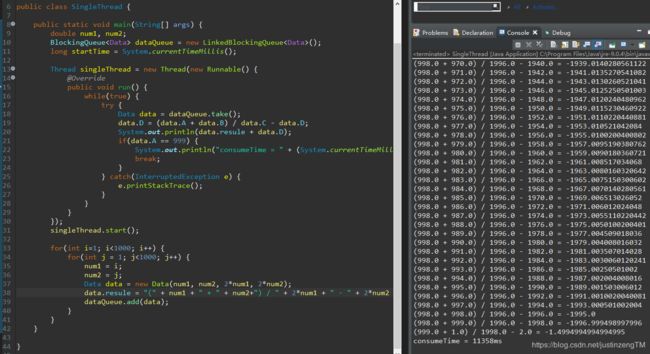
消耗时间11358毫秒。不过这个模拟并不准确,结果并不总是单线程比多线程慢的,因为线程要做的事情太简单了!这个例子只是显示设计并行流水线的模板,告诉你怎么把串行任务按照流水线方式分割成多线程协同合作执行。
并行查找
同样的并行思想,我们也可以用到查找方式上,试想假如我们要在一个无序的队列上进行顺序查找,使用单线程的话,我们要从头开始遍历整个数组。如果我们参考上面的并行方式修改这个串行执行,即我们可以把数组等分成n组,然后用n个线程分别对些数组查找,当其中一个线程找到要找到数据后,就可以停止。听着是不是感觉像分而治之?没错就是这种思想,来看看具体例子,如果用单线程做顺序查找:
package com.justin.parallelsearch;
import java.util.Random;
import java.util.Scanner;
public class SingleSearchThread {
public static void main(String[] args) {
int searchNum;
int[] arr = new int[100];
Random rd = new Random();
Scanner in = new Scanner(System.in);
System.out.println("数组元素:");
for(int i=1; i<=100; i++) {
arr[i-1] = rd.nextInt(1000);
System.out.print(arr[i-1] + " ");
if((i%10) == 0) {
System.out.print("\r\n");
}
}
System.out.print("\r\n请输入要查找的值:");
searchNum = in.nextInt();
//开始查找
for(int i=0; i那就只能从数组下标为0开始,一个一个搜索,直到arr.length。如果用多线程查找:
package com.justin.parallelsearch;
public class SearchMethod {
//顺序查找方法
public static int search(int startPosition, int endPosition, int searchNum) {
for(int i=startPosition; i用多线程的方式,每次查找时,线程都先检查下结果集result(在主线程中定义的AtomicInteger无锁安全整数类型)中是否存放了要找的元素的下标,如果有,表明其他线程已经找到用户要查找的元素了,那么自己就可以停止查找,并返回这个值。因为查找结果保存在AtomicInteger中,所以使用CAS操作来更新找到的元素下标到result中,如果CAS操作失败,表明有其他线程也找到了这个下标,并且率先设置成功,那么自己就停止操作,返回结果集即可。接着看查找线程:
package com.justin.parallelsearch;
import java.util.concurrent.Callable;
public class SearchThread implements Callable {
int startPosition, endPosition, searchNum;
//构造方法初始化
public SearchThread(int startPosition, int endPosition, int searchNum) {
this.startPosition = startPosition;
this.endPosition = endPosition;
this.searchNum = searchNum;
}
public Integer call() {
//调用顺序查找方法
int searchResult = SearchMethod.search(startPosition, endPosition, searchNum);
return searchResult; //返回搜索结果
}
}
因为查找线程需要返回值,所以不适用Runnable接口,而是使用Callable接口。
package com.justin.parallelsearch;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.Scanner;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.atomic.AtomicInteger;
public class MainSearchDemo {
public static int[] arr;
public static AtomicInteger result = new AtomicInteger(); //存放查找结果
public static void main(String[] args) throws InterruptedException, ExecutionException {
int startPosition, endPosition, searchNum;
arr = new int[100];
int arrayLength = arr.length / 5; //按照线程数等分数组
Scanner in = new Scanner(System.in);
Random rd = new Random();
ExecutorService threadPool = Executors.newCachedThreadPool(); //线程池
result.set(-1); // 初始结果集中下标初始化为-1
System.out.println("数组元素:");
for(int i=1; i<=100; i++) {
arr[i-1] = rd.nextInt(1000);
System.out.print(arr[i-1] + " ");
if((i%10) == 0) {
System.out.print("\r\n");
}
}
List> resultQueue = new ArrayList>();
System.out.print("\r\n请输入要查找的值:");
searchNum = in.nextInt();
for(startPosition=0; startPosition arr.length) {
//如果末尾位置越界
endPosition = arr.length;
}
//查找
SearchThread searchThread = new SearchThread(startPosition, endPosition, searchNum);
resultQueue.add(threadPool.submit(searchThread));
}
in.close();
}
}
主函数中,使用5个线程来对数组做查找,所以第20行arrayLength变量是等分数组的长度,第25行初始化结果集为-1,当某一线程查找成功后,就把对应的下标存放到结果集中。第36行,由于查找线程使用的是Callable接口,Callable接口返回类型是Future,所以创建一个List集合接收返回Future类型的结果。最后第43行特殊情况判断,如果最后一个线程的查找末尾位置下标参数越界了,就直接把数组的长度做为最后一个线程的查找末尾位置下。
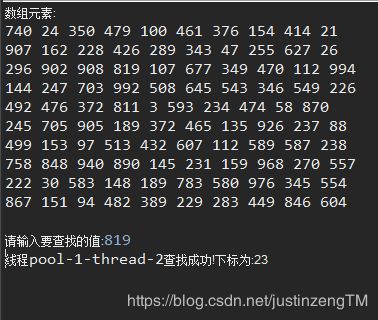
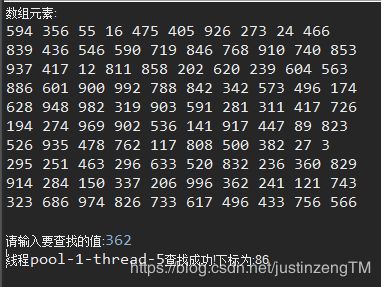
可以看到,不同部分的数组会由不同的线程来查找。
完整实现已上传GitHub:
https://github.com/justinzengtm/Java-Multithreading