TDengine数据库-TAOS DATA-涛思数据
1. 特征
1.1. 特点
- TDengine将表中数据按时间主键排序存储且其列式存储的组织形式都使TDengine在写入、查询以及压缩方面拥有非常大的优势。
- 取消事务及compact
- 非Bigtable LSM-tree levelDB
- 压缩算法
simple8B zig-zag编码 时间戳&Integer、
RLE(run length encoding)\1bit boolean、
LZ4 内存 String、
delta-of-delta - tags与data分开存储
- 元数据中数据顺序添加,删除只是添加删除记录
1.1.1. 标签
标签总数不能超过6个
创建超级表
CREATE TABLE
与创建表的SQL语法相似。但需指定TAGS字段的名称和类型。
说明:
TAGS列总长度不能超过512 bytes;
TAGS列的数据类型不能是timestamp和nchar类型;
TAGS列名不能与其他列名相同;
TAGS列名不能为预留关键字.
1.1.2. 缓存
sessionsPerVnode x 2 ≤ cacheNumOfBlocks
你可以通过函数last快速获取一张表或一张超级表的最后一条记录,这样很便于在大屏显示各设备的实时状态或采集值。例如:
select last_row(degree) from thermometer where location=‘beijing’;
该SQL语句将获取所有位于北京的传感器最后记录的温度值。
TDengine服务主要包含两大模块:管理节点模块(MGMT) 和 数据节点模块(DNODE)
为了更高效地利用资源,以及方便将来进行水平扩展,TDengine内部对数据节点进行了虚拟化,引入了虚拟节点(virtual node, 简称vnode)的概念,作为存储、资源分配以及数据备份的单元。每一个表只存在于一个vnode中,vnode资源隔离,在磁盘上有独立的存储目录,并且都有缓存。
TDengine写入数据的流程,最重要的是预写日志算法,接受到客户端的数据后会先将数据写入到预写日志WAL中,然后定时或者当数据量达到一定规模后才会写入到磁盘中。
涛思数据认为物联网数据是时序的、结构化的、不会更新的,而且流量是平稳的,查询分析一定是在一个时间段进行的
TDengine中写入的数据在硬盘上是按时间维度进行分片的。同一个vnode中的表在同一时间范围内的数据都存放在同一文件组中。这一数据分片方式可以大大简化数据在时间维度的查询,提高查询速度。在默认配置下,硬盘上的每个数据文件存放10天数据。用户可根据需要修改系统配置参数daysPerFile进行个性化配置。
表中的数据都有保存时间,一旦超过保存时间(缺省是3650天),数据将被系统自动删除。您可以通过系统配置参数daysToKeep进行个性化设置。
时序时空数据库 ( Time Series and Spatial-Temporal Database , 简称 TSDB) 是一种集时序数据高效读写,压缩存储,实时计算能力为一体的数据库服务,可广泛应用于物联网和互联网领域,实现对设备及业务服务的实时监控,实时预测告警。
RRD (Round Robin Database)数据库是一个环形的数据库,数据库由一个固定大小的数据文件来存放数据,此数据库不会像传统数据库一样为随着数据的增多而文件的大小也在增加,RRD在创建好后其文件大小就固定,可以把它想像成一个圆,圆的众多直径把圆划分成一个个扇形,每个扇形就是可以存数据的槽位,每个槽位上被打上了一个时间戳,在圆心上有一个指针,随着时间的流逝,取回数据后,指针会负责把数据填充在相应的槽位上,当指针转了360度后,最开始的数据就会被覆盖,就这样RRD循环填充着数据。
2. 索引
就时序数据库来讲,对高维序列的索引是逃不开的一件事,通常大家为了快,会选择把对序列的索引放到内存中,正如早期influxdb的做法,tdengine本质上也是这种做法;
但是这么做会导致内存的无限膨胀,终有一天会撑不住,除非能保证序列的维度被控制在有限的个数内,然而这一假设在机器监控场景是不现实的,单拿podid作为一个维度就足够喝一壶了;
所以后来influxdb做了倒排索引,并存储在磁盘上;
在tdengine的数据模型中,有一个值得注意的点:
- 如果序列有多组采集量,每一组的采集频次是不一样的,需要对同一个序列建多张表
