Learnable pooling with Context Gating for video classification
Learnable pooling with Context Gating for video classification
paper:https://arxiv.org/pdf/1706.06905.pdf
introduction
我们将youtobe-8m视频理解的问题定义为“temporal feature aggregation”。当前时间维度的增强方案有:max & average pooling,VLAD,LSTM,GRU等;但训练循环神经网络往往需要大量的数据,并且当前未有人证明,这些模型是否适用于视频特征,我们也尝试用循环神经网络训练temporally-ordered and randomly-ordered video frames, 但二者结果相似,所以RNN方案可能并不适用该问题。(这点很有意思,曾在别的paper中也看到这样的验证,当将RNN应用于hige-level图像特征时,是否具有时序性似乎并不重要)。
还有一些传统的无序feature聚类方案,如Bag-of-visual-words,Vector of Locally aggregated Descriptors (VLAD)or Fisher Vectors。
本文我们的contribution:1)提出一种新的结构,CG module,来聚合video & audio 特征; 2)提出context gating later,非线性层,建立特征之间的interdependencies;
CG module 介绍
1)整体网络结构
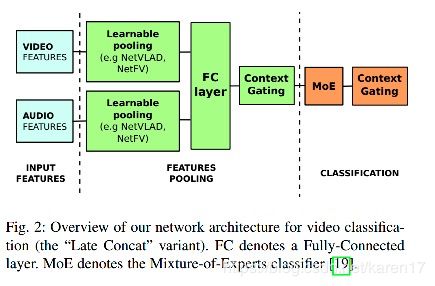
2)context gating(CG)module
![]()
将输入特征x映射为y,其中σ 是sigmoid, ◦是点乘,σ学出来的权重在0-1之间;x是n维,w是n*n,b是n维度。(可以理解为一个卷积层去学特征x,然后通过sigmoid将学出来每个点的激活值映射到0-1之间)
为什么要将x转变到y? a)我们希望在输入特征的激活值中引入非线性;2)通过self-gating mechanism为输入特征引入强度区分
两次使用CG module:a)在classifaction 之前;b)在classficatio之后(to capture the prior structure of the output label space?)也就是在网络结构图中MoE前后有两个CG module。
3)与residual connetction的关系
普通的residual连接:
![]()
residual求导:
![]()
同样的CG-module的求导:
![]()
GC module中x的导数前面有个权重,如果这个权重接近于1时,CG的导数很像residual导数。
4)Motivation for Context Gating
我们的目标:为一个视频预测一个标签,但这个标签只与一部分事件or行为有关,所以为了抑制无关的label我们引入CG-module,来re-weight 输入特征和输出labels(有点像se给不同channel打分,这里用CG-module给不同feature打分,再把这些打分后的feature 聚合在一起进行分类)
label pooling methods
如何聚合sequential feature? 以往的方法:LSTM or GRU
但这里我们更加关注non-recurrent 聚合方案,为什么?a)RNN方案不能并行结算;b)没有方法证明一定要把aggregation problem当做sequence modeling problem 来处理。后续我们的实验中也表明,shuffle the frames之后模型性能并没有变化,所以是否考虑用sequence的方案做并不重要。我们采用的三种aggregation 方案:NetVLAD,Fisher Vector 和 Bag-of-visual-Words。
paper中并木有对这种pooling方案进行优化,关键还是在提出的CG module。
experiment
数据集:youtube-8m
细节:在每个video中随机选择N个feature,N是固定的
1)验证方法有效性
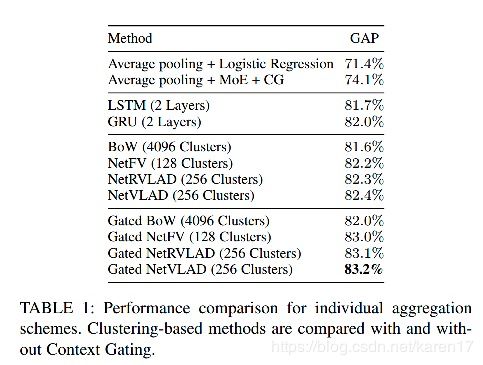
结论:a)较average pooling而言,性能提升明显;b)比GRU or LSTM这样的特征融合方案好
2)CG module 有效性
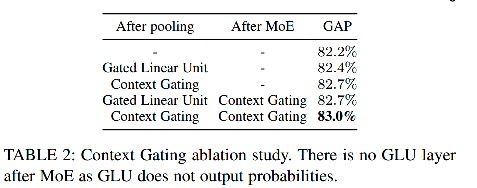
个人想法
提出的CG-module 有点像SE-Net,作用在时间维度的se-net,学习不同帧之间的重要性关系。
不过为什么CG-module不直接接在feature后面呢?而是接在了pooling层后面