这个点可以大大减少存储空间的消耗,使得存储数据的时候,所有的列只需要共用一个时间戳序列,比如
cpu load5=123, load10=456 <Timstamp>
load5和load10只需要共用一个时间戳,influxdb因为没有这个假设,所以数据在按列存储的时候每个值都需要附带一个64位int的时间戳,使得存储空间基本两倍于tdengine。
3. 存储模型
虚拟节点(vnode)
vnode是虚拟节点的简称,一个物理数据节点被虚拟成多个虚拟节点
每个虚拟节点有各自独享的缓冲、磁盘等资源
不同vnode之间资源隔离
一个表只能存到一个vnode中
一个vnode只能属于一个数据库
一个数据库可以包含一个到多个vnode
数据文件的组织方式
在一个vnode中,所有表在同一个时间范围内的数据是存到同一个文件组中的,比如v0f1804*文件存储了若干个表的某个时间段的数据。
TDengine的数据文件默认存放在 /var/lib/taos/data/ 下。而 /var/lib/taos/tsdb/ 文件夹下存放了vnode的信息、vnode中表的信息以及数据文件的链接等。这个地方官网应该是写反了
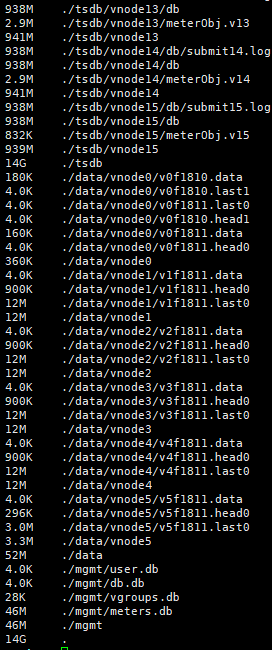
一个vnode有一个元数据文件,其中存储了这个vnode的相关元数据;
/var/lib/taos/
+--tsdb/
| +--vnode0
| +--meterObj.v0
| +--db/
| +--v0f1804.head->/var/lib/taos/data/vnode0/v0f1804.head1
| +--v0f1804.data->/var/lib/taos/data/vnode0/v0f1804.data
| +--v0f1804.last->/var/lib/taos/data/vnode0/v0f1804.last1
| +--v0f1805.head->/var/lib/taos/data/vnode0/v0f1805.head1
| +--v0f1805.data->/var/lib/taos/data/vnode0/v0f1805.data
| +--v0f1805.last->/var/lib/taos/data/vnode0/v0f1805.last1
| :
+--data/
+--vnode0/
+--v0f1804.head1
+--v0f1804.data
+--v0f1804.last1
+--v0f1805.head1
+--v0f1805.data
+--v0f1805.last1
:
在数据文件中,数据是按照数据块存储的,每个数据块只包含一张表的数据;
每张表的数据是按列存储的,从而使得达到最大的压缩效果。
每一个文件组都由三个文件:head,data,last,这三个文件的作用如下
- head文件存储data文件数据块的索引信息,可以通过head文件迅速找到每个表的偏移量,结构如下
<文件开始>
[文件头]
[表1偏移量]
[表2偏移量]
…
[表N偏移量]
[表1数据索引]
[表2数据索引]
…
[表N数据索引]
<文件结尾>
其中数据索引的结构如下:
[索引块信息]
[数据块1索引]
[数据块2索引]
…
[数据块N索引]
数据块索引中记录了数据块存放的文件名称,数据块起始地址偏移量等信息
- data文件,即数据文件
存放了真实的数据,格式如下
<文件开始>
[文件头]
[数据块1]
[数据块2]
…
[数据块N]
<文件结尾>
其中数据块格式为
[列1信息]
[列2信息]
…
[列N信息]
[列1数据]
[列2数据]
…
[列N数据]
3.1. 针对一个具体的查询语句,其流程是这样的
首先从meterObj文件拿到查询涉及的表的信息(具体是哪个head文件)
从head文件中拿到对应表的索引信息
从data文件中拿到对应的列的索引信息,并根据数据块的位置读取数据
需要注意的是,数据块中不仅记录原始信息,还会记录该数据块中数据的各种统计值,比如最大值、最小值,sum,count等。
以上就是数据存储的设计,可以看到这种设计中包含了一些重要的假设:
两个相邻数据点之间的时间间隔是固定的
数据是不能缺失的,必须按序写入
这两个假设会有使用场景上的限制,比如针对第二个假设,某些延迟的数据是无法写入系统的;
虽然有一些场景上的限制,但是这两个假设却能带来巨大的性能提升
存储空间的大大节省
CPU使用率得到大大减少,写入不必再进行compact,也不必再进行排序
第一个好处的原因在于,数据等时间间隔(也就是一个等差数列),使得时间戳的存储可以借助于delta of delta,无论多长的时间戳序列只需要记录一个初始值加上一个delta就可以了,这种方式使得时间戳的存储空间成百上千倍倍的减少。
之前在对influxdb写入进行profilling的时候曾发现,compact过程和排序过程大概能占用写入CPU的20%左右,如果连带上compact和排序引起的gc,这一比例会更高。
除此之外,数据块中记录的统计值是造成聚合查询性能140倍的重要原因。
3.2. 查询处理
以上是tdengine的查询过程,主要包括三个步骤
client App解析sql语句,然后从管理节点拿到对应表的数据所在的节点
client App发出请求到这些数据节点,然后数据节点根据请求吐出数据到client App
client App根据返回的数据进行数据的合并
可以看到上述过程client App作用巨大,尤其是最后的数据合并操作对某些聚合函数(求中位数,求标准差等)是一个非常耗费内存和CPU的操作,这部分操作转到一个客户机上确实会大大减少数据存储节点的计算压力,也不失为一种好方法,关键还是要看客户买不买账。
REST查询方式
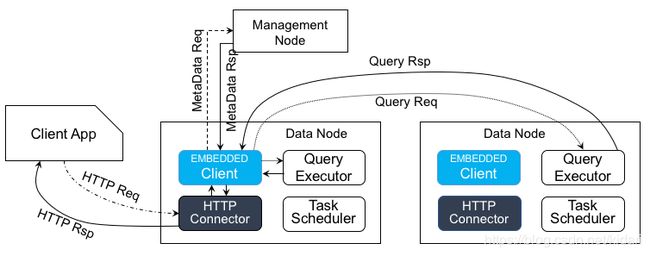
可能是为了减少用户的使用成本和增加用户使用的便利性,tdengine提供了REST的查询方式,上图即为REST查询方式的流程图。
这种查询方式将普通查询处理流程中本来由client App处理的过程转移到了数据节点中,所以数据节点其实即负责读又负责写。
所以压测报告中到底是使用的哪种查询方式呢?要知道InfluxDB和其他一些时序数据库并没有将数据合并这种重操作都转移到客户端来进行操作的。
3.3. 集群设计
tdengine在集群设计上,除了之前提到的虚拟节点(vnode)和管理节点,还有虚拟节点组(vnode group)的概念,用来支持数据副本的概念,每个vnode group包含若干分布在不同机器上的vnode,vnode之间互为备份。
在数据分区上,tdengine认为单个表的数据只能存储在一个vnode上,并且是按照时间区间分别存储在不同的数据块上,这就已经够了,因为即使一个设备一秒发出16Bytes的数据,一年产生的数据也不到0.5G,一个vnode完全能够处理;简言之tdengine通过数据模型的划分(超级表+数据表)将最小处理粒(表)限定在一个vnode能够处理的范围内,从而避免数据分区。
负载均衡通过dnode汇报心跳到管理节点的方式,由管理节点全局管理负载均衡。
上述的集群管理设计中也有一个重要假设:设备发送数据的频率在秒级别,按照一秒的频率一年的数据是0.5G,如果按照毫秒的话就是500G。
4. 可能存在的问题
-
表的数量太多的问题
由于每个序列都是一个单独的表,尤其当一个序列中存在两个收集频率不一致的列的时候,tdengine都必须创建两张表来分别存储这两列;
一方面使用方式上不便利,另一方面如此大量的数据表的元信息存储在内存中,将会导致管理节点内存资源紧张。 -
scheme需要预先定义
-
普通查询需要在client端进行数据聚合等操作
-
Tag支撑与管理
-
最多支持6个Tag,如果想要支持更多就要重新源码编译
-
超级表STable对Tag组合的索引是全内存的,终将会遇到瓶颈的,InfluxDB已经走过这条路了,从之前的全内存到后面的tsi
-
超级表STable对Tag组合的索引仅仅是对第一个Tag作为key来构建一个skiplist,也就是说当你的查询用到第一个tag时可以利用下上述索引,当你的查询没用到第一个tag时,那就是暴力全扫,所以这种在Tag组合数过多的时候过滤查询能力还是很有限的。而像其他时序数据库InfluxDB、Druid都在写入过程中针对Tag组合构建了倒排索引来应对任意维度的过滤,写入性能比TDengine自然就会差一些
-
对于不再使用的Tag组合的过期目前也是个麻烦的事情
- 不支持乱序写入
- 每张表会记录该表目前写入的最大时间,一旦后续的写入时间小于该时间则不允许写入。假如你不小心向某张表写入2021-07-24 00:00:00时间的数据,那么该时间之前的数据都无法写入了
这样做带来的好处,简化了写入过程,写入过程永远是append操作。举个简单例子,比如用数组来存放内存数据,数组中的数据是按时间排序的,如果后来的数据的时间不是递增,那么就需要将数据插入到数组中间的某个位置,并且需要将该位置之后的数据全部后移。假如后来的数据的时间都是递增的,那么直接往数组的最后面放即可,所以不支持乱序写入即以牺牲用户使用为代价来简化写入过程提高写入性能
不支持乱序写入还省去的一个麻烦就是:LSM中常见的compact。如果允许乱序写入,那么就会存在2个文件中时间范围是有重叠的,那么就需要像RocksDB那样来进行compact来消灭重叠,进而减少查询时要查询的文件个数,所以你就会发现HBase、RocksDB、InfluxDB等等辛辛苦苦设计的compact在TDengine中基本不存在
-
求topN的group
order by只能对时间、以及tag进行排序。top或者bottom只能对某个field求topN
时序领域非常常见的topN的group,比如求CPU利用率最大的3台机器,目前也无法满足 -
downsampling和aggregation
downsampling:将同一根时间线上1s粒度的数据聚合成10s粒度的数据
aggregation:将同一时刻多根时间线聚合成1根时间线
比如每个appId有多台机器,每台机器每秒都会记录该机器的连接数,目前想画出每个appId的总连接数的曲线
假如使用标准SQL则可能表示如下:
select sum(avg_host_conn),appid,new_time from (
select avg(connection) as avg_host_conn,
appid,host,time/10 as new_time
from t1 group by appid,host,time/10
) as t2 group by appid, new_time
内部的子查询会先将每个appid的host 10s内的connection求平均值,即downsampling,外部的查询将每个appid下的host的上述平均值求和,即aggregation
由于这类需求在时序查询中太常见了,使用上述SQL书写非常麻烦,有些系统就通过函数嵌套的方式来简化这类查询的书写
- 目前TDengine的聚合函数要么只能是downsampling要么只能是aggregation,也不支持子查询,那么是无法满足上述需求的
-
查询聚合架构
查询分2阶段:第一阶段请求管理节点,获取符合tag过滤的所有表的meta信息(包含每个表在哪个数据节点上),假如满足条件的表有上百万个,这个阶段的查询基本吃不消,第二阶段向数据节点查询聚合每个表的数据,返回给客户端,客户端再做最终的聚合。
这种查询方案终究还是会面临客户端聚合瓶颈的,还是要上多机协调的分布式查询方案比如类似Presto、Impala等等 -
物联网有一个很重要的指标就是实时状态,以下场景是很常见的且TDengine不具备的
-
实时状态筛选
建议增加功能:STABLE查询,条件语句中能支持LAST函数,比如:
1) 筛选离线设备(24小时未发过数据)
SELECT TBNAME,tb_tags FROM stable WHERE LAST(ts) < now - 24h
2) 筛选实时状态为1的设备
SELECT TBNAME,tb_tag FROM stable WHERE LAST(stat) =1 -
实时状态告警
建议在订阅中增加对STABLE的订阅,比如
STABLE 中任意表LAST(stat) >1 -> tbname
SELECT LAST(*) FROM tbname -> publish
SELECT TBNAME,tb_tags FROM stable WHERE LAST(ts) < now - 24h
2) 筛选实时状态为1的设备
SELECT TBNAME,tb_tag FROM stable WHERE LAST(stat) =1
- 实时状态告警
建议在订阅中增加对STABLE的订阅,比如
STABLE 中任意表LAST(stat) >1 -> tbname
SELECT LAST(*) FROM tbname -> publish
- 现在按照时间区间聚合还无法做到自然年、自然月的精确匹配,后面我们修复这个问题。
- 不同列之间的查询条件不支持 or ,所有的 or 系统自动默认为 and 但是并不给出提示。后续版本会支持or的操作。同一个(普通)列(非标签列)内部也不支持 or 的过滤方式。